快速入门 PyTorch 2.0 教程¶
import datetime
print(f"Notebook last updated: {datetime.datetime.now()}")
Notebook last updated: 2023-04-14 15:24:37.007274
30秒简介¶
PyTorch 2.0 发布了!
主要改进在于速度。
这一改进通过一行向后兼容的代码实现。
torch.compile()
换句话说,在你创建模型后,你可以将其传递给 torch.compile(),从而在新款GPU(例如NVIDIA RTX 40系列、A100、H100,GPU越新,速度提升越明显)上期待训练和推理速度的提升。
注意: PyTorch 2.0 中还有许多其他升级,不仅仅是
torch.compile(),但由于它是主要的改进,我们将重点介绍它。完整变更列表请参阅 PyTorch 2.0 发布说明。
我的旧PyTorch代码还能用吗?¶
是的,PyTorch 2.0 向后兼容。大部分变化是新增功能(新特性)。
这意味着如果你已经熟悉 PyTorch,比如通过 learnpytorch.io 课程,你可以立即开始使用 PyTorch 2.0。并且你的旧 PyTorch 代码仍然有效。
快速代码示例¶
在 PyTorch 2.0 之前¶
在 PyTorch 2.0 发布之前,深度学习框架的开发和使用经历了多个阶段,每个阶段都带来了新的特性和改进。以下是一些关键的发展里程碑:
PyTorch 1.0¶
PyTorch 1.0 是 PyTorch 发展历程中的一个重要版本,它引入了许多关键特性,使得深度学习模型的开发和部署更加高效和灵活。
- JIT 编译器:PyTorch 1.0 引入了 Just-In-Time (JIT) 编译器,可以将 Python 代码转换为 TorchScript,这是一种可以在没有 Python 依赖的环境中运行的中间表示形式。
- C++ 前端:除了 Python 接口,PyTorch 1.0 还提供了 C++ 前端,使得在性能敏感的应用中使用 PyTorch 成为可能。
- 分布式训练:PyTorch 1.0 增强了分布式训练功能,支持多节点训练,提高了大规模模型的训练效率。
PyTorch 0.4¶
PyTorch 0.4 版本在易用性和性能方面进行了多项改进。
- Tensor 和 Variable 合并:在之前的版本中,Tensor 和 Variable 是两个不同的概念,PyTorch 0.4 将它们合并为一个单一的 Tensor 类型,简化了代码。
- 零维张量:引入了零维张量(标量),使得处理标量值更加直观。
- Windows 支持:PyTorch 0.4 开始支持 Windows 平台,扩大了用户基础。
PyTorch 0.3¶
PyTorch 0.3 版本专注于提高性能和稳定性。
- 动态图优化:引入了更多的动态图优化技术,提高了模型的训练速度。
- 新的损失函数和优化器:增加了更多的损失函数和优化器,丰富了模型的选择。
PyTorch 0.2¶
PyTorch 0.2 版本在灵活性和易用性方面进行了改进。
- 高阶梯度:支持高阶梯度计算,使得更复杂的优化算法成为可能。
- 广播机制:引入了 NumPy 风格的广播机制,简化了张量操作。
PyTorch 0.1¶
PyTorch 0.1 是 PyTorch 的初始版本,奠定了框架的基础。
- 动态计算图:PyTorch 以其动态计算图特性而闻名,这使得模型的构建和调试更加直观和灵活。
- 自动微分:提供了自动微分功能,简化了梯度计算的过程。
这些版本的发展为 PyTorch 2.0 的推出奠定了坚实的基础,使得 PyTorch 成为深度学习领域最受欢迎的框架之一。
import torch
import torchvision
model = torchvision.models.resnet50() # note: this could be any model
### Train model ###
### Test model ###
在 PyTorch 2.0 之后¶
PyTorch 2.0 是一次重大的更新,带来了许多新特性和改进。以下是一些关键点:
- 性能提升:PyTorch 2.0 通过引入新的编译器和优化技术,显著提高了模型的训练和推理速度。
- 动态图与静态图的融合:PyTorch 2.0 在保持动态图灵活性的同时,引入了静态图的优化,使得用户可以在不牺牲易用性的前提下获得更好的性能。
- 更简洁的 API:PyTorch 2.0 对一些常用功能进行了重构,使得代码更加简洁和易读。
- 更好的分布式训练支持:PyTorch 2.0 提供了更强大的分布式训练工具,使得在多GPU和多节点环境下进行训练更加容易。
- 增强的自动微分功能:PyTorch 2.0 改进了自动微分机制,提供了更多的灵活性和控制能力。
以下是一个简单的示例,展示了如何在 PyTorch 2.0 中定义和训练一个模型:
import torch
import torch.nn as nn
import torch.optim as optim
# 定义一个简单的神经网络
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(784, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# 创建模型实例
model = SimpleNet()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 生成一些随机数据
inputs = torch.randn(64, 784)
labels = torch.randint(0, 10, (64,))
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Loss: {loss.item()}")
这个示例展示了如何定义一个简单的神经网络,并使用 PyTorch 2.0 进行前向传播、计算损失、反向传播和参数更新。
import torch
import torchvision
model = torchvision.models.resnet50() # note: this could be any model
compiled_model = torch.compile(model) # <- magic happens!
### Train model ### <- faster!
### Test model ### <- faster!
加速性能¶
好的,PyTorch 2.0 的重点是速度,它实际上有多快呢?
PyTorch 团队在来自 Hugging Face Transformers、timm(PyTorch 图像模型)和 TorchBench(从 GitHub 精选的一系列流行代码库)的 163 个开源模型上进行了测试。
这一点很重要,因为除非 PyTorch 2.0 在人们实际使用的模型上速度更快,否则它就不算更快。
通过混合使用 AMP(自动混合精度或 float16)训练和 float32 精度(更高精度需要更多计算),PyTorch 团队发现 torch.compile() 在 NVIDIA A100 GPU 上的训练提供了平均 43% 的加速。
或者在 timm 上提升 38%,在 TorchBench 上提升 76%,在 Hugging Face Transformers 上提升 52%。
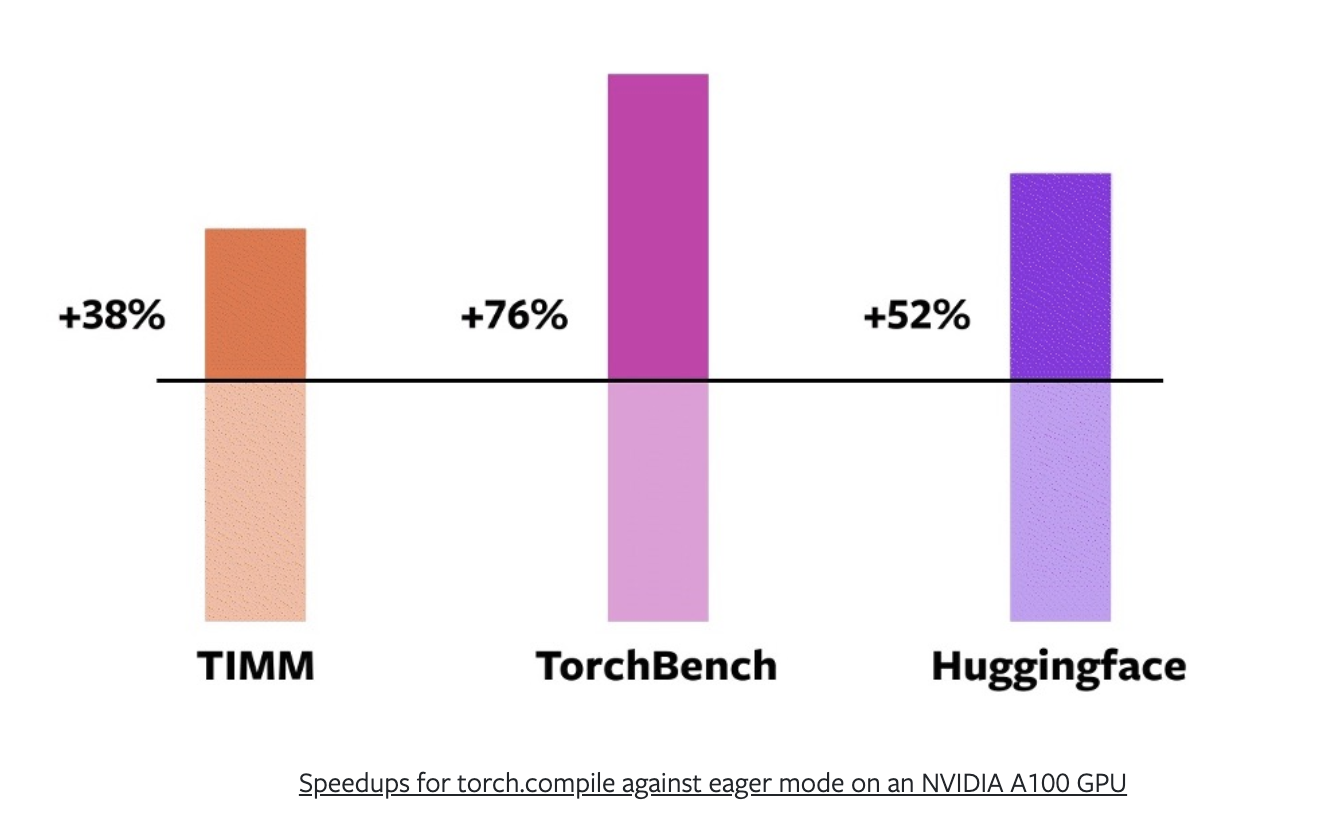
PyTorch 2.0 在来自不同来源的各种模型上的加速效果。来源:PyTorch 2.0 发布公告。
3分钟概览¶
注意: 以下内容改编自 mrdbourke.com 上的 A Quick Introduction to PyTorch 2.0,同时还有配套的 YouTube 视频解释。
torch.compile() 背后的工作原理是什么?
torch.compile() 旨在“即插即用”,但其背后涉及几项关键技术:
- TorchDynamo
- AOTAutograd
- PrimTorch
- TorchInductor
PyTorch 2.0 入门指南 对这些技术进行了更详细的解释,但从高层次来看,torch.compile() 提供的两大主要改进是:
- 融合(或操作融合)
- 图捕获(或图追踪)
融合¶
融合,也称为算子融合,是让深度学习模型加速训练的最佳方法之一(brrrrrr 是你的 GPU 风扇在模型训练时发出的声音)。
算子融合将多个操作浓缩为一个(或多对少),就像《龙珠Z》一样。
为什么呢?
