09. PyTorch 模型部署¶
欢迎来到第三阶段项目:PyTorch 模型部署!
我们的 FoodVision Mini 项目已经取得了长足的进展。
但到目前为止,我们的 PyTorch 模型还只能供我们个人使用。
不如让我们将 FoodVision Mini 变为现实,让它公开可用?
换句话说,我们将把 FoodVision Mini 模型部署到互联网上,作为一个可用的应用程序!

在我的午餐上尝试已部署的 FoodVision Mini 版本(我们即将构建的内容)。模型也预测对了 🍣!
什么是机器学习模型部署?¶
机器学习模型部署 是将你的机器学习模型提供给其他人或系统使用的过程。
其他人可以是能够以某种方式与你的模型互动的个人。
例如,某人使用智能手机拍摄食物照片,然后通过我们的 FoodVision Mini 模型将其分类为披萨、牛排或寿司。
其他系统可能是另一个程序、应用,甚至是另一个模型,它们与你的机器学习模型进行交互。
例如,银行数据库可能依赖机器学习模型在转账前预测交易是否存在欺诈行为。
或者操作系统可能根据机器学习模型对某人在特定时间段内通常使用的电量进行预测,从而降低资源消耗。
这些应用场景可以混合搭配。
例如,特斯拉汽车的计算机视觉系统将与车辆的路线规划程序(另一个系统)交互,然后路线规划程序会从驾驶员(其他人)那里获取输入和反馈。
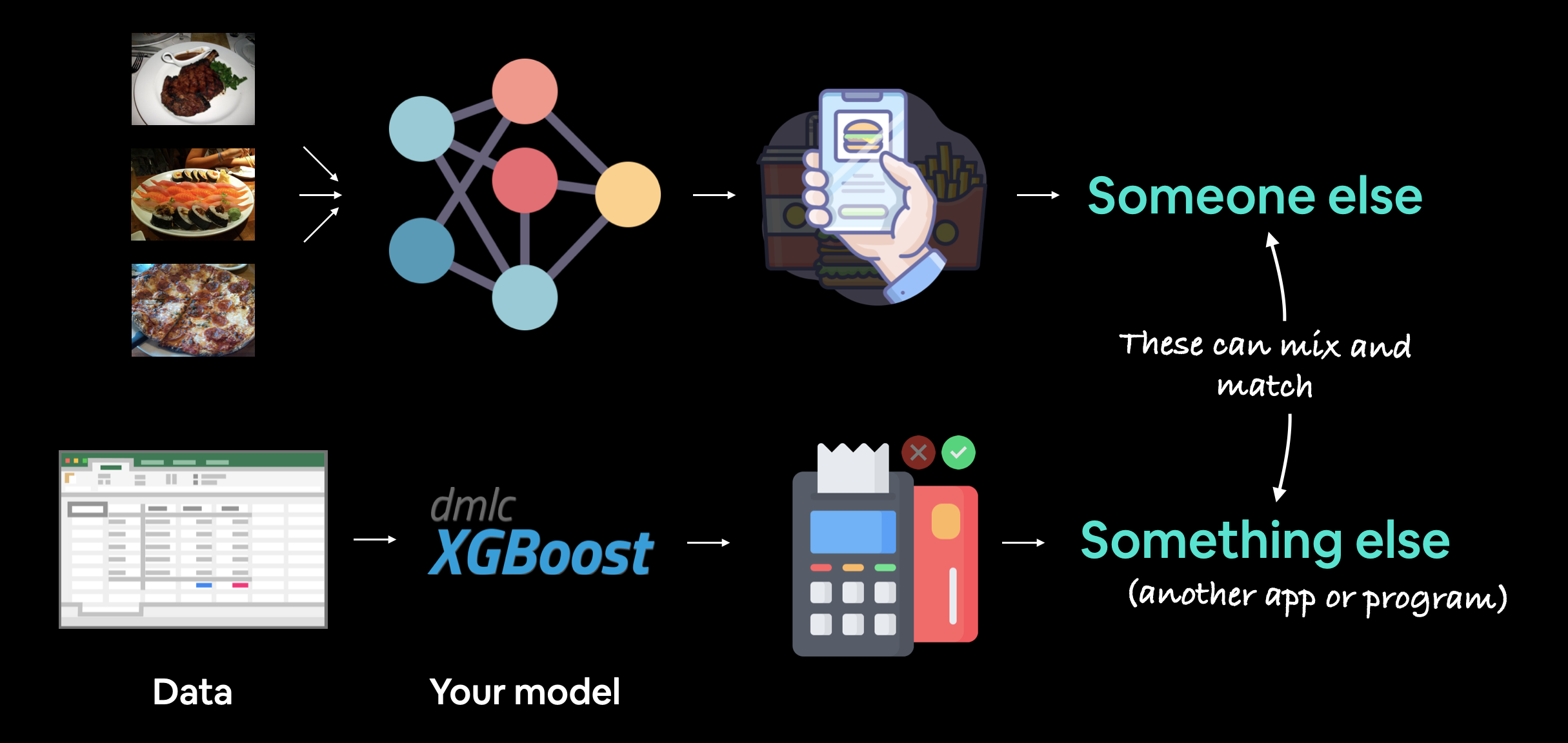
机器学习模型部署涉及将你的模型提供给其他人或系统使用。例如,某人可能将你的模型作为食物识别应用(如 FoodVision Mini 或 Nutrify)的一部分。而其他系统可能是另一个模型或程序使用你的模型,例如银行系统使用机器学习模型来检测交易是否存在欺诈行为。
为什么部署机器学习模型?¶
机器学习中最重要的问题之一是:

部署模型与训练模型同样重要。
因为尽管你可以通过精心设计的测试集评估或可视化结果来大致了解模型的功能,但你永远无法真正知道它在实际应用中的表现如何,直到你将其发布到真实环境中。
让从未使用过你的模型的人与之交互,往往会揭示你在训练过程中从未考虑过的边缘情况。
例如,如果有人向我们的FoodVision Mini模型上传了一张不是食物的照片,会发生什么?
一个解决方案是创建另一个模型,首先将图像分类为“食物”或“非食物”,并将目标图像首先通过该模型(这就是Nutrify所做的)。
然后,如果图像是“食物”,它将进入我们的FoodVision Mini模型并被分类为披萨、牛排或寿司。
如果是“非食物”,则显示一条消息。
但如果这些预测是错误的呢?
那时会发生什么?
你可以看到这些问题可能会持续下去。
因此,这凸显了模型部署的重要性:它帮助你发现模型在训练/测试过程中不明显的错误。
我们在01. PyTorch工作流程中介绍了PyTorch工作流程。但一旦你有了一个好的模型,部署是一个很好的下一步。监控涉及到如何处理最重要的数据分割:来自现实世界的数据。有关部署和监控的更多资源,请参阅PyTorch额外资源。
不同类型的机器学习模型部署¶
关于不同类型的机器学习模型部署,可以写成整本书(实际上,PyTorch 额外资源中列出了许多优秀的书籍)。
而且这个领域在最佳实践方面仍在不断发展。
但我喜欢从这个问题开始:
"我的机器学习模型最理想的应用场景是什么?"
然后从那里逆向思考。
当然,你可能事先并不知道这一点。但你足够聪明,能够想象这些情景。
以 FoodVision Mini 为例,我们理想的场景可能是:
- 某人在移动设备上拍照(通过应用程序或网页浏览器)。
- 预测结果迅速返回。
很简单。
所以我们有两个主要标准:
- 模型应该能在移动设备上运行(这意味着会有一些计算限制)。
- 模型应该能快速做出预测(因为慢速的应用程序是无趣的)。
当然,根据你的使用场景,你的需求可能会有所不同。
你可能会注意到上述两点可以分解为另外两个问题:
- 它将部署在哪里? - 即,它将存储在哪里?
- 它将如何运行? - 即,它是立即返回预测结果,还是稍后返回?
