![]()
PyTorch 速查表¶
PyTorch 中一些最常用的命令/设置。
注意: 获取 PyTorch 特定函数和用例帮助的最佳方式之一是搜索“pytorch 如何构建卷积神经网络”或“pytorch 变换器层”或“pytorch 损失函数”。我经常这样做。
导入¶
你可以通过PyTorch 安装页面在不同平台上安装 PyTorch。
import torch
# Check the version
print(f"PyTorch version: {torch.__version__}")
PyTorch version: 1.13.1
# Can also import the common abbreviation "nn" for "Neural Networks"
from torch import nn
# Almost everything in PyTorch is called a "Module" (you build neural networks by stacking together Modules)
this_is_a_module = nn.Linear(in_features=1,
out_features=1)
print(type(this_is_a_module))
<class 'torch.nn.modules.linear.Linear'>
数据导入¶
由于机器学习的大部分工作是发现数据中的模式,因此了解如何在 PyTorch 中处理数据集是很有必要的。
# Import PyTorch Dataset (you can store your data here) and DataLoader (you can load your data here)
from torch.utils.data import Dataset, DataLoader
创建张量¶
PyTorch 的主要用途之一是用于加速深度学习计算。
而深度学习通常涉及对大型张量(庞大、多维的数字集合)的操作。
PyTorch 提供了多种创建张量的方法。
注意: 关于使用 PyTorch 创建张量的更全面概述,请参阅 00. PyTorch 基础。
# Create a single number tensor (scalar)
scalar = torch.tensor(7)
# Create a random tensor
random_tensor = torch.rand(size=(3, 4)) # this will create a tensor of size 3x4 but you can manipulate the shape how you want
# Multiply two random tensors
random_tensor_1 = torch.rand(size=(3, 4))
random_tensor_2 = torch.rand(size=(3, 4))
random_tensor_3 = random_tensor_1 * random_tensor_2 # PyTorch has support for most math operators in Python (+, *, -, /)
领域库¶
根据您正在处理的具体问题,PyTorch 提供了几个领域库。
- TorchVision — PyTorch 的计算机视觉库。
- TorchText — PyTorch 内置的文本领域库。
- TorchAudio — PyTorch 的音频领域库。
- TorchRec — PyTorch 最新的内置领域库,用于通过深度学习驱动推荐引擎。
计算机视觉¶
注意: 有关 PyTorch 中计算机视觉的深入概述,请参阅 03. PyTorch 计算机视觉。
# Base computer vision library
import torchvision
# Other components of TorchVision (premade datasets, pretrained models and image transforms)
from torchvision import datasets, models, transforms
文本与自然语言处理(NLP)¶
# Base text and natural language processing library
import torchtext
# Other components of TorchText (premade datasets, pretrained models and text transforms)
from torchtext import datasets, models, transforms
音频与语音¶
# Base audio and speech processing library
import torchaudio
# Other components of TorchAudio (premade datasets, pretrained models and text transforms)
from torchaudio import datasets, models, transforms
推荐系统¶
注意: 该库目前处于测试版本,请参阅 GitHub 页面进行安装。
# # Base recommendation system library
# import torchrec
# # Other components of TorchRec
# from torchrec import datasets, models
设备无关代码(使用 PyTorch 在 CPU、GPU 或 MPS 上运行)¶
深度学习的大部分工作涉及对张量进行计算。
与 CPU(中央处理单元)相比,在 GPU(图形处理单元,通常来自 NVIDIA)上进行张量计算通常会快得多。
MPS 代表 "Metal Performance Shader",这是 Apple 的 GPU(如 M1、M1 Pro、M2 等)。
建议在您可用的最快的硬件上进行训练,通常的优先顺序是:NVIDIA GPU("cuda")> MPS 设备("mps")> CPU("cpu")。
- 关于如何让 PyTorch 在 NVIDIA GPU(使用 CUDA)上运行,请参阅 00. PyTorch 基础部分 2:让 PyTorch 在 GPU 上运行。
- 关于使用 MPS 后端运行 PyTorch(在 Mac GPU 上运行 PyTorch)的更多信息,请参阅 PyTorch 文档。
注意: 建议在开始工作流程时设置设备无关代码。
# Setup device-agnostic code
if torch.cuda.is_available():
device = "cuda" # NVIDIA GPU
elif torch.backends.mps.is_available():
device = "mps" # Apple GPU
else:
device = "cpu" # Defaults to CPU if NVIDIA GPU/Apple GPU aren't available
print(f"Using device: {device}")
Using device: mps
将张量发送到目标设备¶
你可以通过 .to("device_name") 方法将 PyTorch 中的对象(模型和张量)移动到不同的设备上。
# Create a tensor
x = torch.tensor([1, 2, 3])
print(x.device) # defaults to CPU
# Send tensor to target device
x = x.to(device)
print(x.device)