现代 GPU 拥有如此强大的计算能力,以至于它们往往不是计算受限的,也就是说,训练模型的主要瓶颈在于你能以多快的速度将数据从 CPU 传输到 GPU。这就是所谓的带宽或内存带宽。
你希望尽可能减少带宽成本。
并且尽可能多地向饥饿的 GPU 提供数据。
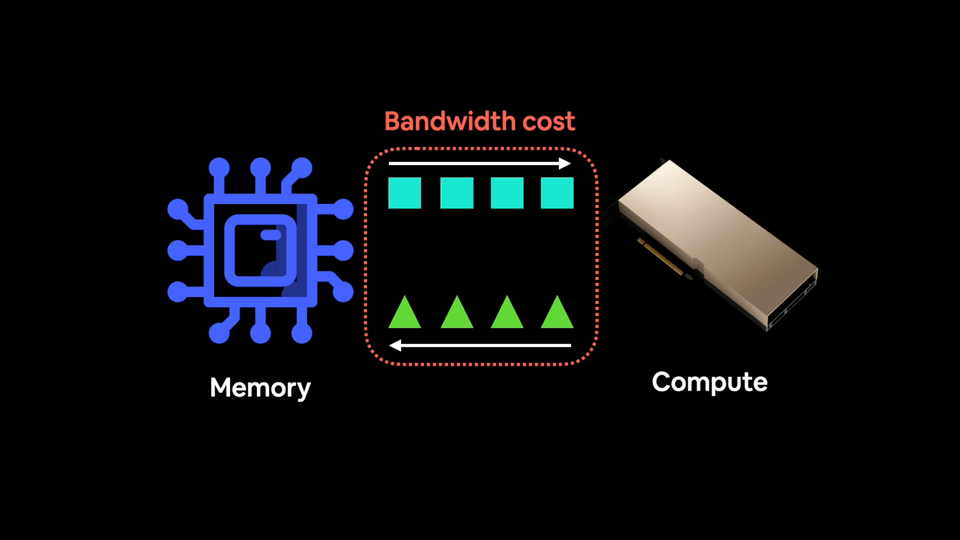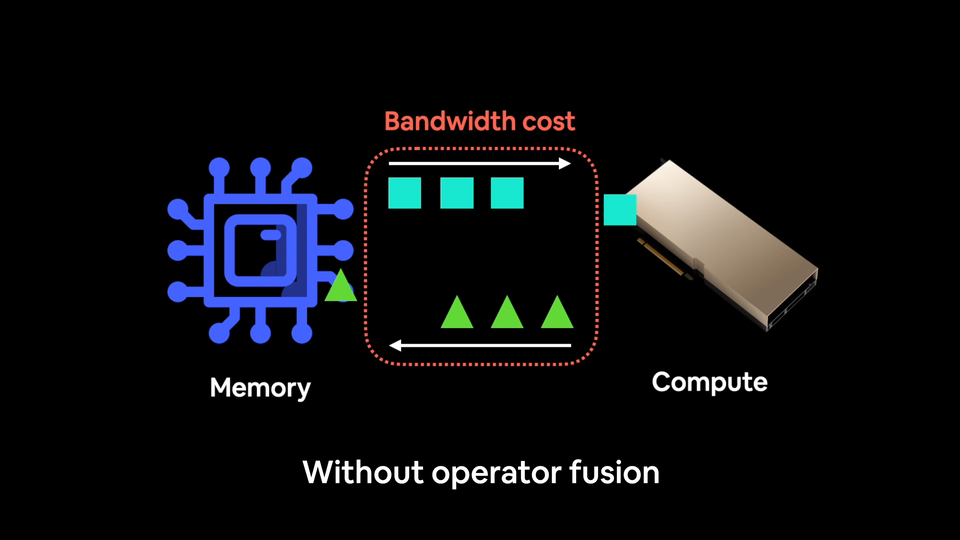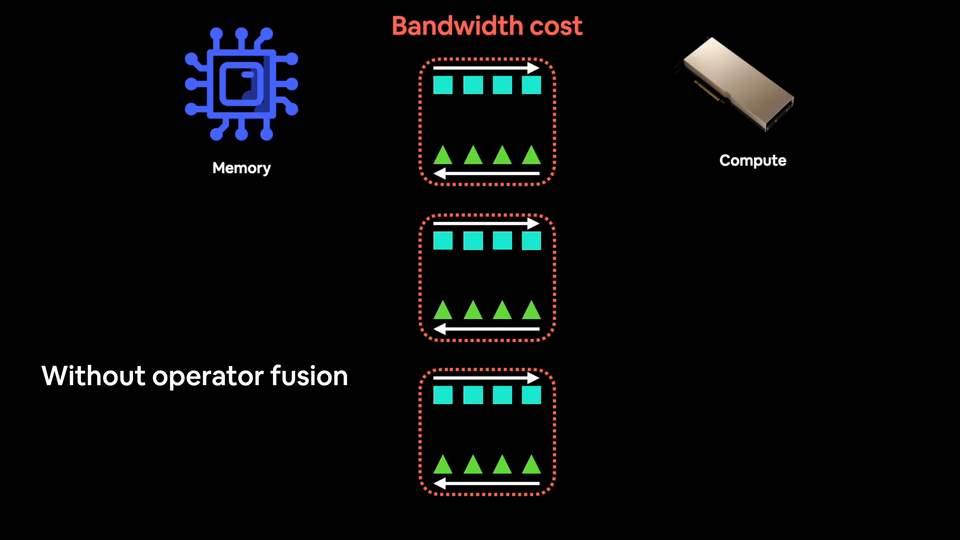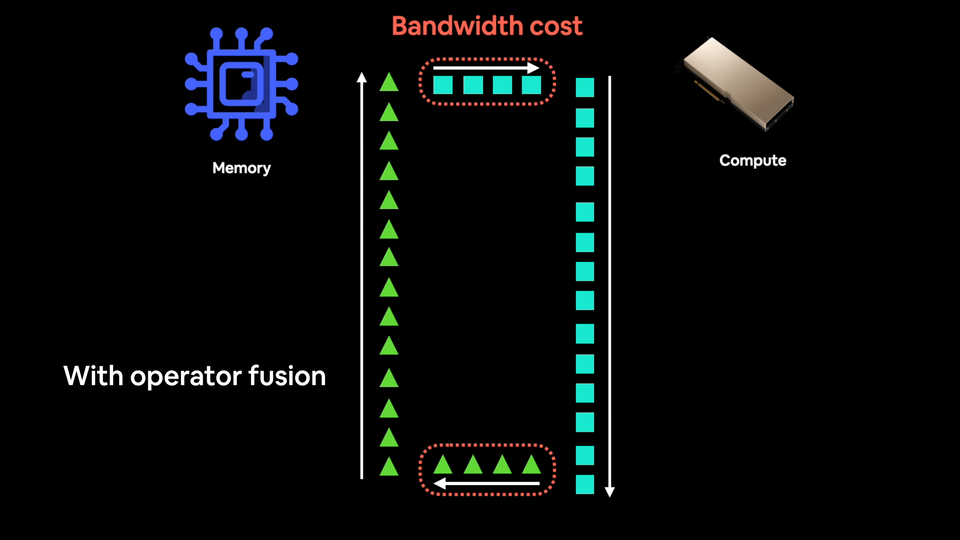
因此,与其对一块数据执行操作然后将结果保存到内存(增加带宽成本),不如通过融合将尽可能多的操作串联起来。
一个粗略的比喻是使用搅拌机制作冰沙。
大多数搅拌机擅长搅拌东西(就像 GPU 擅长执行矩阵乘法一样)。
使用没有算子融合的搅拌机,就像每次添加一种原料并每次混合。这不仅疯狂,还增加了你的带宽成本。
每次实际混合的速度很快(就像 GPU 计算通常很快一样),但你每次添加原料时都会损失大量时间。
使用有算子融合的搅拌机,类似于一开始就添加所有原料(算子融合),然后一次性进行混合。
一开始添加时会损失一点时间,但你将所有失去的内存带宽时间都找回来了。
图捕捉¶
图捕捉这个概念我解释起来不那么自信。
但我的理解是,图捕捉或图追踪是这样的:
- 经历一系列需要发生的操作,比如神经网络中的操作。
- 并且预先捕捉或追踪这些操作。
不使用图捕捉的计算就像去一个新地方,按照GPS的指示一步步转弯。
作为一个优秀的人类司机,你可以很容易地跟着转弯,但你仍然需要思考每一次转弯。
这相当于PyTorch在执行操作时必须查找每个操作的具体内容。
也就是说,要执行一个加法,它必须先查找加法的定义,然后才能执行。
尽管它执行得很快,但仍然存在非零的开销。
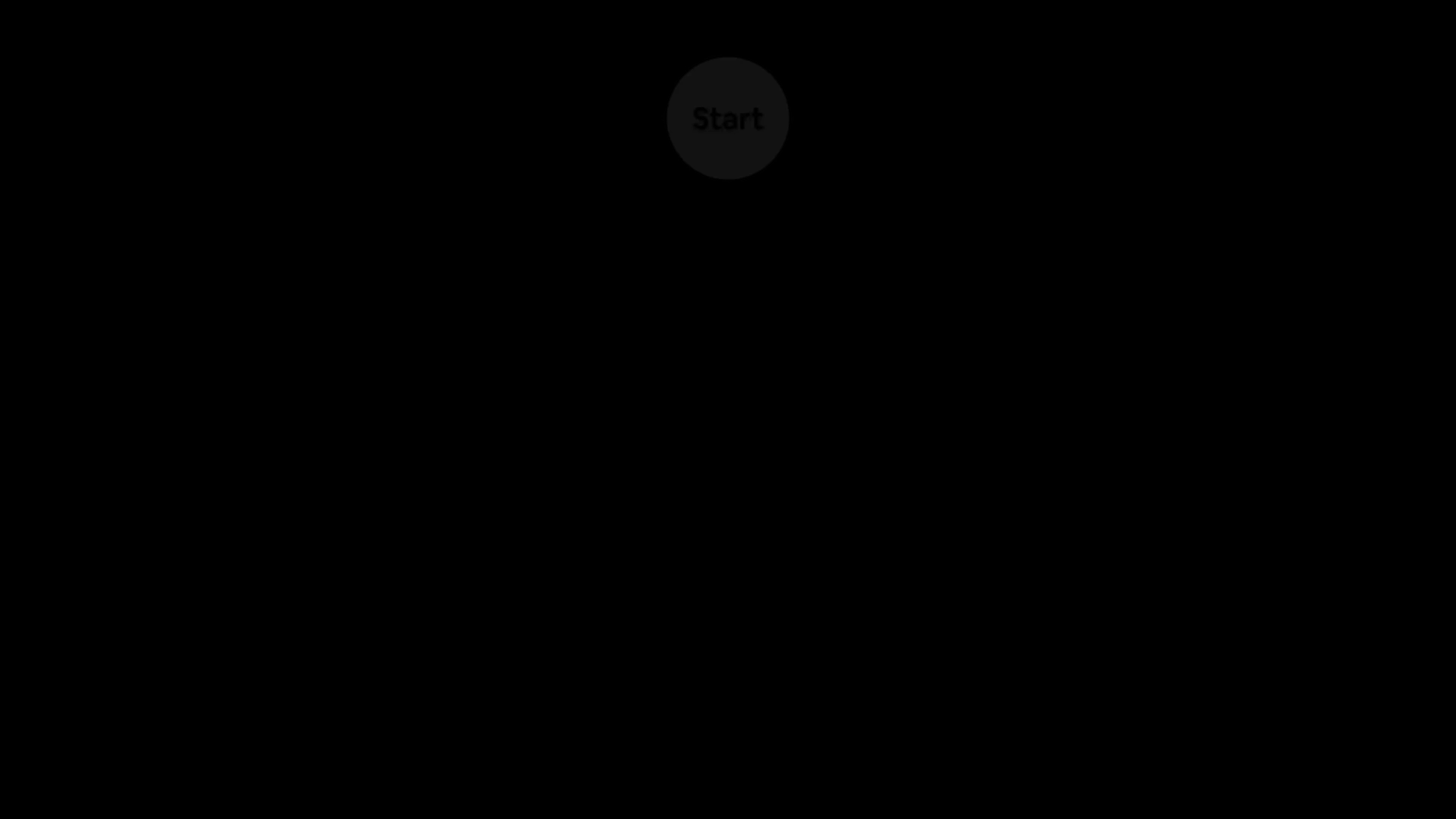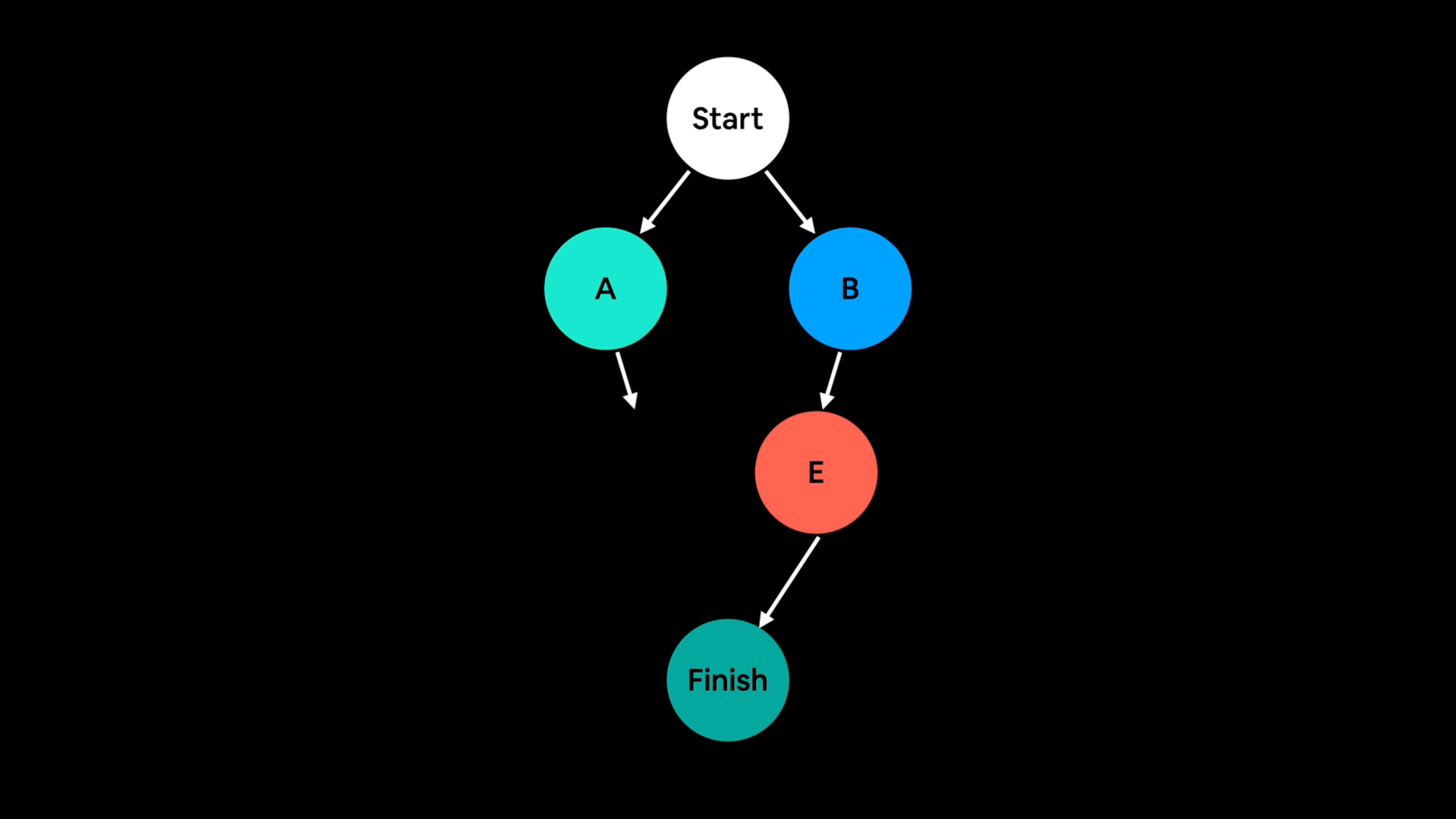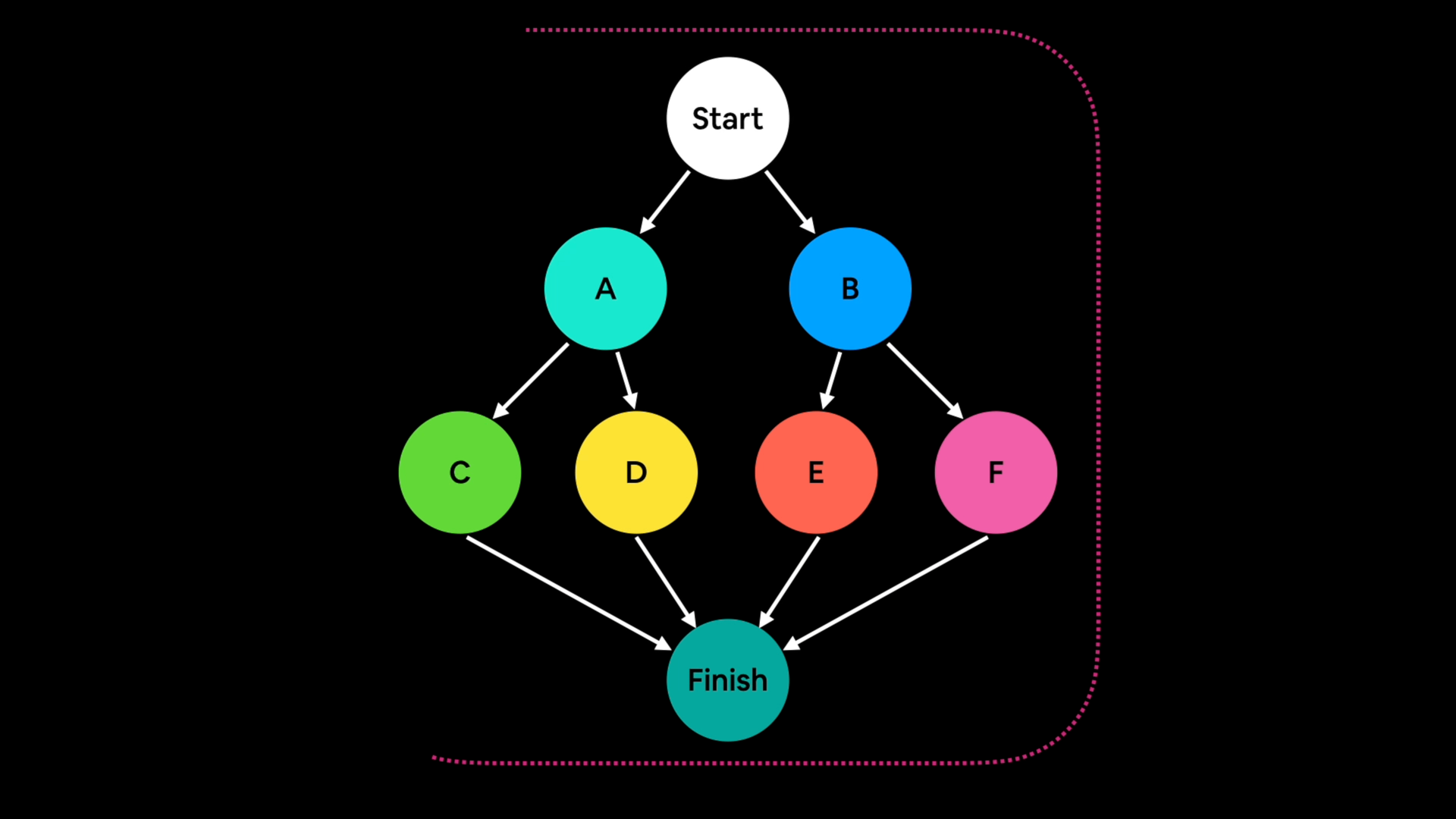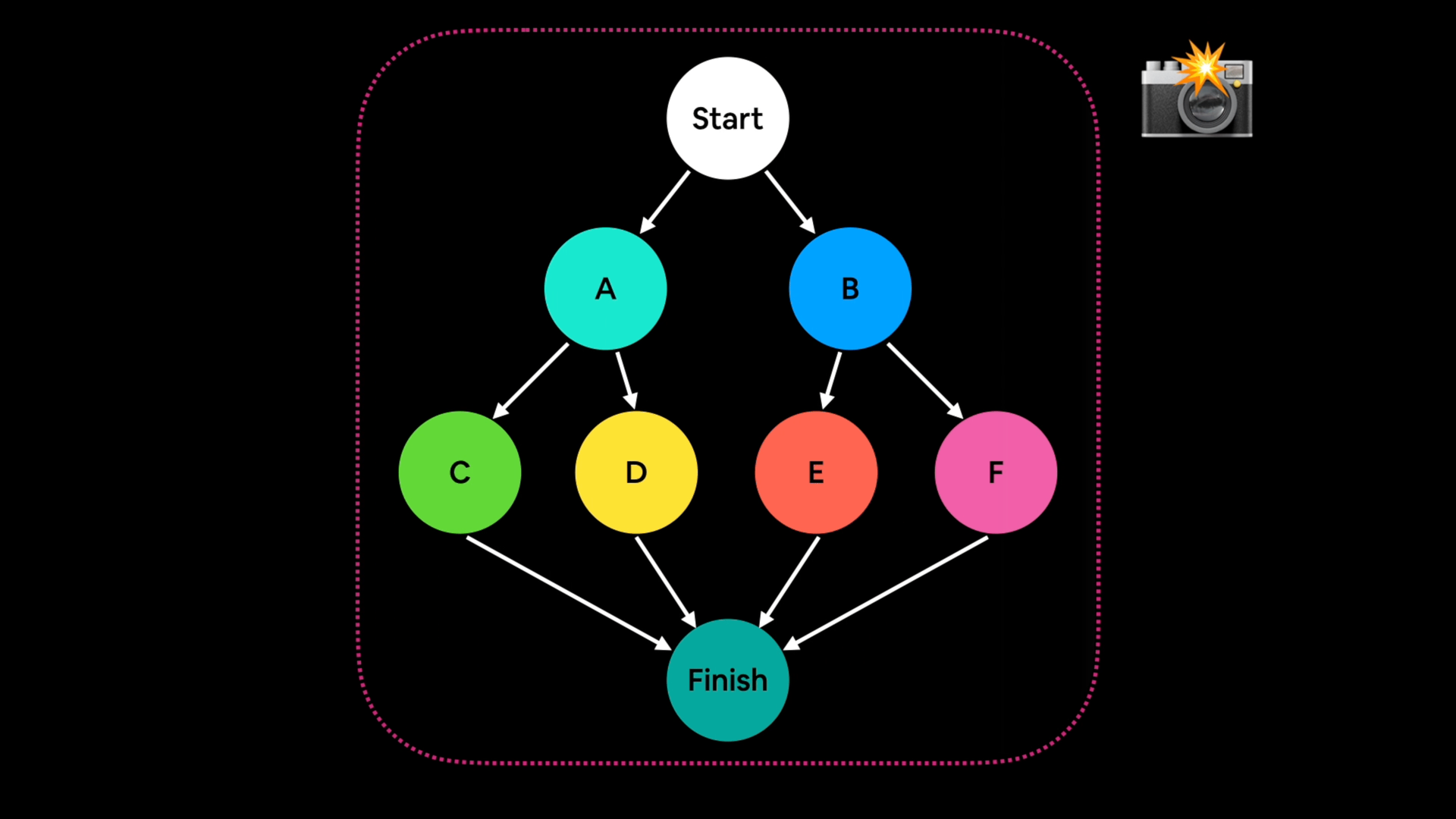
图捕捉的例子,绘制神经网络中的步骤并预先捕捉每个需要发生的操作。
使用图捕捉的计算就像在你自己的社区里开车。
你几乎不需要思考要如何转弯。
有时候你下车后,甚至不记得最后五分钟的驾驶过程。
你的大脑在自动驾驶模式下运行,开销极小。
然而,你在一开始花了些时间来记住如何开回家。
这就是图捕捉的一个缺点,它需要一些时间来预先记住需要发生的操作,但随后的计算应该会更快。
当然,这只是对torch.compile()背后发生事情的一个快速高层概述,但这是我理解的方式。
关于融合和图追踪的更多内容,我推荐Horace He的博客文章Making Deep Learning Go Brrrr From First Principles。
注意事项¶
由于 PyTorch 2.0 刚刚发布,某些功能存在一些限制。
其中最主要的一个是模型导出的限制。

使用 PyTorch 2.0 功能时有一些注意事项,例如在使用 torch.compile() 默认选项时无法导出到移动设备。不过,对此有一些变通方法,并且改进导出功能已列入 PyTorch 2.x 路线图。来源:PyTorch 2.0 发布公告。
然而,这些问题很可能会在未来的版本中得到解决。
另一个主要限制是,由于 PyTorch 2.0 的功能设计针对较新的硬件,旧款 GPU 和台式机级 GPU(例如 NVIDIA RTX 30 系列)可能不会像新硬件那样获得显著的速度提升。
我们将涵盖的内容¶
由于 PyTorch 2.0 中的许多升级都是以速度为重点,并且在幕后进行(例如,PyTorch 会自动处理它们),在本笔记本中,我们将进行一个对比速度测试。