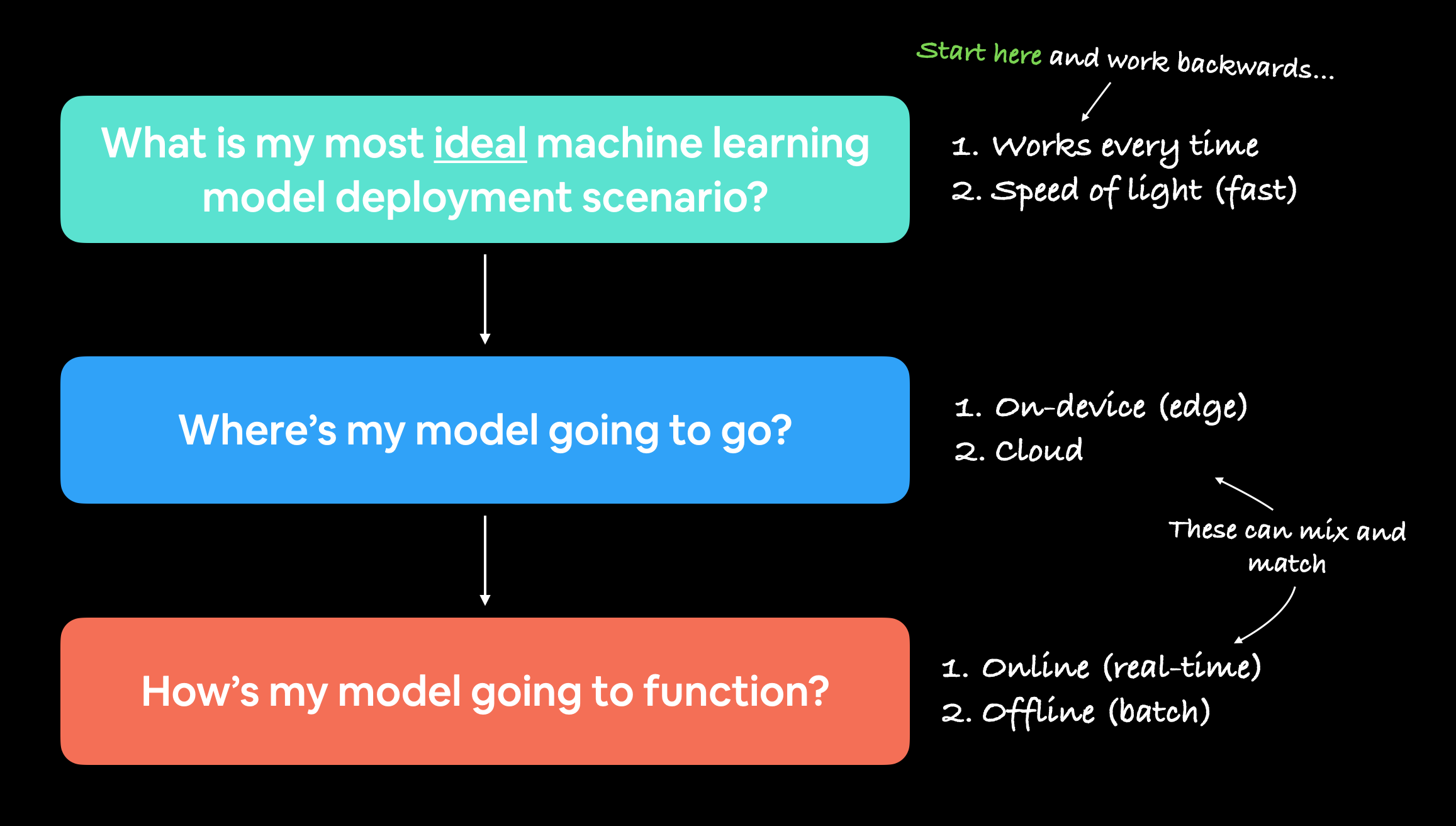
开始部署机器学习模型时,从询问最理想的应用场景开始,然后逆向思考,询问模型将部署在哪里,以及它将如何运行,这是有帮助的。
它将何去何从?¶
当你部署机器学习模型时,它将位于何处?
这里的主要争议通常在于设备上(也称为边缘/在浏览器中)或云端(一台计算机/服务器,并非实际调用模型的设备)。
两者各有优缺点。
| 部署位置 | 优点 | 缺点 |
|---|---|---|
| 设备上(边缘/在浏览器中) | 速度非常快(因为数据不离开设备) | 计算能力有限(较大的模型运行时间较长) |
| 保护隐私(数据无需离开设备) | 存储空间有限(需要较小的模型尺寸) | |
| 无需互联网连接(有时) | 通常需要设备特定的技能 | |
| 云端 | 近乎无限的计算能力(可根据需要扩展) | 成本可能失控(如果未实施适当的扩展限制) |
| 部署一个模型并在各处使用(通过API) | 预测可能较慢,因为数据需要离开设备并返回(网络延迟) | |
| 与现有云生态系统链接 | 数据必须离开设备(可能引发隐私问题) |
这些细节还有更多,但我在额外课程中留下了资源,供你深入了解。
让我们举个例子。
如果我们正在将FoodVision Mini部署为一个应用程序,我们希望它表现良好且快速。
那么我们更喜欢哪种模型?
- 一个在设备上运行的模型,准确率为95%,每次预测的推理时间(延迟)为一秒。
- 一个在云端运行的模型,准确率为98%,每次预测的推理时间为10秒(更大、更好的模型,但计算时间更长)。
这些数字是我编造的,但它们展示了设备上和云端之间可能存在的差异。
选项1可能是一个较小、性能较低的模型,因为它能够适应移动设备,所以运行速度快。
选项2可能是一个更大、性能更高的模型,它需要更多的计算和存储,但由于我们必须将数据发送出设备并返回(因此尽管实际预测可能很快,但网络时间和数据传输必须考虑在内),所以运行时间稍长。
对于FoodVision Mini,我们可能会倾向于选择选项1,因为性能的小幅下降远不及更快的推理速度重要。
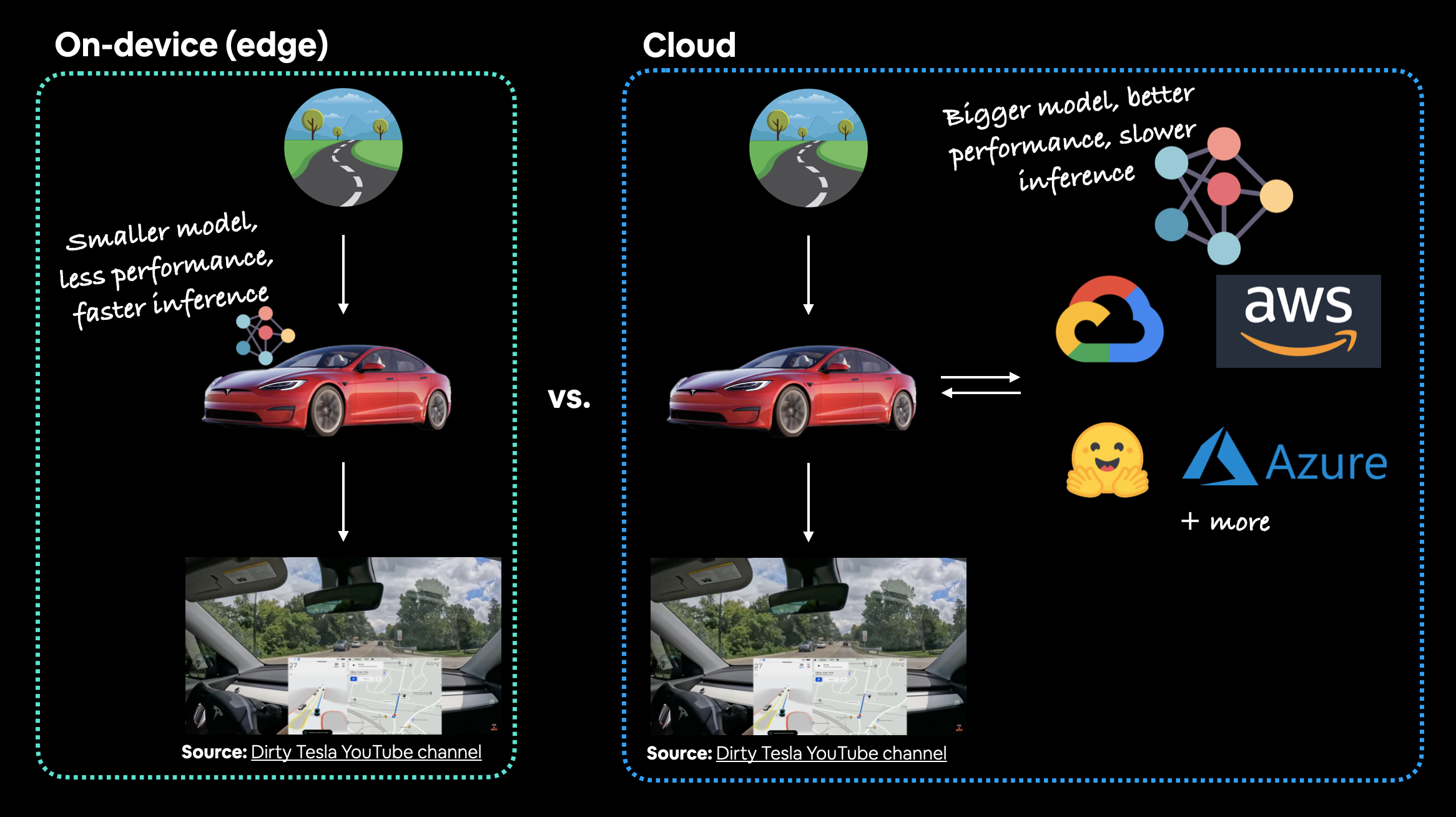
以特斯拉汽车的计算机视觉系统为例,哪种更好?一个在设备上表现良好的较小模型(模型在汽车上),还是一个在云端表现更好的较大模型?在这种情况下,你肯定会更倾向于模型在汽车上。数据从汽车到云端再返回汽车所需的额外网络时间根本不值得(或者在信号差的地区甚至不可能)。
注意: 要完整体验将PyTorch模型部署到边缘设备的情景,请参阅PyTorch教程,实现树莓派上的实时推理(30fps+),使用计算机视觉模型。
功能如何实现?¶
回到理想的用例,当你部署机器学习模型时,它应该如何工作?
比如说,你希望立即得到预测结果吗?
还是说,稍后得到预测结果也可以?