cpu mps:0
设置随机种子¶
在机器学习和深度学习中,很多情况下需要从张量中获取随机数,然后对这些随机数进行处理,以发现或表示真实数据中的模式。
然而,有时你希望这种随机性是“可复现”的。
为此,你可以设置随机种子,更多信息请参见可复现性(试图消除随机性)。
import torch
# Set the random seed (you can set this to any number you like, it will "flavour"
# the randomness with that number.
torch.manual_seed(42)
# Create two random tensors
random_tensor_A = torch.rand(3, 4)
torch.manual_seed(42) # set the seed again (try commenting this out and see what happens)
random_tensor_B = torch.rand(3, 4)
print(f"Tensor A:\n{random_tensor_A}\n")
print(f"Tensor B:\n{random_tensor_B}\n")
print(f"Does Tensor A equal Tensor B? (anywhere)")
random_tensor_A == random_tensor_B
Tensor A:
tensor([[0.8823, 0.9150, 0.3829, 0.9593],
[0.3904, 0.6009, 0.2566, 0.7936],
[0.9408, 0.1332, 0.9346, 0.5936]])
Tensor B:
tensor([[0.8823, 0.9150, 0.3829, 0.9593],
[0.3904, 0.6009, 0.2566, 0.7936],
[0.9408, 0.1332, 0.9346, 0.5936]])
Does Tensor A equal Tensor B? (anywhere)
tensor([[True, True, True, True],
[True, True, True, True],
[True, True, True, True]])
你也可以在GPU(CUDA设备)上设置随机种子。
# Set random seed on GPU
torch.cuda.manual_seed(42)
神经网络¶
PyTorch 提供了一个非常全面的预构建神经网络组件库(在 PyTorch 生态系统中,这些组件通常被称为“模块”)。
从基本层面来看,神经网络是由一系列层组成的堆栈。每一层对输入执行某种操作并产生输出。
这些层如何堆叠在一起将取决于你正在解决的问题。
机器学习领域最活跃的研究领域之一是如何将神经网络层堆叠在一起(对此的最佳答案不断变化)。
PyTorch 中绝大多数神经网络组件都包含在 torch.nn 包 中(nn 是 neural networks 的缩写)。
from torch import nn
# Create a linear layer with 10 in features and out features
linear_layer = nn.Linear(in_features=10,
out_features=10)
# Create an Identity layer
identity_layer = nn.Identity()
卷积层(用于构建卷积神经网络或CNN)¶
PyTorch 提供了多种内置的卷积层。
卷积层的命名通常遵循 torch.nn.ConvXd 的格式,其中 X 可以是 1、2 或 3。
X 的值表示卷积操作将涉及的维度数量,例如,1 表示单维文本,2 表示二维图像(高度 x 宽度),3 表示三维对象,如视频(视频被视为一系列具有时间维度的图像,高度 x 宽度 x 时间)。
注意: 你可以在03. PyTorch 计算机视觉部分 7.2:构建卷积神经网络(CNN)中查看更多关于使用 PyTorch 构建计算机视觉卷积神经网络的内容。
# Create a Conv1d layer (often used for text with a singular dimension)
conv1d = nn.Conv1d(in_channels=1,
out_channels=10,
kernel_size=3)
# Create a Conv2d layer (often used for images with Height x Width dimensions)
conv2d = nn.Conv2d(in_channels=3, # 3 channels for color images (red, green, blue)
out_channels=10,
kernel_size=3)
# Create a Conv3d layer (often used for video with Height x Width x Time dimensions)
conv3d = nn.Conv3d(in_channels=3,
out_channels=10,
kernel_size=3)
Transformer层(用于构建Transformer模型)¶
PyTorch内置了Transformer层,这些层在论文Attention Is All You Need中有详细描述。
使用内置的PyTorch Transformer层的好处是,得益于PyTorch的BetterTransformer,可能会带来潜在的速度提升。
注意: 你可以在08. PyTorch论文复现中看到如何使用PyTorch的内置Transformer层构建Vision Transformer。