具体来说,我们将创建两个相同的模型,一个使用默认的 PyTorch 设置,另一个使用新的 torch.compile() 设置,并在相同的数据集上训练它们。
- 模型1 - 不使用
torch.compile()。 - 模型2 - 使用
torch.compile()。
然后,我们将比较这两个模型在单次运行和多次运行中的训练/测试时间。
| 实验 | 模型 | 数据 | 周期 | 批量大小 | 图像大小 | torch.compile() |
|---|---|---|---|---|---|---|
| 1 (单次运行) | ResNet50 | CIFAR10 | 5 | 128 | 224 | 否 |
| 2 (单次运行) | ResNet50 | CIFAR10 | 5 | 128 | 224 | 是 |
| 3 (多次运行) | ResNet50 | CIFAR10 | 3x5 | 128 | 224 | 否 |
| 4 (多次运行) | ResNet50 | CIFAR10 | 3x5 | 128 | 224 | 是 |
我们在这里选择 ResNet50 和 CIFAR10 是为了便于访问或使用,不过你可以替换为你喜欢的任何模型/数据集。
我注意到 PyTorch 2.0 最大的速度提升是在 GPU 尽可能多地处理数据时(例如,更大的批量大小/图像大小/数据大小/模型大小)。
注意: 根据你的 GPU 大小,你可能需要降低批量大小(或图像大小)以适应你的 GPU。例如,如果你使用的是内存为 8GB 或更少的 GPU,你可能需要将批量大小降低到 64 或 32。
0. 环境设置¶
首先,我们将检查是否已安装 PyTorch 2.x 或更高版本,如果没有安装,我们将进行安装。
你可以在 PyTorch 文档 中查看如何在你的系统上安装 PyTorch 2.x。
注意: 如果你在 Google Colab 上运行,你需要设置 GPU:运行时 -> 更改运行时类型 -> 硬件加速器。最佳加速效果在新一代 NVIDIA/AMD GPU 上(这是因为 PyTorch 2.0 利用了新一代 GPU 硬件),例如 NVIDIA A100 及以上。本教程主要针对 NVIDIA GPU。
import torch
# Check PyTorch version
pt_version = torch.__version__
print(f"[INFO] Current PyTorch version: {pt_version} (should be 2.x+)")
# Install PyTorch 2.0 if necessary
if pt_version.split(".")[0] == "1": # Check if PyTorch version begins with 1
!pip3 install -U torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
print("[INFO] PyTorch 2.x installed, if you're on Google Colab, you may need to restart your runtime.\
Though as of April 2023, Google Colab comes with PyTorch 2.0 pre-installed.")
import torch
pt_version = torch.__version__
print(f"[INFO] Current PyTorch version: {pt_version} (should be 2.x+)")
else:
print("[INFO] PyTorch 2.x installed, you'll be able to use the new features.")