这两种情况通常被称为:
- 在线(实时) - 预测/推理立即发生。例如,某人上传一张图片,图片被处理并返回预测结果,或者某人进行购买,模型验证交易非欺诈,购买得以完成。
- 离线(批处理) - 预测/推理定期发生。例如,照片应用程序在移动设备充电时将你的图片分类为不同的类别(如海滩、用餐时间、家庭、朋友)。
注意: “批处理”指的是一次对多个样本进行推理。然而,为了增加一点混淆,批处理既可以立即/在线发生(同时对多张图片进行分类),也可以离线发生(同时对多张图片进行预测/训练)。
主要区别在于:预测是立即进行还是定期进行。
定期的时间尺度也可以不同,从每隔几秒到每隔几小时或几天。
你也可以混合使用这两种方式。
在 FoodVision Mini 的情况下,我们希望推理管道在线(实时)进行,这样当有人上传披萨、牛排或寿司的图片时,预测结果会立即返回(如果比实时慢,体验会变得乏味)。
但对于我们的训练管道,可以采用批处理(离线)方式,这也是我们在前几章中一直在做的。
部署机器学习模型的方法¶
我们已经讨论了几种部署机器学习模型的选项(设备端和云端)。
每种选项都有其特定的要求:
| 工具/资源 | 部署类型 |
| ----- | ----- |
| Google 的 ML Kit | 设备端(Android 和 iOS) |
| Apple 的 Core ML 和 coremltools Python 包 | 设备端(所有 Apple 设备) |
| Amazon Web Service (AWS) 的 Sagemaker | 云端 |
| Google Cloud 的 Vertex AI | 云端 |
| Microsoft 的 Azure Machine Learning | 云端 |
| Hugging Face Spaces | 云端 |
| 使用 FastAPI 的 API | 云端/自托管服务器 |
| 使用 TorchServe 的 API | 云端/自托管服务器 |
| ONNX (Open Neural Network Exchange) | 多种/通用 |
| 更多... |
注意: 应用程序编程接口(API) 是两个(或更多)计算机程序相互交互的一种方式。例如,如果你的模型部署为 API,你可以编写一个程序向其发送数据并接收预测结果。
你选择的选项将高度依赖于你正在构建的内容/你正在与谁合作。
但有这么多的选项,可能会非常令人畏惧。
所以最好从小规模开始,保持简单。
其中一种最好的方法是使用 Gradio 将你的机器学习模型转化为演示应用,然后将其部署在 Hugging Face Spaces 上。
我们稍后将通过 FoodVision Mini 来实现这一点。
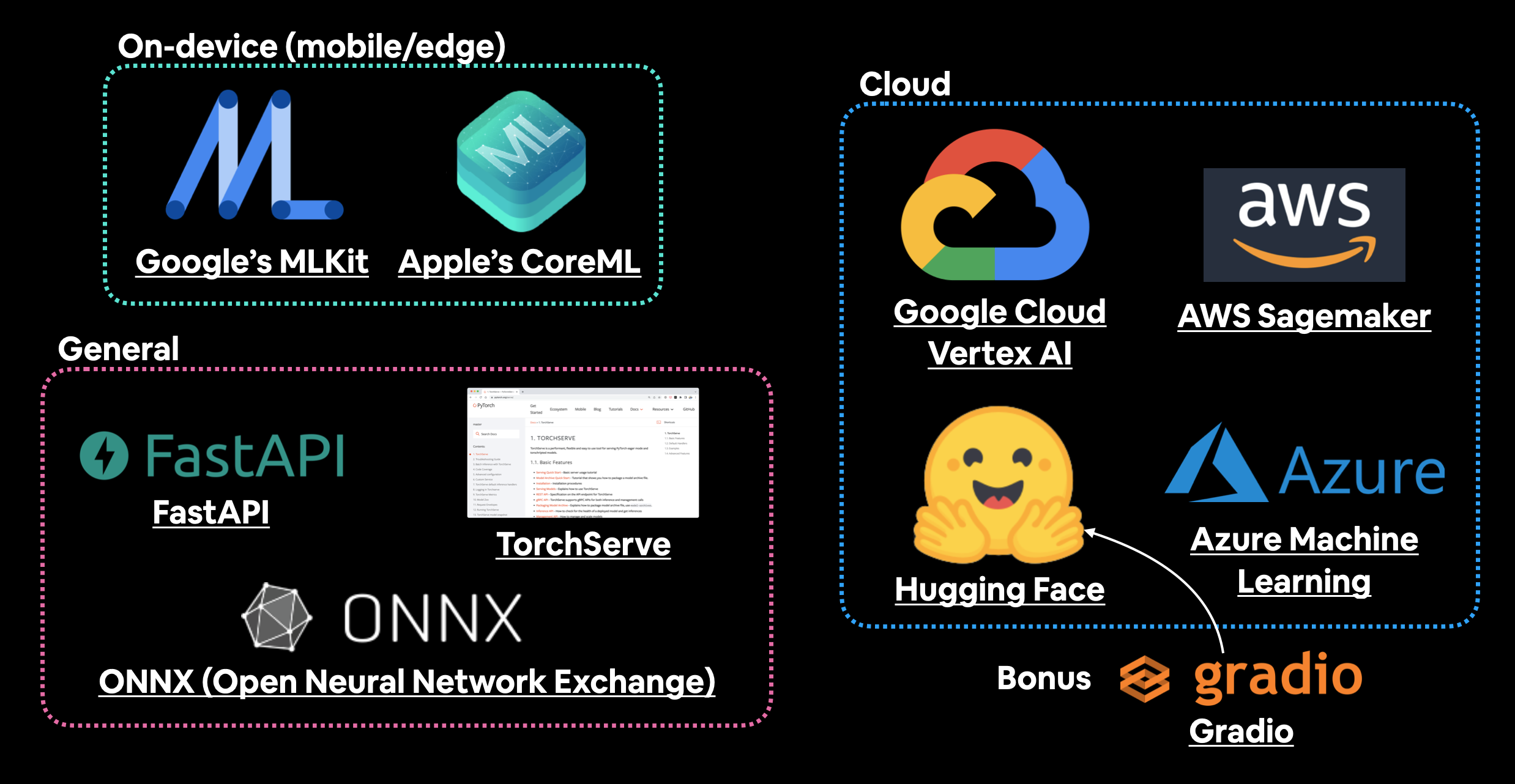
一些托管和部署机器学习模型的工具和地点。还有很多我遗漏的,如果你想添加更多,请在 GitHub 讨论 中留言。
我们将要涵盖的内容¶
关于部署机器学习模型的话题已经谈得够多了。
让我们成为机器学习工程师,并实际部署一个模型。
我们的目标是通过一个演示性的 Gradio 应用来部署我们的 FoodVision 模型,并达到以下指标:
- 性能: 95% 以上的准确率。
- 速度: 实时推理速度达到 30FPS 以上(每个预测的延迟低于约 0.03 秒)。
我们将首先进行一个实验,比较我们迄今为止最好的两个模型:EffNetB2 和 ViT 特征提取器。
然后我们将部署最接近我们目标指标的那个模型。
最后,我们将以一个(大)惊喜作为结尾。
| 主题 | 内容 |
|---|---|
| 0. 环境设置 | 我们在过去几节中编写了不少有用的代码,让我们下载它并确保我们可以再次使用它。 |
| 1. 获取数据 | 让我们下载 pizza_steak_sushi_20_percent.zip 数据集,以便我们可以在同一数据集上训练我们之前表现最好的模型。 |
| 2. FoodVision Mini 模型部署实验概述 | 即使在第三个里程碑项目中,我们仍然会运行多个实验,以查看哪个模型(EffNetB2 或 ViT)最接近我们的目标指标。 |
| 3. 创建一个 EffNetB2 特征提取器 | 在 07. PyTorch 实验跟踪 中,EfficientNetB2 特征提取器在我们的披萨、牛排、寿司数据集上表现最好,让我们重新创建它作为部署的候选模型。 |
| 4. 创建一个 ViT 特征提取器 | 在 08. PyTorch 论文复现 中,ViT 特征提取器在我们迄今为止的披萨、牛排、寿司数据集上表现最好,让我们重新创建它作为与 EffNetB2 并列的部署候选模型。 |
| 5. 使用我们训练好的模型进行预测并计时 | 我们已经构建了两个迄今为止表现最好的模型,让我们用它们进行预测并跟踪结果。 |
| 6. 比较模型结果、预测时间和大小 | 让我们比较我们的模型,看看哪个在目标上表现最好。 |
| 7. 通过创建 Gradio 演示将 FoodVision Mini 变为现实 | 我们的模型中有一个在目标上表现更好,所以让我们把它变成一个可用的应用演示! |
| 8. 将我们的 FoodVision Mini Gradio 演示变成一个可部署的应用 | 我们的 Gradio 应用演示在本地运行良好,让我们为部署做好准备! |
| 9. 将我们的 Gradio 演示部署到 HuggingFace Spaces | 让我们将 FoodVision Mini 带到网络上,并使其公开可访问! |
| 10. 创建一个大惊喜 | 我们已经构建了 FoodVision Mini,现在是时候提升一个档次了。 |
| 11. 部署我们的 BIG 惊喜 | 部署一个应用很有趣,我们再来一个怎么样? |
在哪里可以获得帮助?¶
本课程的所有资料都可以在GitHub上找到。
如果你遇到问题,可以在课程的GitHub讨论页面上提问。
当然,还有PyTorch文档和PyTorch开发者论坛,这是所有PyTorch相关问题的非常有帮助的地方。
0. 环境设置¶
与之前一样,让我们确保我们已安装了本节所需的所有模块。
我们将导入在 05. PyTorch Going Modular 中创建的 Python 脚本(例如 data_setup.py 和 engine.py)。
为此,我们将从 pytorch-deep-learning 仓库 下载 going_modular 目录(如果尚未下载)。
如果尚未安装,我们还将获取 torchinfo 包。
torchinfo 将在后续帮助我们直观地展示模型结构。
并且由于我们后续将使用 torchvision v0.13 版本(自 2022 年 7 月起可用),我们将确保已安装最新版本。
注意: 如果您使用的是 Google Colab,并且尚未启用 GPU,现在可以通过
Runtime -> Change runtime type -> Hardware accelerator -> GPU来启用 GPU。
# For this notebook to run with updated APIs, we need torch 1.12+ and torchvision 0.13+
try:
import torch
import torchvision
assert int(torch.__version__.split(".")[1]) >= 12, "torch version should be 1.12+"
assert int(torchvision.__version__.split(".")[1]) >= 13, "torchvision version should be 0.13+"
print(f"torch version: {torch.__version__}")
print(f"torchvision version: {torchvision.__version__}")
except:
print(f"[INFO] torch/torchvision versions not as required, installing nightly versions.")