# Create a Transformer model (model based on the paper "Attention Is All You Need" - https://arxiv.org/abs/1706.03762)
transformer_model = nn.Transformer()
# Create a single Transformer encoder cell
transformer_encoder = nn.TransformerEncoderLayer(d_model=768, # embedding dimension
nhead=12) # number of attention heads
# Stack together Transformer encoder cells
transformer_encoder_stack = nn.TransformerEncoder(encoder_layer=transformer_encoder, # from above
num_layers=6) # 6 Transformer encoders stacked on top of each other
# Create a single Transformer decoder cell
transformer_decoder = nn.TransformerDecoderLayer(d_model=768,
nhead=12)
# Stack together Transformer decoder cells
transformer_decoder_stack = nn.TransformerDecoder(decoder_layer=transformer_decoder, # from above
num_layers=6) # 6 Transformer decoders stacked on top of each other
循环层(用于构建循环神经网络或RNN)¶
PyTorch内置支持循环神经网络层,例如长短期记忆(LSTM)和门控循环单元(GRU)。
# Create a single LSTM cell
lstm_cell = nn.LSTMCell(input_size=10, # can adjust as necessary
hidden_size=10) # can adjust as necessary
# Stack together LSTM cells
lstm_stack = nn.LSTM(input_size=10,
hidden_size=10,
num_layers=3) # 3 single LSTM cells stacked on top of each other
# Create a single GRU cell
gru_cell = nn.GRUCell(input_size=10, # can adjust as necessary
hidden_size=10) # can adjust as necessary
# Stack together GRU cells
gru_stack = nn.GRU(input_size=10,
hidden_size=10,
num_layers=3) # 3 single GRU cells stacked on top of each other
激活函数¶
激活函数通常位于神经网络的层与层之间,为线性(直线)函数添加非线性(非直线)能力。
本质上,神经网络通常由大量的线性和非线性函数组成。
PyTorch 在 torch.nn 中内置了多种非线性激活函数。
其中一些最常见的包括:
nn.ReLU- 也称为修正线性单元)。nn.Sigmoid- 也称为Sigmoid 函数。nn.Softmax- 也称为Softmax 函数。
注意: 更多信息请参见 02. PyTorch 神经网络分类部分 6:非线性,缺失的一环。
# ReLU
relu = nn.ReLU()
# Sigmoid
sigmoid = nn.Sigmoid()
# Softmax
softmax = nn.Softmax()
损失函数¶
损失函数衡量你的模型有多错误。换句话说,它的预测与正确值相差多远。
理想情况下,通过训练、数据和优化函数,这个损失值会尽可能降低。
在 PyTorch(以及深度学习一般)中,损失函数也常被称为:准则、成本函数。
PyTorch 在 torch.nn 中内置了多种损失函数。
其中一些最常见的包括:
nn.L1Loss- 也称为 MAE 或平均绝对误差(这种损失常用于回归问题或预测数值,如房价)。nn.MSELoss- 也称为 L2Loss 或均方误差(这种损失常用于回归问题或预测数值,如房价)。nn.BCEWithLogitsLoss- 也称为二元交叉熵,这种损失函数常用于二元分类问题(将事物分类为是或否)。nn.CrossEntropyLoss- 这种损失函数常用于多类别分类问题(将事物分类为多个类别之一)。
# L1Loss
loss_fn = nn.L1Loss() # also known as MAE or mean absolute error
# MSELoss
loss_fn = nn.MSELoss() # also known as MSE or mean squared error
# Binary cross entropy (for binary classification problems)
loss_fn = nn.BCEWithLogitsLoss()
# Cross entropy (for multi-class classification problems)
loss_fn = nn.CrossEntropyLoss()
优化器¶
优化器的工作是调整神经网络的权重,以减少损失函数的值。
PyTorch 在 torch.optim 模块中内置了多种优化函数。