[INFO] Current PyTorch version: 2.0.0+cu118 (should be 2.x+) [INFO] PyTorch 2.x installed, you'll be able to use the new features.
太好了!
现在 PyTorch 2.x 已经安装好了,让我们来体验一下新功能吧!
1. 获取GPU信息¶
是时候获取GPU信息了。
为什么要获取?
PyTorch 2.0提供的许多加速效果最好在新一代NVIDIA GPU上体验(目前我们专注于NVIDIA GPU)。
这是因为PyTorch 2.0利用了新一代GPU上的新硬件。
如何判断GPU是否较新?
一般来说,较新的GPU的计算能力得分将达到8.0或更高。
你可以在NVIDIA开发者页面上查看NVIDIA GPU计算能力得分列表。
以下是2020年或之后发布的部分NVIDIA GPU及其计算能力得分:
| NVIDIA GPU | 计算能力得分 | GPU类型 | 发布年份 | 架构 |
|---|---|---|---|---|
| RTX 4090 | 8.9 | 桌面级 | 2022 | Ada Lovelace |
| RTX 4080 | 8.9 | 桌面级 | 2022 | Ada Lovelace |
| RTX 4070 Ti | 8.9 | 桌面级 | 2022 | Ada Lovelace |
| RTX 3090 | 8.6 | 桌面级 | 2020 | Ampere) |
| RTX 3080 | 8.6 | 桌面级 | 2020 | Ampere |
| RTX 3070 | 8.6 | 桌面级 | 2020 | Ampere |
| RTX 3060 Ti | 8.6 | 桌面级 | 2020 | Ampere |
| H100 | 9.0 | 数据中心级 | 2022 | Hopper |
| A100 | 8.0 | 数据中心级 | 2020 | Ampere |
| A10 | 8.6 | 数据中心级 | 2021 | Ampere |
计算能力得分达到8.0或以上的GPU可能会获得最大的加速效果。
而数据中心级GPU(如A100、A10、H100)可能会比桌面级GPU(如RTX 3090、RTX 3080、RTX 3070、RTX 3060 Ti)获得更显著的加速效果。
我们可以使用torch.cuda.get_device_capability()来检查我们GPU的计算能力得分。
这将输出一个包含(主要, 次要)计算能力得分的元组,例如,A100的得分是(8, 0)。
我们还可以使用nvidia-smi获取关于我们GPU的其他详细信息,如名称和其他信息。
资源: 如果你想深入比较许多不同的NVIDIA GPU及其速度、成本和权衡,我推荐阅读Tim Dettmers的博客文章Which GPU for deep learning?。
# Make sure we're using a NVIDIA GPU
if torch.cuda.is_available():
gpu_info = !nvidia-smi
gpu_info = '\n'.join(gpu_info)
if gpu_info.find("failed") >= 0:
print("Not connected to a GPU, to leverage the best of PyTorch 2.0, you should connect to a GPU.")
# Get GPU name
gpu_name = !nvidia-smi --query-gpu=gpu_name --format=csv
gpu_name = gpu_name[1]
GPU_NAME = gpu_name.replace(" ", "_") # remove underscores for easier saving
print(f'GPU name: {GPU_NAME}')
# Get GPU capability score
GPU_SCORE = torch.cuda.get_device_capability()
print(f"GPU capability score: {GPU_SCORE}")
if GPU_SCORE >= (8, 0):
print(f"GPU score higher than or equal to (8, 0), PyTorch 2.x speedup features available.")
else:
print(f"GPU score lower than (8, 0), PyTorch 2.x speedup features will be limited (PyTorch 2.x speedups happen most on newer GPUs).")
# Print GPU info
print(f"GPU information:\n{gpu_info}")
else:
print("PyTorch couldn't find a GPU, to leverage the best of PyTorch 2.0, you should connect to a GPU.")
GPU name: NVIDIA_TITAN_RTX
GPU capability score: (7, 5)
GPU score lower than (8, 0), PyTorch 2.x speedup features will be limited (PyTorch 2.x speedups happen most on newer GPUs).
GPU information:
Fri Apr 14 15:24:38 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.89.02 Driver Version: 525.89.02 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA TITAN RTX Off | 00000000:01:00.0 Off | N/A |
| 40% 50C P8 9W / 280W | 260MiB / 24576MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 1020 G /usr/lib/xorg/Xorg 53MiB |
| 0 N/A N/A 1415245 G /usr/lib/xorg/Xorg 162MiB |
| 0 N/A N/A 1415374 G /usr/bin/gnome-shell 8MiB |
+-----------------------------------------------------------------------------+
import torch
# Set the device
device = "cuda" if torch.cuda.is_available() else "cpu"
# Set the device with context manager (requires PyTorch 2.x+)
with torch.device(device):
# All tensors created in this block will be on device
layer = torch.nn.Linear(20, 30)
print(f"Layer weights are on device: {layer.weight.device}")
print(f"Layer creating data on device: {layer(torch.randn(128, 20)).device}")
Layer weights are on device: cuda:0 Layer creating data on device: cuda:0
现在让我们来设置全局设备吧。
这意味着,任何在没有显式指定设备的情况下创建的张量,都将默认在你所设置的设备上创建。
import torch
# Set the device
device = "cuda" if torch.cuda.is_available() else "cpu"
# Set the device globally
torch.set_default_device(device)
# All tensors created will be on the global device by default
layer = torch.nn.Linear(20, 30)
print(f"Layer weights are on device: {layer.weight.device}")
print(f"Layer creating data on device: {layer(torch.randn(128, 20)).device}")
Layer weights are on device: cuda:0 Layer creating data on device: cuda:0
现在回到 CPU。
import torch
# Set the device globally
torch.set_default_device("cpu")
# All tensors created will be on "cpu"
layer = torch.nn.Linear(20, 30)
print(f"Layer weights are on device: {layer.weight.device}")
print(f"Layer creating data on device: {layer(torch.randn(128, 20)).device}")
Layer weights are on device: cpu Layer creating data on device: cpu
2. 设置实验¶
好了,是时候测量速度了!
为了保持简单,正如我们讨论的那样,我们将进行一系列四个实验,所有实验都使用:
- 模型: ResNet50(来自 TorchVision)
- 数据: CIFAR10(来自 TorchVision)
- 周期: 5(单次运行)和 3x5(多次运行)
- 批量大小: 128
- 图像大小: 224
每个实验都将分别在启用和不启用 torch.compile() 的情况下运行。
为什么要进行单次和多次运行?
因为我们通过单次运行可以测量加速效果,但我们也需要多次运行测试以获得平均值(只是为了确保单次运行的结果不是偶然的或出现了某些问题)。
注意: 根据你的 GPU 内存大小,你可能需要降低批量大小或图像大小。本教程专注于使用具有 40GB 内存的 NVIDIA A100 GPU,这种 GPU 的内存意味着它可以处理更大的批量大小。截至 2023 年 4 月,NVIDIA A100 GPU 可通过 Google Colab Pro 获得。
让我们首先导入 torch 和 torchvision 并设置目标设备。
import torch
import torchvision
print(f"PyTorch version: {torch.__version__}")
print(f"TorchVision version: {torchvision.__version__}")
# Set the target device
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using device: {device}")
PyTorch version: 2.0.0+cu118 TorchVision version: 0.15.1+cu118 Using device: cuda
2.1 创建模型和转换¶
现在让我们创建模型和转换。
我们将使用相同的设置来创建模型和转换,这与我们在06. PyTorch 迁移学习第2.2节中介绍的内容相同。
本质上,我们将使用torchvision.models API来创建模型和转换。
我们可以通过以下方式获取ResNet50的权重和转换:
model_weights = torchvision.models.ResNet50_Weights.IMAGENET1K_V2(这需要torchvision0.14或更高版本)。transforms = model_weights.transforms()(一旦我们有了权重,就可以获取适用于该模型的适当转换)。
注意: 我们将计算模型的参数数量,以了解我们正在处理的是多大规模的模型。模型中的参数越多,训练它所需的GPU内存就越大。然而,模型的参数越多,它使用的GPU内存就越多,通常会获得更大的相对加速。也就是说,一个较大的模型可能需要更长的时间来训练,但由于它使用了更多的GPU资源,相对于较小的模型,它可能会更快。例如,一个拥有1000万个参数的模型可能只比一个拥有100万个参数的模型(10倍大小但只增加5倍训练时间)多花5倍的时间来训练。
# Create model weights and transforms
model_weights = torchvision.models.ResNet50_Weights.IMAGENET1K_V2 # <- use the latest weights (could also use .DEFAULT)
transforms = model_weights.transforms()
# Setup model
model = torchvision.models.resnet50(weights=model_weights)
# Count the number of parameters in the model
total_params = sum(
param.numel() for param in model.parameters() # <- all params
# param.numel() for param in model.parameters() if param.requires_grad # <- only trainable params
)
print(f"Total parameters of model: {total_params} (the more parameters, the more GPU memory the model will use, the more *relative* of a speedup you'll get)")
print(f"Model transforms:\n{transforms}")
Total parameters of model: 25557032 (the more parameters, the more GPU memory the model will use, the more *relative* of a speedup you'll get)
Model transforms:
ImageClassification(
crop_size=[224]
resize_size=[232]
mean=[0.485, 0.456, 0.406]
std=[0.229, 0.224, 0.225]
interpolation=InterpolationMode.BILINEAR
)
现在,让我们将上述代码转换为一个函数,以便之后可以重复使用。我们还将调整最后一层(model.fc)的输出特征,使其与CIFAR10数据集中的类别数量(10)相匹配。
def create_model(num_classes=10):
"""
Creates a ResNet50 model with the latest weights and transforms via torchvision.
"""
model_weights = torchvision.models.ResNet50_Weights.IMAGENET1K_V2
transforms = model_weights.transforms()
model = torchvision.models.resnet50(weights=model_weights)
# Adjust the number of output features in model to match the number of classes in the dataset
model.fc = torch.nn.Linear(in_features=2048,
out_features=num_classes)
return model, transforms
model, transforms = create_model()
2.2 当大量使用GPU时,加速效果最为显著¶
由于现代GPU在执行操作时速度极快,你通常会发现,当尽可能多的数据放在GPU上时,相对加速效果最为明显。
这可以通过以下方式实现:
- 增加批次大小 - 每个批次中包含更多样本意味着GPU上有更多样本,例如,使用批次大小为256而不是32。
- 增加数据大小 - 例如,使用更大的图像尺寸,224x224而不是32x32。更大的数据大小意味着在GPU上会有更多的张量操作。
- 增加模型大小 - 例如,使用更大的模型,如ResNet101而不是ResNet50。更大的模型意味着在GPU上会有更多的张量操作。
- 减少数据传输 - 例如,将所有张量设置为位于GPU内存中,这样可以最小化CPU和GPU之间的数据传输量。
所有这些方法都会导致更多的数据位于GPU上。

你可能会想,“这不意味着GPU会因为要做更多工作而变慢吗?”
这是正确的,当在GPU上使用更多数据时,操作可能会花费更长时间,但它们会从并行计算中受益(许多操作同时进行)。
这意味着尽管有更多的操作在进行,但GPU能够尽可能多地同时执行这些操作。
因此,虽然你可能会在小数据集、模型、批次大小和数据大小上看到加速效果,但随着规模的增加,你往往会看到最大的相对加速效果。
2.3 检查GPU的内存限制¶
为了利用规模化带来的速度提升,让我们检查一下我们的GPU有多少内存。
如果你的GPU内存较少,你可能需要减小批次大小或图像大小(减少潜在的速度提升)。
我们可以使用torch.cuda.mem_get_info()来检查我们GPU上的可用内存。
这将返回一个包含(total_free_gpu_memory, total_gpu_memory)的元组。
其中:
total_free_gpu_memory是GPU上当前未被使用的内存量,单位为字节。total_gpu_memory是GPU上可用的总内存量,单位为字节。
# Check available GPU memory and total GPU memory
total_free_gpu_memory, total_gpu_memory = torch.cuda.mem_get_info()
print(f"Total free GPU memory: {round(total_free_gpu_memory * 1e-9, 3)} GB")
print(f"Total GPU memory: {round(total_gpu_memory * 1e-9, 3)} GB")
Total free GPU memory: 24.187 GB Total GPU memory: 25.386 GB
太棒了!
这里的要点是:
- GPU 上的内存越多,你的批次大小可以越大,你的模型可以越大,你的数据样本可以越大。
- 为了加速,你应该总是尽量充分利用 GPU。
让我们写一些代码,如果 GPU 内存更多,就使用更大的批次大小。
注意: 你使用的理想批次大小将取决于你使用的特定 GPU、数据集和模型。下面的代码专门针对 Google Colab Pro 上可用的 A100 GPU。然而,你可能需要根据自己的 GPU 进行调整。如果你设置的批次大小过高,可能会遇到 CUDA 内存不足的错误。
如果 GPU 上可用的总内存超过 16GB,让我们使用批次大小为 128 和图像大小为 224(在内存更多的 GPU 上,这两个值都可以增加)。
如果 GPU 上可用的总内存低于 16GB,让我们使用批次大小为 32 和图像大小为 64(在内存较少的 GPU 上,这两个值都可以调整)。
# Set batch size depending on amount of GPU memory
total_free_gpu_memory_gb = round(total_free_gpu_memory * 1e-9, 3)
if total_free_gpu_memory_gb >= 16:
BATCH_SIZE = 128 # Note: you could experiment with higher values here if you like.