!pip3 install -U torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
import torch
import torchvision
print(f"torch version: {torch.__version__}")
print(f"torchvision version: {torchvision.__version__}")
torch version: 1.13.0.dev20220824+cu113 torchvision version: 0.14.0.dev20220824+cu113
注意: 如果你在使用 Google Colab,并且上面的单元格开始安装各种软件包,你可能需要在运行上面的单元格后重启运行时。重启后,你可以再次运行该单元格,并验证你已经安装了正确版本的
torch和torchvision。
现在我们将继续进行常规的导入,设置设备无关代码,这次我们还将从 GitHub 获取 helper_functions.py 脚本。
helper_functions.py 脚本包含我们在之前的章节中创建的几个函数:
set_seeds()用于设置随机种子(在 07. PyTorch 实验跟踪 第0节 中创建)。download_data()用于根据链接下载数据源(在 07. PyTorch 实验跟踪 第1节 中创建)。plot_loss_curves()用于检查我们模型的训练结果(在 04. PyTorch 自定义数据集 第7.8节 中创建)。
注意: 将
helper_functions.py脚本中的许多函数合并到going_modular/going_modular/utils.py中可能是一个更好的主意,也许这是你想尝试的扩展。
# Continue with regular imports
import matplotlib.pyplot as plt
import torch
import torchvision
from torch import nn
from torchvision import transforms
# Try to get torchinfo, install it if it doesn't work
try:
from torchinfo import summary
except:
print("[INFO] Couldn't find torchinfo... installing it.")
!pip install -q torchinfo
from torchinfo import summary
# Try to import the going_modular directory, download it from GitHub if it doesn't work
try:
from going_modular.going_modular import data_setup, engine
from helper_functions import download_data, set_seeds, plot_loss_curves
except:
# Get the going_modular scripts
print("[INFO] Couldn't find going_modular or helper_functions scripts... downloading them from GitHub.")
!git clone https://github.com/mrdbourke/pytorch-deep-learning
!mv pytorch-deep-learning/going_modular .
!mv pytorch-deep-learning/helper_functions.py . # get the helper_functions.py script
!rm -rf pytorch-deep-learning
from going_modular.going_modular import data_setup, engine
from helper_functions import download_data, set_seeds, plot_loss_curves
最后,我们将设置设备无关的代码,以确保我们的模型在GPU上运行。
device = "cuda" if torch.cuda.is_available() else "cpu"
device
'cuda'
1. 获取数据¶
我们在08. PyTorch 论文复现中比较了我们自己构建的 Vision Transformer (ViT) 特征提取器模型与在07. PyTorch 实验跟踪中创建的 EfficientNetB2 (EffNetB2) 特征提取器模型。
我们发现两者在比较中存在细微差异。
EffNetB2 模型是在 Food101 数据集的 20% 的披萨、牛排和寿司数据上训练的,而 ViT 模型则是在 10% 的数据上训练的。
由于我们的目标是部署最适合 FoodVision Mini 问题的模型,让我们首先下载20% 的披萨、牛排和寿司数据集,并在其上训练一个 EffNetB2 特征提取器和 ViT 特征提取器,然后比较这两个模型。
这样我们就能进行苹果对苹果的比较(一个模型在某个数据集上训练,另一个模型在相同数据集上训练)。
注意: 我们下载的数据集是整个 Food101 数据集(101 种食物类别,每类 1,000 张图片)的一个样本。具体来说,20% 指的是从披萨、牛排和寿司类别中随机选择的 20% 的图片。你可以在
extras/04_custom_data_creation.ipynb中查看这个数据集是如何创建的,以及在 04. PyTorch 自定义数据集第 1 节中查看更多细节。
我们可以使用在07. PyTorch 实验跟踪第 1 节中创建的 helper_functions.py 中的 download_data() 函数来下载数据。
# Download pizza, steak, sushi images from GitHub
data_20_percent_path = download_data(source="https://github.com/mrdbourke/pytorch-deep-learning/raw/main/data/pizza_steak_sushi_20_percent.zip",
destination="pizza_steak_sushi_20_percent")
data_20_percent_path
[INFO] data/pizza_steak_sushi_20_percent directory exists, skipping download.
PosixPath('data/pizza_steak_sushi_20_percent')
太好了!
现在我们有了数据集,接下来创建训练和测试路径吧。
# Setup directory paths to train and test images
train_dir = data_20_percent_path / "train"
test_dir = data_20_percent_path / "test"
2. FoodVision Mini 模型部署实验概述¶
理想的 FoodVision Mini 模型不仅表现出色,而且运行迅速。
我们希望模型尽可能接近实时性能。
在这种情况下,实时性能指的是约 30 FPS(每秒帧数),因为这是人类眼睛能看到的速度(对此有争议,但我们将 30 FPS 作为基准)。
对于分类三种不同类别(披萨、牛排和寿司),我们希望模型达到 95% 以上的准确率。
当然,更高的准确率会更好,但这可能会牺牲速度。
因此,我们的目标是:
- 性能 - 一个准确率超过 95% 的模型。
- 速度 - 一个能够以约 30 FPS 的速度分类图像的模型(每张图像的推理时间为 0.03 秒,也称为延迟)。
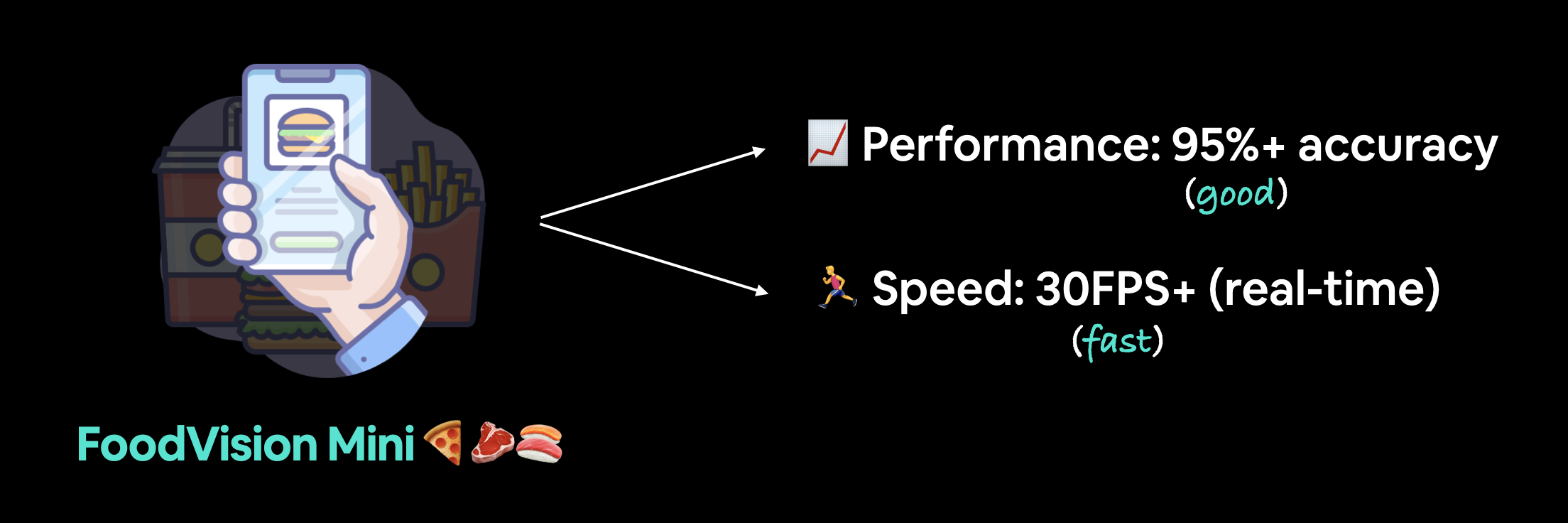
FoodVision Mini 部署目标。我们希望有一个快速且表现良好的预测模型(因为慢速的应用是无趣的)。
我们将重点放在速度上,这意味着,我们更倾向于一个在 30 FPS 下达到 90% 以上准确率的模型,而不是一个在 10 FPS 下达到 95% 以上准确率的模型。
为了尝试实现这些结果,让我们引入之前部分中表现最佳的模型:
- EffNetB2 特征提取器(简称 EffNetB2)- 最初在 07. PyTorch 实验跟踪部分 7.5 中创建,使用
torchvision.models.efficientnet_b2()并调整了classifier层。 - ViT-B/16 特征提取器(简称 ViT)- 最初在 08. PyTorch 论文复现部分 10 中创建,使用
torchvision.models.vit_b_16()并调整了head层。- 注意 ViT-B/16 代表“Vision Transformer Base,patch size 16”。
注意: “特征提取器模型”通常从一个在类似你的问题的数据集上预训练过的模型开始。预训练模型的基础层通常保持冻结(预训练的模式/权重保持不变),而一些顶层(或分类器/分类头)会根据你自己的数据进行定制训练。我们在 06. PyTorch 迁移学习部分 3.4 中介绍了特征提取器模型的概念。
3. 创建 EffNetB2 特征提取器¶
我们首先在 07. PyTorch 实验跟踪 第 7.5 节 中创建了一个 EffNetB2 特征提取器模型。
在该节的末尾,我们看到它的表现非常出色。
因此,现在我们在这里重新创建它,以便将其结果与在相同数据上训练的 ViT 特征提取器进行比较。
为此,我们可以:
- 将预训练权重设置为
weights=torchvision.models.EfficientNet_B2_Weights.DEFAULT,其中 "DEFAULT" 表示 "当前最佳可用"(或者可以使用weights="DEFAULT")。 - 使用
transforms()方法从权重中获取预训练模型的图像变换(我们需要这些变换,以便将我们的图像转换为与预训练的 EffNetB2 训练时相同的格式)。 - 通过将权重传递给
torchvision.models.efficientnet_b2的实例来创建一个预训练模型实例。 - 冻结模型中的基础层。
- 更新分类器头以适应我们自己的数据。
# 1. Setup pretrained EffNetB2 weights
effnetb2_weights = torchvision.models.EfficientNet_B2_Weights.DEFAULT
# 2. Get EffNetB2 transforms
effnetb2_transforms = effnetb2_weights.transforms()
# 3. Setup pretrained model
effnetb2 = torchvision.models.efficientnet_b2(weights=effnetb2_weights) # could also use weights="DEFAULT"
# 4. Freeze the base layers in the model (this will freeze all layers to begin with)
for param in effnetb2.parameters():
param.requires_grad = False
现在要修改分类器头部,让我们先使用模型的 classifier 属性来检查它。
# Check out EffNetB2 classifier head
effnetb2.classifier
Sequential( (0): Dropout(p=0.3, inplace=True) (1): Linear(in_features=1408, out_features=1000, bias=True) )
太棒了!为了使分类器头适应我们的问题,让我们将 out_features 变量替换为我们拥有的类别数量(在我们的例子中,out_features=3,分别对应披萨、牛排和寿司)。
注意: 这个更改输出层/分类器头的过程将取决于你正在处理的问题。例如,如果你想要不同数量的输出或不同类型的输出,你需要相应地更改输出层。
# 5. Update the classifier head
effnetb2.classifier = nn.Sequential(
nn.Dropout(p=0.3, inplace=True), # keep dropout layer same
nn.Linear(in_features=1408, # keep in_features same
out_features=3)) # change out_features to suit our number of classes
太美了!