主要的优化器函数包括:
torch.optim.SGD(lr=0.1, params=model.parameters())- SGD,即随机梯度下降(lr表示“学习率”,即每次调整神经网络权重的倍数,小值 = 小调整,大值 = 大调整)。torch.optim.Adam(lr=0.001, params=model.parameters())- Adam 优化器(params表示“模型参数”,即在训练过程中希望优化函数优化的模型参数/权重)。
# Create a baseline model
model = nn.Transformer()
# SGD (stochastic gradient descent)
optimizer = torch.optim.SGD(lr=0.1, # set the learning rate (required)
params=model.parameters()) # tell the optimizer what parameters to optimize
# Create a baseline model
model = nn.Transformer()
# Adam optimizer
optimizer = torch.optim.Adam(lr=0.001, # set the learning rate (required)
params=model.parameters()) # tell the optimizer what parameters to optimize
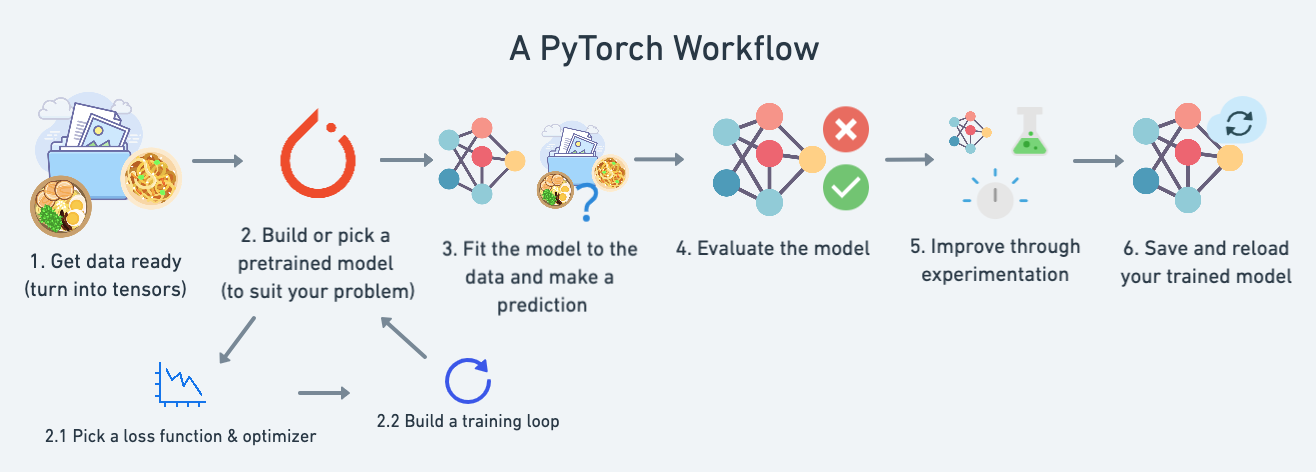
创建数据¶
# Create *known* parameters
weight = 0.7
bias = 0.3
# Create data
start = 0
end = 1
step = 0.02
X = torch.arange(start, end, step).unsqueeze(dim=1) # data
y = weight * X + bias # labels (want model to learn from data to predict these)
X[:10], y[:10]
(tensor([[0.0000],
[0.0200],
[0.0400],
[0.0600],
[0.0800],
[0.1000],
[0.1200],
[0.1400],
[0.1600],
[0.1800]]),
tensor([[0.3000],
[0.3140],
[0.3280],
[0.3420],
[0.3560],
[0.3700],
[0.3840],
[0.3980],
[0.4120],
[0.4260]]))
# Create train/test split
train_split = int(0.8 * len(X)) # 80% of data used for training set, 20% for testing
X_train, y_train = X[:train_split], y[:train_split]
X_test, y_test = X[train_split:], y[train_split:]
len(X_train), len(y_train), len(X_test), len(y_test)
(40, 40, 10, 10)
创建模型¶
在 PyTorch 中创建模型的两种主要方式:
- 子类化
torch.nn.Module- 代码较多但非常灵活,子类化torch.nn.Module的模型必须实现forward()方法。 - 使用
torch.nn.Sequential- 代码较少但灵活性较低。
from torch import nn
# Option 1 - subclass torch.nn.Module
class LinearRegressionModel(nn.Module):
def __init__(self):
super().__init__()
# Use nn.Linear() for creating the model parameters
self.linear_layer = nn.Linear(in_features=1,
out_features=1)
# Define the forward computation (input data x flows through nn.Linear())
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.linear_layer(x)
model_0 = LinearRegressionModel()
model_0, model_0.state_dict()
(LinearRegressionModel(
(linear_layer): Linear(in_features=1, out_features=1, bias=True)
),
OrderedDict([('linear_layer.weight', tensor([[0.5025]])),
('linear_layer.bias', tensor([-0.0722]))]))
现在让我们使用 torch.nn.Sequential 创建与上面相同的模型。
from torch import nn
# Option 2 - use torch.nn.Sequential
model_1 = torch.nn.Sequential(
nn.Linear(in_features=1,
out_features=1))
model_1, model_1.state_dict()
(Sequential(
(0): Linear(in_features=1, out_features=1, bias=True)