IMAGE_SIZE = 224
print(f"GPU memory available is {total_free_gpu_memory_gb} GB, using batch size of {BATCH_SIZE} and image size {IMAGE_SIZE}")
else:
BATCH_SIZE = 32
IMAGE_SIZE = 128
print(f"GPU memory available is {total_free_gpu_memory_gb} GB, using batch size of {BATCH_SIZE} and image size {IMAGE_SIZE}")
GPU memory available is 24.187 GB, using batch size of 128 and image size 224
现在让我们调整 transforms 以使用各自的 IMAGE_SIZE。
transforms.crop_size = IMAGE_SIZE
transforms.resize_size = IMAGE_SIZE
print(f"Updated data transforms:\n{transforms}")
Updated data transforms:
ImageClassification(
crop_size=224
resize_size=224
mean=[0.485, 0.456, 0.406]
std=[0.229, 0.224, 0.225]
interpolation=InterpolationMode.BILINEAR
)
2.4 使用 TF32 实现更多潜在加速¶
TF32 代表 TensorFloat-32,是一种结合了 16 位和 32 位浮点数的数据格式。
你可以在 NVIDIA 的博客上了解更多关于其工作原理的信息。
你应该知道的主要事情是,它允许你在具有 Ampere 架构及以上的 GPU(计算能力分数为 8.0+)上执行更快的矩阵乘法。
虽然这并不是特定于 PyTorch 2.0 的,但由于我们正在讨论较新的 GPU,因此值得一提。
如果你使用的是计算能力分数为 8.0 或以上的 GPU,你可以通过设置 torch.backends.cuda.matmul.allow_tf32 = True(默认为 False)来启用 TF32。
让我们编写一个检查程序,根据我们的 GPU 计算能力分数自动为我们设置它。
注意: 从 PyTorch 1.12 版本开始,TensorFloat32 默认是禁用的(设置为
False)。这是因为 它可能导致不同设备之间的结果不一致。尽管并非所有用例都会注意到这个问题,但了解这一点是值得的。
if GPU_SCORE >= (8, 0):
print(f"[INFO] Using GPU with score: {GPU_SCORE}, enabling TensorFloat32 (TF32) computing (faster on new GPUs)")
torch.backends.cuda.matmul.allow_tf32 = True
else:
print(f"[INFO] Using GPU with score: {GPU_SCORE}, TensorFloat32 (TF32) not available, to use it you need a GPU with score >= (8, 0)")
torch.backends.cuda.matmul.allow_tf32 = False
[INFO] Using GPU with score: (7, 5), TensorFloat32 (TF32) not available, to use it you need a GPU with score >= (8, 0)
2.5 准备数据集¶
计算环境设置完成!
现在让我们创建数据集。
为了简化操作,我们将使用 CIFAR10,因为它在 torchvision 中可以直接获取。
关于 CIFAR10 的一些信息,可以参考 CIFAR10 官网:
- CIFAR10 是一个包含 60,000 张 32x32 彩色图像的数据集,分为 10 个类别,每个类别有 6,000 张图像。
- 其中有 50,000 张训练图像和 10,000 张测试图像。
- 数据集包含 10 个类别:飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车。
尽管原始数据集由 32x32 的图像组成,但我们将使用之前创建的 transforms 将它们调整为 224x224(更大的图像提供更多信息,但也会占用更多 GPU 内存)。
# Create train and test datasets
train_dataset = torchvision.datasets.CIFAR10(root='.',
train=True,
download=True,
transform=transforms)
test_dataset = torchvision.datasets.CIFAR10(root='.',
train=False, # want the test split
download=True,
transform=transforms)
# Get the lengths of the datasets
train_len = len(train_dataset)
test_len = len(test_dataset)
print(f"[INFO] Train dataset length: {train_len}")
print(f"[INFO] Test dataset length: {test_len}")
Files already downloaded and verified Files already downloaded and verified [INFO] Train dataset length: 50000 [INFO] Test dataset length: 10000
2.6 创建 DataLoaders¶
通常情况下,GPU 并不是机器学习代码的瓶颈。
数据加载才是主要的瓶颈。
具体来说,是从 CPU 传输数据到 GPU 的速度。
正如我们之前讨论的,你希望尽可能快地将数据传输到 GPU。
让我们使用 torch.utils.data.DataLoader 来创建我们的 DataLoaders。
我们将它们的 batch_size 设置为我们之前创建的 BATCH_SIZE。
并将 num_workers 参数设置为我们可用 CPU 核心的数量,通过 os.cpu_count() 获取。
注意: 你可能希望尝试不同的
num_workers值,以找到最适合你的特定 GPU 和 CPU 配置的设置。根据我的经验,越多越好,但有些人发现这通常会达到一个上限,例如,num_workers = 4 * number_of_gpus_you_have,对于 1 个 GPU 来说,num_workers = 4 * 1。
from torch.utils.data import DataLoader
# Create DataLoaders
import os
NUM_WORKERS = os.cpu_count() # <- use all available CPU cores (this number can be tweaked through experimentation but generally more workers means faster dataloading from CPU to GPU)
train_dataloader = DataLoader(dataset=train_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=NUM_WORKERS)
test_dataloader = DataLoader(dataset=test_dataset,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=NUM_WORKERS)
# Print details
print(f"Train dataloader length: {len(train_dataloader)} batches of size {BATCH_SIZE}")
print(f"Test dataloader length: {len(test_dataloader)} batches of size {BATCH_SIZE}")
print(f"Using number of workers: {NUM_WORKERS} (generally more workers means faster dataloading from CPU to GPU)")
Train dataloader length: 391 batches of size 128 Test dataloader length: 79 batches of size 128 Using number of workers: 16 (generally more workers means faster dataloading from CPU to GPU)
2.7 创建训练和测试循环¶
数据加载器准备就绪!
现在让我们创建一些训练和测试循环。
这些将与我们在 05. PyTorch Going Modular 中创建的训练和测试循环基本相同,但有一些细微的修改。
由于我们专注于测量速度,我们将在每个循环中添加一个计时组件,以测量每个循环完成所需的时间。
我们将通过使用 Python 的 time.time() 测量每个训练和测试周期的开始和结束时间,并在一个字典中进行记录来实现这一点。
注意: 我在实验 PyTorch 2.0 时发现,
torch.inference_mode()在测试循环中产生了错误。因此,我将其改为torch.no_grad(),它提供了类似的功能,但比torch.inference_mode()更旧的方法。如果你发现torch.inference_mode()对你有效,请在 GitHub 上告诉我,我会更新这个笔记本。
import time
from tqdm.auto import tqdm
from typing import Dict, List, Tuple
def train_step(epoch: int,
model: torch.nn.Module,
dataloader: torch.utils.data.DataLoader,
loss_fn: torch.nn.Module,
optimizer: torch.optim.Optimizer,
device: torch.device,
disable_progress_bar: bool = False) -> Tuple[float, float]:
"""Trains a PyTorch model for a single epoch.
Turns a target PyTorch model to training mode and then
runs through all of the required training steps (forward
pass, loss calculation, optimizer step).
Args:
model: A PyTorch model to be trained.
dataloader: A DataLoader instance for the model to be trained on.
loss_fn: A PyTorch loss function to minimize.
optimizer: A PyTorch optimizer to help minimize the loss function.
device: A target device to compute on (e.g. "cuda" or "cpu").
Returns:
A tuple of training loss and training accuracy metrics.
In the form (train_loss, train_accuracy). For example:
(0.1112, 0.8743)
"""
# Put model in train mode
model.train()
# Setup train loss and train accuracy values
train_loss, train_acc = 0, 0
# Loop through data loader data batches
progress_bar = tqdm(
enumerate(dataloader),
desc=f"Training Epoch {epoch}",
total=len(dataloader),
disable=disable_progress_bar
)
for batch, (X, y) in progress_bar:
# Send data to target device
X, y = X.to(device), y.to(device)
# 1. Forward pass
y_pred = model(X)
# 2. Calculate and accumulate loss
loss = loss_fn(y_pred, y)
train_loss += loss.item()
# 3. Optimizer zero grad
optimizer.zero_grad()
# 4. Loss backward
loss.backward()
# 5. Optimizer step
optimizer.step()
# Calculate and accumulate accuracy metric across all batches
y_pred_class = torch.argmax(torch.softmax(y_pred, dim=1), dim=1)
train_acc += (y_pred_class == y).sum().item()/len(y_pred)
# Update progress bar
progress_bar.set_postfix(
{
"train_loss": train_loss / (batch + 1),
"train_acc": train_acc / (batch + 1),
}
)
# Adjust metrics to get average loss and accuracy per batch
train_loss = train_loss / len(dataloader)
train_acc = train_acc / len(dataloader)
return train_loss, train_acc
def test_step(epoch: int,
model: torch.nn.Module,
dataloader: torch.utils.data.DataLoader,
loss_fn: torch.nn.Module,
device: torch.device,
disable_progress_bar: bool = False) -> Tuple[float, float]:
"""Tests a PyTorch model for a single epoch.
Turns a target PyTorch model to "eval" mode and then performs
a forward pass on a testing dataset.
Args:
model: A PyTorch model to be tested.
dataloader: A DataLoader instance for the model to be tested on.
loss_fn: A PyTorch loss function to calculate loss on the test data.
device: A target device to compute on (e.g. "cuda" or "cpu").
Returns:
A tuple of testing loss and testing accuracy metrics.
In the form (test_loss, test_accuracy). For example:
(0.0223, 0.8985)
"""
# Put model in eval mode
model.eval()
# Setup test loss and test accuracy values
test_loss, test_acc = 0, 0
# Loop through data loader data batches
progress_bar = tqdm(
enumerate(dataloader),
desc=f"Testing Epoch {epoch}",
total=len(dataloader),
disable=disable_progress_bar
)
# Turn on inference context manager
with torch.no_grad(): # no_grad() required for PyTorch 2.0, I found some errors with `torch.inference_mode()`, please let me know if this is not the case
# Loop through DataLoader batches
for batch, (X, y) in progress_bar:
# Send data to target device
X, y = X.to(device), y.to(device)
# 1. Forward pass
test_pred_logits = model(X)
# 2. Calculate and accumulate loss
loss = loss_fn(test_pred_logits, y)
test_loss += loss.item()
# Calculate and accumulate accuracy
test_pred_labels = test_pred_logits.argmax(dim=1)
test_acc += ((test_pred_labels == y).sum().item()/len(test_pred_labels))
# Update progress bar
progress_bar.set_postfix(
{
"test_loss": test_loss / (batch + 1),
"test_acc": test_acc / (batch + 1),
}
)
# Adjust metrics to get average loss and accuracy per batch
test_loss = test_loss / len(dataloader)
test_acc = test_acc / len(dataloader)
return test_loss, test_acc
def train(model: torch.nn.Module,
train_dataloader: torch.utils.data.DataLoader,
test_dataloader: torch.utils.data.DataLoader,
optimizer: torch.optim.Optimizer,
loss_fn: torch.nn.Module,
epochs: int,
device: torch.device,
disable_progress_bar: bool = False) -> Dict[str, List]:
"""Trains and tests a PyTorch model.
Passes a target PyTorch models through train_step() and test_step()
functions for a number of epochs, training and testing the model
in the same epoch loop.
Calculates, prints and stores evaluation metrics throughout.
Args:
model: A PyTorch model to be trained and tested.
train_dataloader: A DataLoader instance for the model to be trained on.
test_dataloader: A DataLoader instance for the model to be tested on.
optimizer: A PyTorch optimizer to help minimize the loss function.
loss_fn: A PyTorch loss function to calculate loss on both datasets.
epochs: An integer indicating how many epochs to train for.
device: A target device to compute on (e.g. "cuda" or "cpu").
Returns:
A dictionary of training and testing loss as well as training and
testing accuracy metrics. Each metric has a value in a list for
each epoch.