3.1 创建一个函数来生成EffNetB2特征提取器¶
看起来我们的EffNetB2特征提取器已经准备就绪,但由于这里涉及的步骤较多,我们不妨将上述代码封装成一个函数,以便后续复用。
我们将这个函数命名为 create_effnetb2_model(),并允许用户自定义类别数量和随机种子参数以确保可重复性。
理想情况下,该函数将返回一个EffNetB2特征提取器及其关联的转换操作。
def create_effnetb2_model(num_classes:int=3,
seed:int=42):
"""Creates an EfficientNetB2 feature extractor model and transforms.
Args:
num_classes (int, optional): number of classes in the classifier head.
Defaults to 3.
seed (int, optional): random seed value. Defaults to 42.
Returns:
model (torch.nn.Module): EffNetB2 feature extractor model.
transforms (torchvision.transforms): EffNetB2 image transforms.
"""
# 1, 2, 3. Create EffNetB2 pretrained weights, transforms and model
weights = torchvision.models.EfficientNet_B2_Weights.DEFAULT
transforms = weights.transforms()
model = torchvision.models.efficientnet_b2(weights=weights)
# 4. Freeze all layers in base model
for param in model.parameters():
param.requires_grad = False
# 5. Change classifier head with random seed for reproducibility
torch.manual_seed(seed)
model.classifier = nn.Sequential(
nn.Dropout(p=0.3, inplace=True),
nn.Linear(in_features=1408, out_features=num_classes),
)
return model, transforms
哇哦!这个函数看起来真不错,我们来试试吧。
effnetb2, effnetb2_transforms = create_effnetb2_model(num_classes=3,
seed=42)
没有错误,很好,现在来真正尝试一下,让我们用 torchinfo.summary() 获取一个总结。
from torchinfo import summary
# # Print EffNetB2 model summary (uncomment for full output)
# summary(effnetb2,
# input_size=(1, 3, 224, 224),
# col_names=["input_size", "output_size", "num_params", "trainable"],
# col_width=20,
# row_settings=["var_names"])
基础层冻结,顶层可训练且自定义!
3.2 为EffNetB2创建DataLoader¶
我们的EffNetB2特征提取器已经准备就绪,接下来是创建一些DataLoader。
我们可以使用在05. PyTorch Going Modular第2节中创建的data_setup.create_dataloaders()函数来实现这一点。
我们将使用batch_size为32,并通过effnetb2_transforms对图像进行变换,以确保它们与我们的effnetb2模型训练时的格式一致。
# Setup DataLoaders
from going_modular.going_modular import data_setup
train_dataloader_effnetb2, test_dataloader_effnetb2, class_names = data_setup.create_dataloaders(train_dir=train_dir,
test_dir=test_dir,
transform=effnetb2_transforms,
batch_size=32)
3.3 训练 EffNetB2 特征提取器¶
模型准备好了,DataLoader 也准备好了,让我们开始训练吧!
就像在 07. PyTorch 实验跟踪 第 7.6 节 中一样,十个 epoch 应该足够获得良好的结果。
我们可以通过创建一个优化器(我们将使用学习率为 1e-3 的 torch.optim.Adam())、一个损失函数(我们将使用适用于多类别分类的 torch.nn.CrossEntropyLoss()),然后将这些以及我们的 DataLoader 传递给我们在 05. PyTorch 模块化 第 4 节 中创建的 engine.train() 函数来实现。
from going_modular.going_modular import engine
# Setup optimizer
optimizer = torch.optim.Adam(params=effnetb2.parameters(),
lr=1e-3)
# Setup loss function
loss_fn = torch.nn.CrossEntropyLoss()
# Set seeds for reproducibility and train the model
set_seeds()
effnetb2_results = engine.train(model=effnetb2,
train_dataloader=train_dataloader_effnetb2,
test_dataloader=test_dataloader_effnetb2,
epochs=10,
optimizer=optimizer,
loss_fn=loss_fn,
device=device)
0%| | 0/10 [00:00<?, ?it/s]
Epoch: 1 | train_loss: 0.9856 | train_acc: 0.5604 | test_loss: 0.7408 | test_acc: 0.9347 Epoch: 2 | train_loss: 0.7175 | train_acc: 0.8438 | test_loss: 0.5869 | test_acc: 0.9409 Epoch: 3 | train_loss: 0.5876 | train_acc: 0.8917 | test_loss: 0.4909 | test_acc: 0.9500 Epoch: 4 | train_loss: 0.4474 | train_acc: 0.9062 | test_loss: 0.4355 | test_acc: 0.9409 Epoch: 5 | train_loss: 0.4290 | train_acc: 0.9104 | test_loss: 0.3915 | test_acc: 0.9443 Epoch: 6 | train_loss: 0.4381 | train_acc: 0.8896 | test_loss: 0.3512 | test_acc: 0.9688 Epoch: 7 | train_loss: 0.4245 | train_acc: 0.8771 | test_loss: 0.3268 | test_acc: 0.9563 Epoch: 8 | train_loss: 0.3897 | train_acc: 0.8958 | test_loss: 0.3457 | test_acc: 0.9381 Epoch: 9 | train_loss: 0.3749 | train_acc: 0.8812 | test_loss: 0.3129 | test_acc: 0.9131 Epoch: 10 | train_loss: 0.3757 | train_acc: 0.8604 | test_loss: 0.2813 | test_acc: 0.9688
3.4 检查 EffNetB2 损失曲线¶
很好!
正如我们在 07. PyTorch 实验追踪中所见,EffNetB2 特征提取器模型在我们的数据上表现相当不错。
让我们将其结果转化为损失曲线,以便进一步检查。
注意: 损失曲线是可视化模型性能的最佳方式之一。更多关于损失曲线的信息,请参阅 04. PyTorch 自定义数据集第 8 节:理想的损失曲线应该是什么样的?
from helper_functions import plot_loss_curves
plot_loss_curves(effnetb2_results)

3.5 保存EffNetB2特征提取器¶
现在我们已经有了一个表现良好的训练模型,让我们将其保存到文件中,以便稍后导入和使用。
为了保存我们的模型,我们可以使用我们在05. PyTorch Going Modular 第5节中创建的utils.save_model()函数。
我们将target_dir设置为"models",并将model_name设置为"09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth"(虽然有点详细,但至少我们知道发生了什么)。
from going_modular.going_modular import utils
# Save the model
utils.save_model(model=effnetb2,
target_dir="models",
model_name="09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth")
[INFO] Saving model to: models/09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth
3.6 检查EffNetB2特征提取器的大小¶
由于我们部署模型以支持FoodVision Mini的标准之一是速度(~30FPS或更高),让我们检查一下模型的大小。
为什么要检查大小?
虽然并非总是如此,但模型的大小可以影响其推理速度。
也就是说,如果一个模型有更多的参数,它通常会执行更多的操作,而这些操作中的每一个都需要一定的计算能力。
并且因为我们希望我们的模型能够在计算能力有限的设备上工作(例如在移动设备或网页浏览器中),通常情况下,模型越小越好(只要它在准确性方面仍然表现良好)。
要检查模型的大小(以字节为单位),我们可以使用Python的pathlib.Path.stat("path_to_model").st_size,然后我们可以通过将其除以(1024*1024)来粗略地转换为兆字节。
from pathlib import Path
# Get the model size in bytes then convert to megabytes
pretrained_effnetb2_model_size = Path("models/09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth").stat().st_size // (1024*1024) # division converts bytes to megabytes (roughly)
print(f"Pretrained EffNetB2 feature extractor model size: {pretrained_effnetb2_model_size} MB")
Pretrained EffNetB2 feature extractor model size: 29 MB
3.7 收集EffNetB2特征提取器的统计信息¶
我们已经获得了一些关于EffNetB2特征提取器模型的统计数据,例如测试损失、测试准确率和模型大小。为了便于与即将推出的ViT特征提取器进行比较,我们可以将这些数据收集到一个字典中。
为了增加趣味性,我们还将计算一个额外的统计数据:总参数数量。
我们可以通过计算effnetb2.parameters()中的元素(或模式/权重)数量来实现这一点。我们将使用torch.numel()("number of elements"的缩写)方法来访问每个参数中的元素数量。
# Count number of parameters in EffNetB2
effnetb2_total_params = sum(torch.numel(param) for param in effnetb2.parameters())
effnetb2_total_params
7705221
太棒了!