),
OrderedDict([('0.weight', tensor([[0.9905]])), ('0.bias', tensor([0.9053]))]))
设置损失函数和优化器¶
# Create loss function
loss_fn = nn.L1Loss()
# Create optimizer
optimizer = torch.optim.SGD(params=model_1.parameters(), # optimize newly created model's parameters
lr=0.01)
创建训练/测试循环¶
我们的目标是减少模型的损失(即模型的预测与实际数据之间的差异)。
如果我们的训练/测试循环实现正确,并且模型能够学习数据中的模式,那么训练和测试损失应该会下降。
以下是PyTorch训练循环的步骤:
torch.manual_seed(42)
# Set the number of epochs
epochs = 1000
# Put data on the available device
# Without this, an error will happen (not all data on target device)
X_train = X_train.to(device)
X_test = X_test.to(device)
y_train = y_train.to(device)
y_test = y_test.to(device)
# Put model on the available device
# With this, an error will happen (the model is not on target device)
model_1 = model_1.to(device)
for epoch in range(epochs):
### Training
model_1.train() # train mode is on by default after construction
# 1. Forward pass
y_pred = model_1(X_train)
# 2. Calculate loss
loss = loss_fn(y_pred, y_train)
# 3. Zero grad optimizer
optimizer.zero_grad()
# 4. Loss backward
loss.backward()
# 5. Step the optimizer
optimizer.step()
### Testing
model_1.eval() # put the model in evaluation mode for testing (inference)
# 1. Forward pass
with torch.inference_mode():
test_pred = model_1(X_test)
# 2. Calculate the loss
test_loss = loss_fn(test_pred, y_test)
if epoch % 100 == 0:
print(f"Epoch: {epoch} | Train loss: {loss} | Test loss: {test_loss}")
Epoch: 0 | Train loss: 0.008362661115825176 | Test loss: 0.005596190690994263 Epoch: 100 | Train loss: 0.008362661115825176 | Test loss: 0.005596190690994263 Epoch: 200 | Train loss: 0.008362661115825176 | Test loss: 0.005596190690994263 Epoch: 300 | Train loss: 0.008362661115825176 | Test loss: 0.005596190690994263 Epoch: 400 | Train loss: 0.008362661115825176 | Test loss: 0.005596190690994263 Epoch: 500 | Train loss: 0.008362661115825176 | Test loss: 0.005596190690994263 Epoch: 600 | Train loss: 0.008362661115825176 | Test loss: 0.005596190690994263 Epoch: 700 | Train loss: 0.008362661115825176 | Test loss: 0.005596190690994263 Epoch: 800 | Train loss: 0.008362661115825176 | Test loss: 0.005596190690994263 Epoch: 900 | Train loss: 0.008362661115825176 | Test loss: 0.005596190690994263
额外资源¶
上述列表并不详尽。
以下是一些了解更多信息的好地方:
- PyTorch 官方速查表。
- Zero to Mastery 学习 PyTorch 课程 - 一个全面且适合初学者的深入课程,从基础知识到将模型部署到现实世界中供他人使用。
- PyTorch 性能调优指南 - PyTorch 团队提供的关于如何调优 PyTorch 模型性能的资源。
- PyTorch 额外资源 - 一个精心挑选的有助于扩展 PyTorch 并了解更多深度学习工程方面的资源列表。
- Effective PyTorch by vahidk - 一个 GitHub 仓库,以直接的方式概述了 PyTorch 的一些主要功能。