In the form: {train_loss: [...],
train_acc: [...],
test_loss: [...],
test_acc: [...]}
For example if training for epochs=2:
{train_loss: [2.0616, 1.0537],
train_acc: [0.3945, 0.3945],
test_loss: [1.2641, 1.5706],
test_acc: [0.3400, 0.2973]}
"""
# Create empty results dictionary
results = {"train_loss": [],
"train_acc": [],
"test_loss": [],
"test_acc": [],
"train_epoch_time": [],
"test_epoch_time": []
}
# Loop through training and testing steps for a number of epochs
for epoch in tqdm(range(epochs), disable=disable_progress_bar):
# Perform training step and time it
train_epoch_start_time = time.time()
train_loss, train_acc = train_step(epoch=epoch,
model=model,
dataloader=train_dataloader,
loss_fn=loss_fn,
optimizer=optimizer,
device=device,
disable_progress_bar=disable_progress_bar)
train_epoch_end_time = time.time()
train_epoch_time = train_epoch_end_time - train_epoch_start_time
# Perform testing step and time it
test_epoch_start_time = time.time()
test_loss, test_acc = test_step(epoch=epoch,
model=model,
dataloader=test_dataloader,
loss_fn=loss_fn,
device=device,
disable_progress_bar=disable_progress_bar)
test_epoch_end_time = time.time()
test_epoch_time = test_epoch_end_time - test_epoch_start_time
# Print out what's happening
print(
f"Epoch: {epoch+1} | "
f"train_loss: {train_loss:.4f} | "
f"train_acc: {train_acc:.4f} | "
f"test_loss: {test_loss:.4f} | "
f"test_acc: {test_acc:.4f} | "
f"train_epoch_time: {train_epoch_time:.4f} | "
f"test_epoch_time: {test_epoch_time:.4f}"
)
# Update results dictionary
results["train_loss"].append(train_loss)
results["train_acc"].append(train_acc)
results["test_loss"].append(test_loss)
results["test_acc"].append(test_acc)
results["train_epoch_time"].append(train_epoch_time)
results["test_epoch_time"].append(test_epoch_time)
# Return the filled results at the end of the epochs
return results
3.1 实验1 - 单次运行,不编译¶
在实验1中,我们将使用以下参数:
| 实验 | 模型 | 数据集 | 周期数 | 批次大小 | 图像尺寸 | torch.compile() |
|---|---|---|---|---|---|---|
| 1(单次运行) | ResNet50 | CIFAR10 | 5 | 128 | 224 | 否 |
我们将周期数设置为 5,并全程使用 0.003 的学习率(你可以尝试不同的学习率以获得更好的结果,但我们目前专注于速度)。
# Set the number of epochs as a constant
NUM_EPOCHS = 5
# Set the learning rate as a constant (this can be changed to get better results but for now we're just focused on time)
LEARNING_RATE = 0.003
注意: 根据您的GPU速度,以下代码可能需要一段时间才能运行。例如,在我的本地NVIDIA TITAN RTX上大约需要16分钟,而在Google Colab Pro上的NVIDIA A100 GPU上大约需要7分钟。
# Create model
model, transforms = create_model()
model.to(device)
# Create loss function and optimizer
loss_fn = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(),
lr=LEARNING_RATE)
# Train model and track results
single_run_no_compile_results = train(model=model,
train_dataloader=train_dataloader,
test_dataloader=test_dataloader,
loss_fn=loss_fn,
optimizer=optimizer,
epochs=NUM_EPOCHS,
device=device)
0%| | 0/5 [00:00<?, ?it/s]
Training Epoch 0: 0%| | 0/391 [00:00<?, ?it/s]
Testing Epoch 0: 0%| | 0/79 [00:00<?, ?it/s]
Epoch: 1 | train_loss: 0.7734 | train_acc: 0.7333 | test_loss: 0.8021 | test_acc: 0.7477 | train_epoch_time: 184.9701 | test_epoch_time: 12.9893
Training Epoch 1: 0%| | 0/391 [00:00<?, ?it/s]
Testing Epoch 1: 0%| | 0/79 [00:00<?, ?it/s]
Epoch: 2 | train_loss: 0.4337 | train_acc: 0.8501 | test_loss: 0.4794 | test_acc: 0.8338 | train_epoch_time: 185.3404 | test_epoch_time: 12.9515
Training Epoch 2: 0%| | 0/391 [00:00<?, ?it/s]
Testing Epoch 2: 0%| | 0/79 [00:00<?, ?it/s]
Epoch: 3 | train_loss: 0.3055 | train_acc: 0.8944 | test_loss: 0.4282 | test_acc: 0.8533 | train_epoch_time: 185.3870 | test_epoch_time: 13.0559
Training Epoch 3: 0%| | 0/391 [00:00<?, ?it/s]
Testing Epoch 3: 0%| | 0/79 [00:00<?, ?it/s]
Epoch: 4 | train_loss: 0.2268 | train_acc: 0.9198 | test_loss: 0.4387 | test_acc: 0.8580 | train_epoch_time: 185.5914 | test_epoch_time: 13.0495
Training Epoch 4: 0%| | 0/391 [00:00<?, ?it/s]
Testing Epoch 4: 0%| | 0/79 [00:00<?, ?it/s]
Epoch: 5 | train_loss: 0.1723 | train_acc: 0.9395 | test_loss: 0.3901 | test_acc: 0.8754 | train_epoch_time: 185.5304 | test_epoch_time: 13.0517
3.2 实验 2 - 单次运行,使用编译¶
现在我们将进行相同的实验,但这次我们将使用 torch.compile()。
| 实验 | 模型 | 数据 | Epochs | Batch size | 图像尺寸 | torch.compile() |
|---|---|---|---|---|---|---|
| 2 (单次运行) | ResNet50 | CIFAR10 | 5 | 128 | 224 | 是 |
注意: 根据您的 GPU 速度,以下代码可能需要一些时间来运行。例如,在我的本地 NVIDIA TITAN RTX 上大约需要 16 分钟,而在 Google Colab Pro 上的 NVIDIA A100 GPU 上大约需要 7 分钟。
# Create model and transforms
model, transforms = create_model()
model.to(device)
# Create loss function and optimizer
loss_fn = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(),
lr=LEARNING_RATE)
# Compile the model and time how long it takes
compile_start_time = time.time()
### New in PyTorch 2.x ###
compiled_model = torch.compile(model)
##########################
compile_end_time = time.time()
compile_time = compile_end_time - compile_start_time
print(f"Time to compile: {compile_time} | Note: The first time you compile your model, the first few epochs will be slower than subsequent runs.")
# Train the compiled model
single_run_compile_results = train(model=compiled_model,
train_dataloader=train_dataloader,
test_dataloader=test_dataloader,
loss_fn=loss_fn,
optimizer=optimizer,
epochs=NUM_EPOCHS,
device=device)
Time to compile: 0.00491642951965332 | Note: The first time you compile your model, the first few epochs will be slower than subsequent runs.
0%| | 0/5 [00:00<?, ?it/s]
Training Epoch 0: 0%| | 0/391 [00:00<?, ?it/s]
Testing Epoch 0: 0%| | 0/79 [00:00<?, ?it/s]
Epoch: 1 | train_loss: 0.7585 | train_acc: 0.7364 | test_loss: 0.5852 | test_acc: 0.8004 | train_epoch_time: 196.4621 | test_epoch_time: 21.0730
Training Epoch 1: 0%| | 0/391 [00:00<?, ?it/s]
Testing Epoch 1: 0%| | 0/79 [00:00<?, ?it/s]
Epoch: 2 | train_loss: 0.4288 | train_acc: 0.8521 | test_loss: 0.5468 | test_acc: 0.8108 | train_epoch_time: 169.9891 | test_epoch_time: 11.0555
Training Epoch 2: 0%| | 0/391 [00:00<?, ?it/s]
Testing Epoch 2: 0%| | 0/79 [00:00<?, ?it/s]
Epoch: 3 | train_loss: 0.3080 | train_acc: 0.8928 | test_loss: 0.4791 | test_acc: 0.8377 | train_epoch_time: 170.4004 | test_epoch_time: 10.9841
Training Epoch 3: 0%| | 0/391 [00:00<?, ?it/s]
Testing Epoch 3: 0%| | 0/79 [00:00<?, ?it/s]
Epoch: 4 | train_loss: 0.2322 | train_acc: 0.9184 | test_loss: 0.5551 | test_acc: 0.8306 | train_epoch_time: 170.1974 | test_epoch_time: 11.0482
Training Epoch 4: 0%| | 0/391 [00:00<?, ?it/s]
Testing Epoch 4: 0%| | 0/79 [00:00<?, ?it/s]
Epoch: 5 | train_loss: 0.1766 | train_acc: 0.9376 | test_loss: 0.3410 | test_acc: 0.8874 | train_epoch_time: 170.0547 | test_epoch_time: 10.9239
3.3 比较实验1和实验2的结果¶
太棒了!
我们已经得到了两个训练好的模型:
- 一个没有使用
torch.compile()的模型。 - 一个使用了
torch.compile()的模型。
让我们来比较这两个实验的结果。
为此,我们首先将每个实验的结果创建成数据框。
然后,我们将每个实验的结果绘制在条形图上。
# Turn experiment results into dataframes
import pandas as pd
single_run_no_compile_results_df = pd.DataFrame(single_run_no_compile_results)
single_run_compile_results_df = pd.DataFrame(single_run_compile_results)
# Check out the head of one of the results dataframes
single_run_no_compile_results_df.head()
| train_loss | train_acc | test_loss | test_acc | train_epoch_time | test_epoch_time | |
|---|---|---|---|---|---|---|
| 0 | 0.773435 | 0.733272 | 0.802100 | 0.747725 | 184.970135 | 12.989331 |
| 1 | 0.433699 | 0.850052 | 0.479412 | 0.833762 | 185.340373 | 12.951483 |
| 2 | 0.305494 | 0.894429 | 0.428212 | 0.853343 | 185.386973 | 13.055891 |
| 3 | 0.226751 | 0.919829 | 0.438668 | 0.857991 | 185.591368 | 13.049541 |
| 4 | 0.172269 | 0.939482 | 0.390148 | 0.875396 | 185.530370 | 13.051713 |
实验1和实验2的结果出来啦!
接下来,我们写一个函数来接收这些结果,并用条形图进行比较。
我们会在函数中添加一些元数据,以便显示有关实验的一些信息。
具体来说,包括我们实验设置中的所有参数:
- 数据集名称
- 模型名称
- 训练周期数
- 批量大小
- 图像尺寸
# Create filename to save the results
DATASET_NAME = "CIFAR10"
MODEL_NAME = "ResNet50"
import matplotlib.pyplot as plt
import numpy as np
def plot_mean_epoch_times(non_compiled_results: pd.DataFrame,
compiled_results: pd.DataFrame,
multi_runs: bool=False,
num_runs: int=0,
save: bool=False,
save_path: str="",
dataset_name: str=DATASET_NAME,
model_name: str=MODEL_NAME,
num_epochs: int=NUM_EPOCHS,
image_size: int=IMAGE_SIZE,
batch_size: int=BATCH_SIZE) -> plt.figure:
# Get the mean epoch times from the non-compiled models
mean_train_epoch_time = non_compiled_results.train_epoch_time.mean()
mean_test_epoch_time = non_compiled_results.test_epoch_time.mean()
mean_results = [mean_train_epoch_time, mean_test_epoch_time]
# Get the mean epoch times from the compiled models
mean_compile_train_epoch_time = compiled_results.train_epoch_time.mean()
mean_compile_test_epoch_time = compiled_results.test_epoch_time.mean()
mean_compile_results = [mean_compile_train_epoch_time, mean_compile_test_epoch_time]
# Calculate the percentage difference between the mean compile and non-compile train epoch times
train_epoch_time_diff = mean_compile_train_epoch_time - mean_train_epoch_time
train_epoch_time_diff_percent = (train_epoch_time_diff / mean_train_epoch_time) * 100
# Calculate the percentage difference between the mean compile and non-compile test epoch times
test_epoch_time_diff = mean_compile_test_epoch_time - mean_test_epoch_time
test_epoch_time_diff_percent = (test_epoch_time_diff / mean_test_epoch_time) * 100
# Print the mean difference percentages
print(f"Mean train epoch time difference: {round(train_epoch_time_diff_percent, 3)}% (negative means faster)")
print(f"Mean test epoch time difference: {round(test_epoch_time_diff_percent, 3)}% (negative means faster)")
# Create a bar plot of the mean train and test epoch time for both compiled and non-compiled models
plt.figure(figsize=(10, 7))
width = 0.3
x_indicies = np.arange(len(mean_results))
plt.bar(x=x_indicies, height=mean_results, width=width, label="non_compiled_results")
plt.bar(x=x_indicies + width, height=mean_compile_results, width=width, label="compiled_results")
plt.xticks(x_indicies + width / 2, ("Train Epoch", "Test Epoch"))
plt.ylabel("Mean epoch time (seconds, lower is better)")
# Create the title based on the parameters passed to the function
if multi_runs:
plt.suptitle("Multiple run results")
plt.title(f"GPU: {gpu_name} | Epochs: {num_epochs} ({num_runs} runs) | Data: {dataset_name} | Model: {model_name} | Image size: {image_size} | Batch size: {batch_size}")
else:
plt.suptitle("Single run results")
plt.title(f"GPU: {gpu_name} | Epochs: {num_epochs} | Data: {dataset_name} | Model: {model_name} | Image size: {image_size} | Batch size: {batch_size}")
plt.legend();
# Save the figure
if save:
assert save_path != "", "Please specify a save path to save the model figure to via the save_path parameter."
plt.savefig(save_path)
print(f"[INFO] Plot saved to {save_path}")
绘图函数已就绪!