现在让我们把所有内容放入一个字典中,这样我们稍后就可以进行比较了。
# Create a dictionary with EffNetB2 statistics
effnetb2_stats = {"test_loss": effnetb2_results["test_loss"][-1],
"test_acc": effnetb2_results["test_acc"][-1],
"number_of_parameters": effnetb2_total_params,
"model_size (MB)": pretrained_effnetb2_model_size}
effnetb2_stats
{'test_loss': 0.28128674924373626,
'test_acc': 0.96875,
'number_of_parameters': 7705221,
'model_size (MB)': 29}
太棒了!
看来我们的EffNetB2模型准确率超过了95%!
第一条标准:达到95%或更高的准确率,达标!
4. 创建 ViT 特征提取器¶
接下来继续我们的 FoodVision Mini 模型实验。
这次我们将创建一个 ViT 特征提取器。
我们将以与 EffNetB2 特征提取器类似的方式进行,只不过这次使用 torchvision.models.vit_b_16() 而不是 torchvision.models.efficientnet_b2()。
首先,我们将创建一个名为 create_vit_model() 的函数,该函数与 create_effnetb2_model() 非常相似,当然,它将返回一个 ViT 特征提取器模型和变换,而不是 EffNetB2。
另一个细微差别是,torchvision.models.vit_b_16() 的输出层称为 heads 而不是 classifier。
# Check out ViT heads layer
vit = torchvision.models.vit_b_16()
vit.heads
Sequential( (head): Linear(in_features=768, out_features=1000, bias=True) )
了解这一点后,我们已经拥有了所需的所有拼图碎片。
def create_vit_model(num_classes:int=3,
seed:int=42):
"""Creates a ViT-B/16 feature extractor model and transforms.
Args:
num_classes (int, optional): number of target classes. Defaults to 3.
seed (int, optional): random seed value for output layer. Defaults to 42.
Returns:
model (torch.nn.Module): ViT-B/16 feature extractor model.
transforms (torchvision.transforms): ViT-B/16 image transforms.
"""
# Create ViT_B_16 pretrained weights, transforms and model
weights = torchvision.models.ViT_B_16_Weights.DEFAULT
transforms = weights.transforms()
model = torchvision.models.vit_b_16(weights=weights)
# Freeze all layers in model
for param in model.parameters():
param.requires_grad = False
# Change classifier head to suit our needs (this will be trainable)
torch.manual_seed(seed)
model.heads = nn.Sequential(nn.Linear(in_features=768, # keep this the same as original model
out_features=num_classes)) # update to reflect target number of classes
return model, transforms
ViT特征提取模型创建函数已就绪!
我们来测试一下。
# Create ViT model and transforms
vit, vit_transforms = create_vit_model(num_classes=3,
seed=42)
没有错误,真是太好了!
现在让我们使用 torchinfo.summary() 来获取一个漂亮的 ViT 模型总结。
from torchinfo import summary
# # Print ViT feature extractor model summary (uncomment for full output)
# summary(vit,
# input_size=(1, 3, 224, 224),
# col_names=["input_size", "output_size", "num_params", "trainable"],
# col_width=20,
# row_settings=["var_names"])
与我们的EffNetB2特征提取器模型一样,我们的ViT模型的基础层是冻结的,输出层则根据我们的需求进行了定制!
不过,你是否注意到了一个巨大的差异?
我们的ViT模型比EffNetB2模型拥有多得多的参数。也许这在稍后我们比较模型在速度和性能方面的表现时会起到作用。
4.1 为 ViT 创建 DataLoader¶
我们的 ViT 模型已经准备好了,现在让我们为它创建一些 DataLoader。
我们将以与为 EffNetB2 创建 DataLoader 相同的方式进行,只不过我们会使用 vit_transforms 将我们的图像转换成 ViT 模型训练时的相同格式。
# Setup ViT DataLoaders
from going_modular.going_modular import data_setup
train_dataloader_vit, test_dataloader_vit, class_names = data_setup.create_dataloaders(train_dir=train_dir,
test_dir=test_dir,
transform=vit_transforms,
batch_size=32)
4.2 训练 ViT 特征提取器¶
你知道现在是什么时候吗...
...是训练时间(用与歌曲《Closing Time》相同的旋律唱出来)。
让我们使用 engine.train() 函数,结合 torch.optim.Adam() 优化器(学习率为 1e-3)和 torch.nn.CrossEntropyLoss() 损失函数,对我们的 ViT 特征提取器模型进行 10 个周期的训练。
在训练之前,我们将使用 set_seeds() 函数,以尽可能确保结果的可重复性。
from going_modular.going_modular import engine
# Setup optimizer
optimizer = torch.optim.Adam(params=vit.parameters(),
lr=1e-3)
# Setup loss function
loss_fn = torch.nn.CrossEntropyLoss()
# Train ViT model with seeds set for reproducibility
set_seeds()
vit_results = engine.train(model=vit,
train_dataloader=train_dataloader_vit,
test_dataloader=test_dataloader_vit,
epochs=10,
optimizer=optimizer,
loss_fn=loss_fn,
device=device)
0%| | 0/10 [00:00<?, ?it/s]
Epoch: 1 | train_loss: 0.7023 | train_acc: 0.7500 | test_loss: 0.2714 | test_acc: 0.9290 Epoch: 2 | train_loss: 0.2531 | train_acc: 0.9104 | test_loss: 0.1669 | test_acc: 0.9602 Epoch: 3 | train_loss: 0.1766 | train_acc: 0.9542 | test_loss: 0.1270 | test_acc: 0.9693 Epoch: 4 | train_loss: 0.1277 | train_acc: 0.9625 | test_loss: 0.1072 | test_acc: 0.9722 Epoch: 5 | train_loss: 0.1163 | train_acc: 0.9646 | test_loss: 0.0950 | test_acc: 0.9784 Epoch: 6 | train_loss: 0.1270 | train_acc: 0.9375 | test_loss: 0.0830 | test_acc: 0.9722 Epoch: 7 | train_loss: 0.0899 | train_acc: 0.9771 | test_loss: 0.0844 | test_acc: 0.9784 Epoch: 8 | train_loss: 0.0928 | train_acc: 0.9812 | test_loss: 0.0759 | test_acc: 0.9722 Epoch: 9 | train_loss: 0.0933 | train_acc: 0.9792 | test_loss: 0.0729 | test_acc: 0.9784 Epoch: 10 | train_loss: 0.0662 | train_acc: 0.9833 | test_loss: 0.0642 | test_acc: 0.9847
4.3 检查 ViT 损失曲线¶
好了,好了,好了,ViT 模型训练完成了,让我们来直观地看看一些损失曲线。
注意: 别忘了你可以在04. PyTorch 自定义数据集 第8节中查看一组理想的损失曲线应该是什么样子的。
from helper_functions import plot_loss_curves
plot_loss_curves(vit_results)

哦耶!
这些损失曲线看起来真不错。就像我们的EffNetB2特征提取模型一样,看来我们的ViT模型可能也会从稍长时间的训练和一些数据增强(有助于防止过拟合)中获益。
4.4 保存 ViT 特征提取器¶
我们的 ViT 模型表现非常出色!
因此,让我们将其保存到文件中,以便日后可以导入并使用它。
我们可以使用在 05. PyTorch Going Modular 第5节 中创建的 utils.save_model() 函数来实现这一点。
# Save the model
from going_modular.going_modular import utils
utils.save_model(model=vit,
target_dir="models",
model_name="09_pretrained_vit_feature_extractor_pizza_steak_sushi_20_percent.pth")
[INFO] Saving model to: models/09_pretrained_vit_feature_extractor_pizza_steak_sushi_20_percent.pth
4.5 检查 ViT 特征提取器的大小¶
由于我们希望在多个特性上将我们的 EffNetB2 模型与 ViT 模型进行比较,让我们来了解一下它的大小。
要检查模型的大小(以字节为单位),我们可以使用 Python 的 pathlib.Path.stat("path_to_model").st_size,然后通过将其除以 (1024*1024) 来(大致)转换为兆字节。
from pathlib import Path
# Get the model size in bytes then convert to megabytes
pretrained_vit_model_size = Path("models/09_pretrained_vit_feature_extractor_pizza_steak_sushi_20_percent.pth").stat().st_size // (1024*1024) # division converts bytes to megabytes (roughly)
print(f"Pretrained ViT feature extractor model size: {pretrained_vit_model_size} MB")
Pretrained ViT feature extractor model size: 327 MB
嗯,ViT特征提取器模型的尺寸与我们的EffNetB2模型尺寸相比如何呢?
我们很快就会通过比较所有模型的特性来找出答案。
# Count number of parameters in ViT
vit_total_params = sum(torch.numel(param) for param in vit.parameters())
vit_total_params
85800963
哇,这看起来比我们的EffNetB2多多了!
注意: 参数(或权重/模式)数量较多通常意味着模型具有更高的学习能力,至于它是否真的利用了这种额外的能力则是另一回事。考虑到这一点,我们的EffNetB2模型有7,705,221个参数,而我们的ViT模型有85,800,963个参数(多11.1倍),因此我们可以假设ViT模型在拥有更多数据(更多学习机会)的情况下具有更大的学习能力。然而,这种更大的学习能力往往伴随着模型文件大小的增加和推理时间的延长。
现在,让我们创建一个包含ViT模型一些重要特征的字典。
# Create ViT statistics dictionary
vit_stats = {"test_loss": vit_results["test_loss"][-1],
"test_acc": vit_results["test_acc"][-1],
"number_of_parameters": vit_total_params,
"model_size (MB)": pretrained_vit_model_size}
vit_stats
{'test_loss': 0.06418210905976593,
'test_acc': 0.984659090909091,
'number_of_parameters': 85800963,
'model_size (MB)': 327}
太棒了!看来我们的ViT模型也达到了超过95%的准确率。
5. 使用训练好的模型进行预测并计时¶
我们已经有了几个训练得相当不错的模型。
现在,让我们测试一下它们是否能完成我们期望它们完成的任务。
也就是说,让我们看看它们在做出预测(执行推理)时的表现如何。
我们知道这两个模型在测试数据集上的准确率都超过了95%,但它们的运行速度如何呢?