让我们创建一个目录来存储我们的图表,然后绘制前两个实验的结果。
# Create directory for saving figures
import os
dir_to_save_figures_in = "pytorch_2_results/figures/"
os.makedirs(dir_to_save_figures_in, exist_ok=True)
# Create a save path for the single run results
save_path_multi_run = f"{dir_to_save_figures_in}single_run_{GPU_NAME}_{MODEL_NAME}_{DATASET_NAME}_{IMAGE_SIZE}_train_epoch_time.png"
print(f"[INFO] Save path for single run results: {save_path_multi_run}")
# Plot the results and save the figures
plot_mean_epoch_times(non_compiled_results=single_run_no_compile_results_df,
compiled_results=single_run_compile_results_df,
multi_runs=False,
save_path=save_path_multi_run,
save=True)
[INFO] Save path for single run results: pytorch_2_results/figures/single_run_NVIDIA_TITAN_RTX_ResNet50_CIFAR10_224_train_epoch_time.png Mean train epoch time difference: -5.364% (negative means faster) Mean test epoch time difference: -0.02% (negative means faster) [INFO] Plot saved to pytorch_2_results/figures/single_run_NVIDIA_TITAN_RTX_ResNet50_CIFAR10_224_train_epoch_time.png

嗯... 这里发生了什么?
看起来使用 torch.compile() 的模型比不使用它的模型花费了更长时间(在 A100 上确实如此,但在我的本地 NVIDIA TITAN RTX 上,编译后的模型稍微快一些)。
这可能是什么原因呢?
从每个 epoch 的时间来看,我们可以发现尽管实验 2(使用 torch.compile())在第一个 epoch 时远比实验 1(不使用 torch.compile())慢,但在后续的 epoch 中它开始变得更快。
这是因为 torch.compile() 在幕后在训练运行的前几步中“预热”模型,并在幕后执行优化步骤。
这些优化步骤在前期的确会花费时间,但意味着后续步骤应该会更快。
为了验证这一点,你可以尝试将上述模型训练更长时间(比如 50 个 epoch 而不是 5 个),看看平均训练时间会是多少。
3.4 将单次运行结果保存到文件并包含GPU详情¶
我们也可以将结果的原始数据保存到文件中,方法是将数据框导出为CSV文件。
首先,我们将创建一个用于存储结果的目录。
然后,在导出每个目标数据框之前,我们将创建文件路径以保存它们。
# Make a directory for single_run results
import os
pytorch_2_results_dir = "pytorch_2_results"
pytorch_2_single_run_results_dir = f"{pytorch_2_results_dir}/single_run_results"
os.makedirs(pytorch_2_single_run_results_dir, exist_ok=True)
# Create filenames for each of the dataframes
save_name_for_non_compiled_results = f"single_run_non_compiled_results_{DATASET_NAME}_{MODEL_NAME}_{GPU_NAME}.csv"
save_name_for_compiled_results = f"single_run_compiled_results_{DATASET_NAME}_{MODEL_NAME}_{GPU_NAME}.csv"
# Create filepaths to save the results to
single_run_no_compile_save_path = f"{pytorch_2_single_run_results_dir}/{save_name_for_non_compiled_results}"
single_run_compile_save_path = f"{pytorch_2_single_run_results_dir}/{save_name_for_compiled_results}"
print(f"[INFO] Saving non-compiled experiment 1 results to: {single_run_no_compile_save_path}")
print(f"[INFO] Saving compiled experiment 2 results to: {single_run_compile_save_path}")
# Save the results
single_run_no_compile_results_df.to_csv(single_run_no_compile_save_path)
single_run_compile_results_df.to_csv(single_run_compile_save_path)
[INFO] Saving non-compiled experiment 1 results to: pytorch_2_results/single_run_results/single_run_non_compiled_results_CIFAR10_ResNet50_NVIDIA_TITAN_RTX.csv [INFO] Saving compiled experiment 2 results to: pytorch_2_results/single_run_results/single_run_compiled_results_CIFAR10_ResNet50_NVIDIA_TITAN_RTX.csv
4. 多次运行的时间模型¶
现在我们已经测试了在启用和禁用 torch.compile() 的情况下进行单次运行的模型,接下来让我们对多次运行进行同样的测试。
我们将首先为实验3和实验4创建三个函数。
- 实验3:
create_and_train_non_compiled_model()- 这个函数将类似于我们用于单次运行的工作流程。我们将把模型创建(通过create_model())和训练放在一个函数中,以便我们可以多次调用它(进行多次运行)并测量每次运行的时间。 - 实验4:
create_compiled_model()- 这个函数将类似于上面的create_model()函数,但是,它将创建一个普通的 PyTorch 模型,然后在其上调用torch.compile()并返回它。 - 实验4:
train_compiled_model()- 这个函数将接受一个已编译的模型并以我们为单次运行训练模型的相同方式进行训练。
为什么为实验4分离函数2和3(create_compiled_model() 和 train_compiled_model())?
因为在模型上调用 torch.compile() 意味着在前几次运行中,模型将处于“预热”状态,因为 PyTorch 在后台计算一系列优化步骤。
因此在实践中,你通常会希望预先编译一次,然后使用已经编译好的模型进行训练或推理。
def create_and_train_non_compiled_model(epochs=NUM_EPOCHS,
learning_rate=LEARNING_RATE,
disable_progress_bar=False):
"""
Create and train a non-compiled PyTorch model.
"""
model, _ = create_model()
model.to(device)
loss_fn = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(),
lr=learning_rate)
results = train(model=model,
train_dataloader=train_dataloader,
test_dataloader=test_dataloader,
loss_fn=loss_fn,
optimizer=optimizer,
epochs=epochs,
device=device,
disable_progress_bar=disable_progress_bar)
return results
def create_compiled_model():
"""
Create a compiled PyTorch model and return it.
"""
model, _ = create_model()
model.to(device)
compile_start_time = time.time()
### New in PyTorch 2.x ###
compiled_model = torch.compile(model)
##########################
compile_end_time = time.time()
compile_time = compile_end_time - compile_start_time
print(f"Time to compile: {compile_time} | Note: The first time you compile your model, the first few epochs will be slower than subsequent runs.")
return compiled_model
def train_compiled_model(model=compiled_model,
epochs=NUM_EPOCHS,
learning_rate=LEARNING_RATE,
disable_progress_bar=False):
"""
Train a compiled model and return the results.
"""
loss_fn = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(compiled_model.parameters(),
lr=learning_rate)
compile_results = train(model=model,
train_dataloader=train_dataloader,
test_dataloader=test_dataloader,
loss_fn=loss_fn,
optimizer=optimizer,
epochs=epochs,
device=device,
disable_progress_bar=disable_progress_bar)
return compile_results
4.1 实验3 - 多次运行,不编译¶
函数已准备好进行实验3和4!
让我们从实验3开始。
| 实验 | 模型 | 数据 | 周期数 | 批次大小 | 图像大小 | torch.compile() |
|---|---|---|---|---|---|---|
| 3(多运行) | ResNet50 | CIFAR10 | 3x5 | 128 | 224 | 否 |
我们将设置运行次数为3,周期数为5。
我们将创建一个空列表来存储结果,并在每次运行后将结果追加到该列表中。
注意: 运行以下代码可能需要一段时间,具体取决于您的GPU速度。对我来说,在Google Colab Pro上的NVIDIA A100上花费了20分钟,而在NVIDIA TITAN RTX上花费了大约49分钟。
# Run non-compiled model for multiple runs
NUM_RUNS = 3
NUM_EPOCHS = 5
# Create an empty list to store multiple run results
non_compile_results_multiple_runs = []
# Run non-compiled model for multiple runs
for i in tqdm(range(NUM_RUNS)):
print(f"[INFO] Run {i+1} of {NUM_RUNS} for non-compiled model")
results = create_and_train_non_compiled_model(epochs=NUM_EPOCHS, disable_progress_bar=True)
non_compile_results_multiple_runs.append(results)
0%| | 0/3 [00:00<?, ?it/s]
[INFO] Run 1 of 3 for non-compiled model Epoch: 1 | train_loss: 0.8242 | train_acc: 0.7136 | test_loss: 0.5486 | test_acc: 0.8124 | train_epoch_time: 185.1112 | test_epoch_time: 12.9925 Epoch: 2 | train_loss: 0.4415 | train_acc: 0.8479 | test_loss: 0.6415 | test_acc: 0.7829 | train_epoch_time: 185.0138 | test_epoch_time: 12.9690 Epoch: 3 | train_loss: 0.3229 | train_acc: 0.8882 | test_loss: 0.4486 | test_acc: 0.8488 | train_epoch_time: 185.0366 | test_epoch_time: 12.9433 Epoch: 4 | train_loss: 0.2433 | train_acc: 0.9151 | test_loss: 0.4376 | test_acc: 0.8596 | train_epoch_time: 185.0900 | test_epoch_time: 12.9465 Epoch: 5 | train_loss: 0.1785 | train_acc: 0.9379 | test_loss: 0.4305 | test_acc: 0.8641 | train_epoch_time: 185.0405 | test_epoch_time: 13.0102 [INFO] Run 2 of 3 for non-compiled model Epoch: 1 | train_loss: 0.8304 | train_acc: 0.7101 | test_loss: 0.6132 | test_acc: 0.7884 | train_epoch_time: 185.0911 | test_epoch_time: 13.0429 Epoch: 2 | train_loss: 0.4602 | train_acc: 0.8411 | test_loss: 0.6183 | test_acc: 0.7907 | train_epoch_time: 185.0738 | test_epoch_time: 12.9596 Epoch: 3 | train_loss: 0.3283 | train_acc: 0.8869 | test_loss: 0.4309 | test_acc: 0.8534 | train_epoch_time: 185.0462 | test_epoch_time: 12.9877 Epoch: 4 | train_loss: 0.2474 | train_acc: 0.9140 | test_loss: 0.4525 | test_acc: 0.8565 | train_epoch_time: 184.9521 | test_epoch_time: 12.9942 Epoch: 5 | train_loss: 0.1860 | train_acc: 0.9360 | test_loss: 0.6284 | test_acc: 0.8195 | train_epoch_time: 184.9911 | test_epoch_time: 12.9369 [INFO] Run 3 of 3 for non-compiled model Epoch: 1 | train_loss: 0.7915 | train_acc: 0.7246 | test_loss: 0.6102 | test_acc: 0.7894 | train_epoch_time: 184.9795 | test_epoch_time: 13.0175 Epoch: 2 | train_loss: 0.4394 | train_acc: 0.8477 | test_loss: 0.5958 | test_acc: 0.7968 | train_epoch_time: 184.9266 | test_epoch_time: 12.9909 Epoch: 3 | train_loss: 0.3156 | train_acc: 0.8893 | test_loss: 0.4299 | test_acc: 0.8547 | train_epoch_time: 185.1226 | test_epoch_time: 12.9396 Epoch: 4 | train_loss: 0.2371 | train_acc: 0.9163 | test_loss: 0.4185 | test_acc: 0.8608 | train_epoch_time: 184.9447 | test_epoch_time: 12.9673 Epoch: 5 | train_loss: 0.1739 | train_acc: 0.9389 | test_loss: 0.3797 | test_acc: 0.8805 | train_epoch_time: 184.9552 | test_epoch_time: 13.0328
现在我们已经有了实验3的结果列表,让我们遍历这些结果并创建一个包含所有结果的数据框。
然后,我们将通过按epoch编号(数据框的索引)分组并对结果取平均值,来计算3次运行的平均结果。
import pandas as pd
# 假设 results 是实验3的结果列表
results = [...] # 这里填充实际的结果数据
# 创建一个包含所有结果的数据框
df = pd.DataFrame(results)
# 按epoch编号分组并对结果取平均值
averaged_results = df.groupby(df.index).mean()
print(averaged_results)
# Go through non_compile_results_multiple_runs and create a dataframe for each run then concatenate them together
non_compile_results_dfs = []
for result in non_compile_results_multiple_runs:
result_df = pd.DataFrame(result)
non_compile_results_dfs.append(result_df)
non_compile_results_multiple_runs_df = pd.concat(non_compile_results_dfs)
# Get the averages across the multiple runs
non_compile_results_multiple_runs_df = non_compile_results_multiple_runs_df.groupby(non_compile_results_multiple_runs_df.index).mean()
non_compile_results_multiple_runs_df
| train_loss | train_acc | test_loss | test_acc | train_epoch_time | test_epoch_time | |
|---|---|---|---|---|---|---|
| 0 | 0.815352 | 0.716103 | 0.590690 | 0.796710 | 185.060622 | 13.017663 |
| 1 | 0.447013 | 0.845567 | 0.618526 | 0.790150 | 185.004740 | 12.973144 |
| 2 | 0.322255 | 0.888117 | 0.436471 | 0.852321 | 185.068499 | 12.956863 |
| 3 | 0.242587 | 0.915120 | 0.436207 | 0.858946 | 184.995601 | 12.969341 |
| 4 | 0.179439 | 0.937612 | 0.479547 | 0.854727 | 184.995575 | 12.993280 |
太好了!
我们稍后再来检查这些,现在让我们继续进行实验4。
4.2 实验 4 - 多次运行,包含编译¶
实验 4 的时间到了。
运行一个已编译的模型进行多次运行。
| 实验 | 模型 | 数据集 | 周期数 | 批量大小 | 图像尺寸 | torch.compile() |
|---|---|---|---|---|---|---|
| 4 (多运行) | ResNet50 | CIFAR10 | 3x5 | 128 | 224 | 是 |
我们可以使用之前创建的 create_compiled_model() 和 train_compiled_model() 函数来实现这一点。
首先,我们将先创建编译好的模型,然后对其进行 3 次训练。
我们不太关心模型的结果(损失和准确性),而是更关心它需要多长时间。
我们之所以一开始就编译它,是因为 PyTorch 只需要运行一次优化步骤(这可能需要一些时间),然后就可以在后续的运行中重用它们。
我们还将像之前一样创建一个空列表,用于存储模型在一系列运行中的结果。
注意: 运行以下代码可能需要一段时间,具体取决于您的 GPU 速度。对我来说,在 Google Colab Pro 上的 NVIDIA A100 上需要 18 分钟,而在 NVIDIA TITAN RTX 上大约需要 45 分钟。
# Create compiled model
compiled_model = create_compiled_model()
# Create an empty list to store compiled model results
compiled_results_multiple_runs = []
# Run compiled model for multiple runs
for i in tqdm(range(NUM_RUNS)):
print(f"[INFO] Run {i+1} of {NUM_RUNS} for compiled model")
# Train the compiled model (note: the model will only be compiled once and then re-used for subsequent runs)
results = train_compiled_model(model=compiled_model, epochs=NUM_EPOCHS, disable_progress_bar=True)
compiled_results_multiple_runs.append(results)
Time to compile: 0.001275777816772461 | Note: The first time you compile your model, the first few epochs will be slower than subsequent runs.
0%| | 0/3 [00:00<?, ?it/s]
[INFO] Run 1 of 3 for compiled model Epoch: 1 | train_loss: 0.8026 | train_acc: 0.7192 | test_loss: 0.6995 | test_acc: 0.7650 | train_epoch_time: 194.3336 | test_epoch_time: 20.6106 Epoch: 2 | train_loss: 0.4440 | train_acc: 0.8483 | test_loss: 0.5565 | test_acc: 0.8089 | train_epoch_time: 169.3882 | test_epoch_time: 10.8076 Epoch: 3 | train_loss: 0.3208 | train_acc: 0.8896 | test_loss: 0.4164 | test_acc: 0.8620 | train_epoch_time: 169.9283 | test_epoch_time: 10.8361 Epoch: 4 | train_loss: 0.2329 | train_acc: 0.9197 | test_loss: 0.3635 | test_acc: 0.8792 | train_epoch_time: 169.8744 | test_epoch_time: 10.9050 Epoch: 5 | train_loss: 0.1803 | train_acc: 0.9369 | test_loss: 0.4387 | test_acc: 0.8587 | train_epoch_time: 169.6391 | test_epoch_time: 10.8240 [INFO] Run 2 of 3 for compiled model Epoch: 1 | train_loss: 0.1875 | train_acc: 0.9347 | test_loss: 0.4187 | test_acc: 0.8714 | train_epoch_time: 169.4814 | test_epoch_time: 10.8180 Epoch: 2 | train_loss: 0.1288 | train_acc: 0.9550 | test_loss: 0.4333 | test_acc: 0.8698 | train_epoch_time: 169.4503 | test_epoch_time: 10.8263 Epoch: 3 | train_loss: 0.0950 | train_acc: 0.9672 | test_loss: 0.4867 | test_acc: 0.8650 | train_epoch_time: 169.6038 | test_epoch_time: 10.8199 Epoch: 4 | train_loss: 0.0943 | train_acc: 0.9675 | test_loss: 0.3714 | test_acc: 0.8966 | train_epoch_time: 169.5757 | test_epoch_time: 10.8221 Epoch: 5 | train_loss: 0.0537 | train_acc: 0.9821 | test_loss: 0.5002 | test_acc: 0.8701 | train_epoch_time: 169.5253 | test_epoch_time: 10.8426 [INFO] Run 3 of 3 for compiled model Epoch: 1 | train_loss: 0.0705 | train_acc: 0.9751 | test_loss: 0.4333 | test_acc: 0.8839 | train_epoch_time: 169.4846 | test_epoch_time: 10.9057 Epoch: 2 | train_loss: 0.0595 | train_acc: 0.9802 | test_loss: 0.4341 | test_acc: 0.8904 | train_epoch_time: 169.6055 | test_epoch_time: 10.8804 Epoch: 3 | train_loss: 0.0405 | train_acc: 0.9859 | test_loss: 0.4478 | test_acc: 0.8901 | train_epoch_time: 169.5788 | test_epoch_time: 10.8449 Epoch: 4 | train_loss: 0.0365 | train_acc: 0.9873 | test_loss: 0.5382 | test_acc: 0.8765 | train_epoch_time: 169.6732 | test_epoch_time: 10.9873 Epoch: 5 | train_loss: 0.0422 | train_acc: 0.9854 | test_loss: 0.5057 | test_acc: 0.8832 | train_epoch_time: 169.6618 | test_epoch_time: 10.8969
实验4完成!
现在让我们将结果汇总到一个数据框中,并计算每个运行(run)的平均值(我们将通过按数据框的索引号,即epoch号进行分组来实现这一点)。
# Go through compile_results_multiple_runs and create a dataframe for each run then concatenate them together
compile_results_dfs = []
for result in compiled_results_multiple_runs:
result_df = pd.DataFrame(result)
compile_results_dfs.append(result_df)
compile_results_multiple_runs_df = pd.concat(compile_results_dfs)
# Get the averages across the multiple runs
compile_results_multiple_runs_df = compile_results_multiple_runs_df.groupby(compile_results_multiple_runs_df.index).mean() # .index = groupby the epoch number
compile_results_multiple_runs_df
| train_loss | train_acc | test_loss | test_acc | train_epoch_time | test_epoch_time | |
|---|---|---|---|---|---|---|
| 0 | 0.353548 | 0.876332 | 0.517181 | 0.840124 | 177.766548 | 14.111428 |
| 1 | 0.210781 | 0.927845 | 0.474630 | 0.856375 | 169.481367 | 10.838063 |
| 2 | 0.152098 | 0.947577 | 0.450293 | 0.872396 | 169.703638 | 10.833619 |
| 3 | 0.121230 | 0.958177 | 0.424376 | 0.884065 | 169.707751 | 10.904810 |
| 4 | 0.092080 | 0.968116 | 0.481520 | 0.870649 | 169.608708 | 10.854486 |
4.3 比较实验3和实验4的结果¶
多轮实验已完成!
让我们来检查一下结果。
我们可以使用之前创建的 plot_mean_epoch_times() 函数来进行检查。
这次我们将 multi_runs 参数设置为 True,以便我们的图表反映出我们正在绘制多轮实验的结果。
我们还要确保有一个目录可以保存图表。
# Create a directory to save the multi-run figure to
os.makedirs("pytorch_2_results/figures", exist_ok=True)
# Create a path to save the figure for multiple runs
save_path_multi_run = f"pytorch_2_results/figures/multi_run_{GPU_NAME}_{MODEL_NAME}_{DATASET_NAME}_{IMAGE_SIZE}_train_epoch_time.png"
# Plot the mean epoch times for experiment 3 and 4
plot_mean_epoch_times(non_compiled_results=non_compile_results_multiple_runs_df,
compiled_results=compile_results_multiple_runs_df,
multi_runs=True,
num_runs=NUM_RUNS,
save_path=save_path_multi_run,
save=True)
Mean train epoch time difference: -7.443% (negative means faster) Mean test epoch time difference: -11.351% (negative means faster) [INFO] Plot saved to pytorch_2_results/figures/multi_run_NVIDIA_TITAN_RTX_ResNet50_CIFAR10_224_train_epoch_time.png

不错!
看来在多次运行中,编译后的模型表现略胜一筹。
这可能是因为在单次运行(使用较少的 epoch 数)时,编译模型需要花费相当多的时间来完成第一个 epoch 的运行。
然而,当模型已经编译完毕并开始进行更长时间的训练时,幕后优化带来的加速效果就开始显现。
一个可能的扩展实验是让模型训练更长时间,比如 100 个 epoch,看看结果如何比较。
4.4 将多次运行的结果及GPU详情保存到文件¶
我们还将实验3和实验4的结果数据框保存到文件中,以防我们日后需要检查它们或将其与其他类型的模型进行比较。
# Make a directory for multi_run results
import os
pytorch_2_results_dir = "pytorch_2_results"
pytorch_2_multi_run_results_dir = f"{pytorch_2_results_dir}/multi_run_results"
os.makedirs(pytorch_2_multi_run_results_dir, exist_ok=True)
# Create filenames for each of the dataframes
save_name_for_multi_run_non_compiled_results = f"multi_run_non_compiled_results_{NUM_RUNS}_runs_{DATASET_NAME}_{MODEL_NAME}_{GPU_NAME}.csv"
save_name_for_multi_run_compiled_results = f"multi_run_compiled_results_{NUM_RUNS}_runs_{DATASET_NAME}_{MODEL_NAME}_{GPU_NAME}.csv"
# Create filepaths to save the results to
multi_run_no_compile_save_path = f"{pytorch_2_multi_run_results_dir}/{save_name_for_non_compiled_results}"
multi_run_compile_save_path = f"{pytorch_2_multi_run_results_dir}/{save_name_for_compiled_results}"
print(f"[INFO] Saving experiment 3 non-compiled results to: {multi_run_no_compile_save_path}")
print(f"[INFO] Saving experiment 4 compiled results to: {multi_run_compile_save_path}")
# Save the results
non_compile_results_multiple_runs_df.to_csv(multi_run_no_compile_save_path)
compile_results_multiple_runs_df.to_csv(multi_run_compile_save_path)
[INFO] Saving experiment 3 non-compiled results to: pytorch_2_results/multi_run_results/single_run_non_compiled_results_CIFAR10_ResNet50_NVIDIA_TITAN_RTX.csv [INFO] Saving experiment 4 compiled results to: pytorch_2_results/multi_run_results/single_run_compiled_results_CIFAR10_ResNet50_NVIDIA_TITAN_RTX.csv
5. 可能的改进和扩展¶
我们已经探讨了 torch.compile() 的基本原理,并编写了几个实验代码来测试其性能。
但还有更多我们可以做的事情。
正如我们所讨论的,PyTorch 2.0 和 torch.compile() 中许多加速效果来自于使用更新的 GPU(例如 A100 及以上)以及尽可能充分利用 GPU(更大的批次大小、更大的模型大小)。
为了进一步加速,我建议研究/尝试以下内容:
- 更强大的 CPU - 我有一个隐约的感觉,Google Colab 实例可能限制在 2 个 CPU 核心,使用更多 CPU 可能会提高加速效果。这可以通过 PyTorch Profiler(一个用于找出各个进程占用时间的工具)来跟踪。
- 使用混合精度训练 - 较新的 GPU 能够处理不同精度类型(例如
torch.float16和torch.bfloat16),从而实现更快的训练和推理。我怀疑通过使用混合精度训练,你会看到比我们这里看到的更大的加速效果。更多关于这方面的信息,请参阅 PyTorch 自动混合精度的文档(也称为 AMP)。 - 基于 Transformer 的模型可能比卷积模型获得更多的 相对 加速 - PyTorch 2.0 包含了 加速 Transformer 模型的稳定版本(使用注意力机制的模型)。主要的加速来自于对
scaled_dot_product_attention()的改进实现,它会根据你使用的硬件自动选择最佳的注意力版本。更多信息可以参见 专门的 PyTorch 教程。 - 训练更长时间 - 如前所述,
torch.compile()带来的加速效果在训练更长时间时可能更为明显。一个很好的练习是训练更多轮次,潜在地使用不同的数据集和不同的模型(例如 Transformer),并比较加速效果。
6. 进一步学习的资源¶
我发现以下资源对于学习 PyTorch 2.0 及其即将推出的功能非常有帮助。
- PyTorch 2.0 发布博客文章。
- PyTorch 2.0 发行说明(博客文章)。
- 以及 GitHub 发行说明(这里有很多信息!)。
- PyTorch 默认设备上下文管理器文档。
- PyTorch 2.0 YouTube 视频介绍(由我本人创建)。
- 查看 Sebastian Raschka 的提示,通过先执行一个示例批次(预热模型)再继续进行进一步训练来改进
torch.compile()(这解释了多次运行时速度提升的原因)。