理想情况下,如果我们打算将FoodVision Mini模型部署到移动设备上,让用户拍摄食物照片并进行识别,我们希望预测能够在实时(大约每秒30帧)下进行。
这就是为什么我们的第二个标准是:一个快速的模型。
为了找出每个模型执行推理所需的时间,让我们创建一个名为pred_and_store()的函数,逐个迭代测试数据集中的每张图像并进行预测。
我们将记录每次预测的时间,并将结果存储在一个通用的预测格式中:一个字典列表(其中列表的每个元素是一次预测,每个预测是一个字典)。
注意: 我们逐个计时预测而不是批量计时,因为在模型部署时,它很可能一次只对一张图像进行预测。也就是说,用户拍摄一张照片,我们的模型对那张单一图像进行预测。
由于我们希望对测试集中的所有图像进行预测,首先让我们获取所有测试图像路径的列表,以便我们可以迭代它们。
为此,我们将使用Python的pathlib.Path("target_dir").glob("*/*.jpg"))来查找目标目录中所有扩展名为.jpg的文件路径(我们所有的测试图像)。
from pathlib import Path
# Get all test data paths
print(f"[INFO] Finding all filepaths ending with '.jpg' in directory: {test_dir}")
test_data_paths = list(Path(test_dir).glob("*/*.jpg"))
test_data_paths[:5]
[INFO] Finding all filepaths ending with '.jpg' in directory: data/pizza_steak_sushi_20_percent/test
[PosixPath('data/pizza_steak_sushi_20_percent/test/steak/831681.jpg'),
PosixPath('data/pizza_steak_sushi_20_percent/test/steak/3100563.jpg'),
PosixPath('data/pizza_steak_sushi_20_percent/test/steak/2752603.jpg'),
PosixPath('data/pizza_steak_sushi_20_percent/test/steak/39461.jpg'),
PosixPath('data/pizza_steak_sushi_20_percent/test/steak/730464.jpg')]
5.1 创建一个函数来对测试数据集进行预测¶
现在我们已经有了测试图像路径的列表,让我们开始编写 pred_and_store() 函数:
- 创建一个函数,该函数接受一个路径列表、一个经过训练的 PyTorch 模型、一系列转换(用于准备图像)、目标类别名称列表和一个目标设备。
- 创建一个空列表来存储预测字典(我们希望函数返回一个字典列表,每个字典对应一个预测)。
- 遍历目标输入路径(步骤 4-14 将在循环内部进行)。
- 为每次循环迭代创建一个空字典,用于存储每个样本的预测值。
- 获取样本路径和真实类别名称(我们可以通过路径推断类别)。
- 使用 Python 的
timeit.default_timer()开始预测计时。 - 使用
PIL.Image.open(path)打开图像。 - 转换图像,使其能够被目标模型使用,同时添加批次维度并将图像发送到目标设备。
- 通过将模型发送到目标设备并开启
eval()模式来准备模型进行推理。 - 开启
torch.inference_mode(),将目标转换后的图像传递给模型,并使用torch.softmax()计算预测概率,使用torch.argmax()计算预测类别。 - 将预测概率和预测类别添加到步骤 4 中创建的预测字典中。同时确保预测概率在 CPU 上,以便后续可以使用非 GPU 库(如 NumPy 和 pandas)进行检查。
- 结束步骤 6 开始的预测计时,并将时间添加到步骤 4 中创建的预测字典中。
- 检查预测类别是否与步骤 5 中的真实类别匹配,并将结果添加到步骤 4 中创建的预测字典中。
- 将更新后的预测字典追加到步骤 2 中创建的空预测列表中。
- 返回预测字典列表。
虽然步骤很多,但我们完全可以应对!
让我们开始吧。
import pathlib
import torch
from PIL import Image
from timeit import default_timer as timer
from tqdm.auto import tqdm
from typing import List, Dict
# 1. Create a function to return a list of dictionaries with sample, truth label, prediction, prediction probability and prediction time
def pred_and_store(paths: List[pathlib.Path],
model: torch.nn.Module,
transform: torchvision.transforms,
class_names: List[str],
device: str = "cuda" if torch.cuda.is_available() else "cpu") -> List[Dict]:
# 2. Create an empty list to store prediction dictionaires
pred_list = []
# 3. Loop through target paths
for path in tqdm(paths):
# 4. Create empty dictionary to store prediction information for each sample
pred_dict = {}
# 5. Get the sample path and ground truth class name
pred_dict["image_path"] = path
class_name = path.parent.stem
pred_dict["class_name"] = class_name
# 6. Start the prediction timer
start_time = timer()
# 7. Open image path
img = Image.open(path)
# 8. Transform the image, add batch dimension and put image on target device
transformed_image = transform(img).unsqueeze(0).to(device)
# 9. Prepare model for inference by sending it to target device and turning on eval() mode
model.to(device)
model.eval()
# 10. Get prediction probability, predicition label and prediction class
with torch.inference_mode():
pred_logit = model(transformed_image) # perform inference on target sample
pred_prob = torch.softmax(pred_logit, dim=1) # turn logits into prediction probabilities
pred_label = torch.argmax(pred_prob, dim=1) # turn prediction probabilities into prediction label
pred_class = class_names[pred_label.cpu()] # hardcode prediction class to be on CPU
# 11. Make sure things in the dictionary are on CPU (required for inspecting predictions later on)
pred_dict["pred_prob"] = round(pred_prob.unsqueeze(0).max().cpu().item(), 4)
pred_dict["pred_class"] = pred_class
# 12. End the timer and calculate time per pred
end_time = timer()
pred_dict["time_for_pred"] = round(end_time-start_time, 4)
# 13. Does the pred match the true label?
pred_dict["correct"] = class_name == pred_class
# 14. Add the dictionary to the list of preds
pred_list.append(pred_dict)
# 15. Return list of prediction dictionaries
return pred_list
嚯,嚯!
多么美观的函数啊!
而且你知道吗,既然我们的 pred_and_store() 是一个相当不错的实用函数,用于进行预测并存储结果,那么它可以被存放到 going_modular.going_modular.predictions.py 中,以备后续使用。这可能是一个你愿意尝试的扩展,可以参考 05. PyTorch Going Modular 获取更多想法。
5.2 使用EffNetB2进行预测及计时¶
是时候测试一下我们的 pred_and_store() 函数了!
让我们开始使用它对测试数据集进行预测,同时注意以下两个细节:
- 设备 - 我们将
device参数硬编码为使用"cpu",因为在部署模型时,我们并不总是能访问到"cuda"(GPU)设备。- 在CPU上进行预测可以很好地指示推理速度,因为通常在CPU设备上的预测速度比GPU设备慢。
- 转换 - 我们还要确保将
transform参数设置为effnetb2_transforms,以确保图像以与effnetb2模型训练时相同的方式打开和转换。
# Make predictions across test dataset with EffNetB2
effnetb2_test_pred_dicts = pred_and_store(paths=test_data_paths,
model=effnetb2,
transform=effnetb2_transforms,
class_names=class_names,
device="cpu") # make predictions on CPU
0%| | 0/150 [00:00<?, ?it/s]
太棒了!看看那些预测飞速运行!
让我们检查前几个,看看它们是什么样子的。
# Inspect the first 2 prediction dictionaries
effnetb2_test_pred_dicts[:2]
[{'image_path': PosixPath('data/pizza_steak_sushi_20_percent/test/steak/831681.jpg'),
'class_name': 'steak',
'pred_prob': 0.9293,
'pred_class': 'steak',
'time_for_pred': 0.0494,
'correct': True},
{'image_path': PosixPath('data/pizza_steak_sushi_20_percent/test/steak/3100563.jpg'),
'class_name': 'steak',
'pred_prob': 0.9534,
'pred_class': 'steak',
'time_for_pred': 0.0264,
'correct': True}]
哇哦!
看来我们的 pred_and_store() 函数运行得相当不错。
多亏了我们使用字典列表的数据结构,我们现在拥有了许多可以进一步检查的有用信息。
为了做到这一点,让我们将字典列表转换为 pandas DataFrame。
# Turn the test_pred_dicts into a DataFrame
import pandas as pd
effnetb2_test_pred_df = pd.DataFrame(effnetb2_test_pred_dicts)
effnetb2_test_pred_df.head()
| image_path | class_name | pred_prob | pred_class | time_for_pred | correct | |
|---|---|---|---|---|---|---|
| 0 | data/pizza_steak_sushi_20_percent/test/steak/8... | steak | 0.9293 | steak | 0.0494 | True |
| 1 | data/pizza_steak_sushi_20_percent/test/steak/3... | steak | 0.9534 | steak | 0.0264 | True |
| 2 | data/pizza_steak_sushi_20_percent/test/steak/2... | steak | 0.7532 | steak | 0.0256 | True |
| 3 | data/pizza_steak_sushi_20_percent/test/steak/3... | steak | 0.5935 | steak | 0.0263 | True |
| 4 | data/pizza_steak_sushi_20_percent/test/steak/7... | steak | 0.8959 | steak | 0.0269 | True |
太棒了!
看看这些预测字典是如何轻松地转换成我们可以进行分析的结构化格式的。
比如,我们可以找出EffNetB2模型有多少预测是错误的...
# Check number of correct predictions
effnetb2_test_pred_df.correct.value_counts()
True 145 False 5 Name: correct, dtype: int64
150个预测中只有5个错误,相当不错!
那么平均预测时间呢?
# Find the average time per prediction
effnetb2_average_time_per_pred = round(effnetb2_test_pred_df.time_for_pred.mean(), 4)
print(f"EffNetB2 average time per prediction: {effnetb2_average_time_per_pred} seconds")
EffNetB2 average time per prediction: 0.0269 seconds
注: 预测时间会因不同硬件类型而异(例如本地 Intel i9 与 Google Colab CPU)。通常情况下,硬件越好越快,预测速度也越快。例如,在我的本地深度学习 PC 上,配备 Intel i9 芯片,使用 EffNetB2 的平均预测时间约为 0.031 秒(接近实时)。然而,在 Google Colab 上(我不确定 Colab 使用的是什么 CPU 硬件,但看起来可能是 Intel(R) Xeon(R)),使用 EffNetB2 的平均预测时间约为 0.1396 秒(慢 3-4 倍)。
让我们将 EffNetB2 的平均预测时间添加到我们的 effnetb2_stats 字典中。
# Add EffNetB2 average prediction time to stats dictionary
effnetb2_stats["time_per_pred_cpu"] = effnetb2_average_time_per_pred
effnetb2_stats
{'test_loss': 0.28128674924373626,
'test_acc': 0.96875,
'number_of_parameters': 7705221,
'model_size (MB)': 29,
'time_per_pred_cpu': 0.0269}
5.3 使用ViT进行预测及计时¶
我们已经使用EffNetB2模型进行了预测,现在让我们对ViT模型进行同样的操作。
为此,我们可以使用上面创建的pred_and_store()函数,只不过这次我们将传入我们的vit模型以及vit_transforms。
并且我们将预测保持在CPU上通过device="cpu"(这里的一个自然扩展是测试在CPU和GPU上的预测时间)。
# Make list of prediction dictionaries with ViT feature extractor model on test images
vit_test_pred_dicts = pred_and_store(paths=test_data_paths,
model=vit,
transform=vit_transforms,
class_names=class_names,
device="cpu")
0%| | 0/150 [00:00<?, ?it/s]
预测已出炉!
现在让我们来看看前几对。
# Check the first couple of ViT predictions on the test dataset
vit_test_pred_dicts[:2]
[{'image_path': PosixPath('data/pizza_steak_sushi_20_percent/test/steak/831681.jpg'),
'class_name': 'steak',
'pred_prob': 0.9933,
'pred_class': 'steak',
'time_for_pred': 0.1313,
'correct': True},
{'image_path': PosixPath('data/pizza_steak_sushi_20_percent/test/steak/3100563.jpg'),
'class_name': 'steak',
'pred_prob': 0.9893,
'pred_class': 'steak',
'time_for_pred': 0.0638,
'correct': True}]
太棒了!
就像之前一样,由于我们的ViT模型的预测结果是以字典列表的形式呈现的,我们可以轻松地将它们转换为pandas DataFrame,以便进一步检查。
# Turn vit_test_pred_dicts into a DataFrame
import pandas as pd
vit_test_pred_df = pd.DataFrame(vit_test_pred_dicts)
vit_test_pred_df.head()
| image_path | class_name | pred_prob | pred_class | time_for_pred | correct | |
|---|---|---|---|---|---|---|
| 0 | data/pizza_steak_sushi_20_percent/test/steak/8... | steak | 0.9933 | steak | 0.1313 | True |
| 1 | data/pizza_steak_sushi_20_percent/test/steak/3... | steak | 0.9893 | steak | 0.0638 | True |
| 2 | data/pizza_steak_sushi_20_percent/test/steak/2... | steak | 0.9971 | steak | 0.0627 | True |
| 3 | data/pizza_steak_sushi_20_percent/test/steak/3... | steak | 0.7685 | steak | 0.0632 | True |
| 4 | data/pizza_steak_sushi_20_percent/test/steak/7... | steak | 0.9499 | steak | 0.0641 | True |
我们的ViT模型正确预测了多少次?
# Count the number of correct predictions
vit_test_pred_df.correct.value_counts()
True 148 False 2 Name: correct, dtype: int64
哇哦!
我们的ViT模型在正确预测方面略胜一筹,整个测试数据集中仅错了两个样本。
作为扩展,你或许想可视化ViT模型的错误预测,看看是否有任何原因导致它出错。
我们何不计算一下ViT模型每条预测所花费的时间呢?
# Calculate average time per prediction for ViT model
vit_average_time_per_pred = round(vit_test_pred_df.time_for_pred.mean(), 4)
print(f"ViT average time per prediction: {vit_average_time_per_pred} seconds")
ViT average time per prediction: 0.0641 seconds
嗯,看起来比我们的EffNetB2模型的平均预测时间稍慢一些,但在我们的第二项标准——速度方面,表现如何呢?
目前,让我们将这个数值添加到我们的vit_stats字典中,以便与EffNetB2模型的统计数据进行比较。
注意: 平均预测时间值将高度依赖于运行它们的硬件。例如,对于ViT模型,在我的本地深度学习PC(搭载Intel i9 CPU)上,平均预测时间(在CPU上)为0.0693-0.0777秒。而在Google Colab上,使用ViT模型的平均预测时间为0.6766-0.7113秒。
# Add average prediction time for ViT model on CPU
vit_stats["time_per_pred_cpu"] = vit_average_time_per_pred
vit_stats
{'test_loss': 0.06418210905976593,
'test_acc': 0.984659090909091,
'number_of_parameters': 85800963,
'model_size (MB)': 327,
'time_per_pred_cpu': 0.0641}
6. 比较模型结果、预测时间和大小¶
我们的两个最佳模型候选已经完成训练和评估。
现在让我们将它们进行正面比较,并对比它们的不同统计数据。
为此,我们将 effnetb2_stats 和 vit_stats 字典转换为 pandas DataFrame。
我们还将添加一列来显示模型名称,并将测试准确率转换为百分比形式,而非小数。
# Turn stat dictionaries into DataFrame
df = pd.DataFrame([effnetb2_stats, vit_stats])
# Add column for model names
df["model"] = ["EffNetB2", "ViT"]
# Convert accuracy to percentages
df["test_acc"] = round(df["test_acc"] * 100, 2)
df
| test_loss | test_acc | number_of_parameters | model_size (MB) | time_per_pred_cpu | model | |
|---|---|---|---|---|---|---|
| 0 | 0.281287 | 96.88 | 7705221 | 29 | 0.0269 | EffNetB2 |
| 1 | 0.064182 | 98.47 | 85800963 | 327 | 0.0641 | ViT |
太棒了!
看起来我们的模型在整体测试准确率方面相当接近,但它们在其他领域的表现如何呢?
一种方法是计算ViT模型统计数据与EffNetB2模型统计数据的比值,以找出模型之间的不同比率。
让我们创建另一个DataFrame来实现这一点。
# Compare ViT to EffNetB2 across different characteristics
pd.DataFrame(data=(df.set_index("model").loc["ViT"] / df.set_index("model").loc["EffNetB2"]), # divide ViT statistics by EffNetB2 statistics
columns=["ViT to EffNetB2 ratios"]).T
| test_loss | test_acc | number_of_parameters | model_size (MB) | time_per_pred_cpu | |
|---|---|---|---|---|---|
| ViT to EffNetB2 ratios | 0.228173 | 1.016412 | 11.135432 | 11.275862 | 2.3829 |
看起来我们的ViT模型在各项性能指标(测试损失,数值越低越好;测试准确率,数值越高越好)上均优于EffNetB2模型,但这是以以下代价为前提的:
- 参数数量多出11倍以上。
- 模型大小大出11倍以上。
- 单张图像的预测时间长出2.5倍以上。
这些权衡是否值得呢?
或许在拥有无限计算资源的情况下是值得的,但对于我们部署FoodVision Mini模型到较小设备(例如智能手机)的实际应用场景,我们可能会优先选择EffNetB2模型,以实现更快的预测速度,尽管性能略有降低,但模型尺寸显著减小。
6.1 可视化速度与性能的权衡¶
我们已经看到,在测试损失和测试准确性等性能指标方面,我们的ViT模型优于EffNetB2模型。
然而,EffNetB2模型的预测速度更快,并且模型尺寸要小得多。
注意: 性能或推理时间通常也被称为“延迟”。
我们如何将这一事实可视化呢?
我们可以通过使用matplotlib创建一个图表来实现这一点:
- 从比较DataFrame创建一个散点图,比较EffNetB2和ViT的
time_per_pred_cpu和test_acc值。 - 根据数据添加标题和标签,并调整字体大小以增强美观性。
- 在步骤1的散点图上标注样本,并使用适当的标签(模型名称)进行标注。
- 根据模型大小(
model_size (MB))创建图例。
# 1. Create a plot from model comparison DataFrame
fig, ax = plt.subplots(figsize=(12, 8))
scatter = ax.scatter(data=df,
x="time_per_pred_cpu",
y="test_acc",
c=["blue", "orange"], # what colours to use?
s="model_size (MB)") # size the dots by the model sizes
# 2. Add titles, labels and customize fontsize for aesthetics
ax.set_title("FoodVision Mini Inference Speed vs Performance", fontsize=18)
ax.set_xlabel("Prediction time per image (seconds)", fontsize=14)
ax.set_ylabel("Test accuracy (%)", fontsize=14)
ax.tick_params(axis='both', labelsize=12)
ax.grid(True)
# 3. Annotate with model names
for index, row in df.iterrows():
ax.annotate(text=row["model"], # note: depending on your version of Matplotlib, you may need to use "s=..." or "text=...", see: https://github.com/faustomorales/keras-ocr/issues/183#issuecomment-977733270
xy=(row["time_per_pred_cpu"]+0.0006, row["test_acc"]+0.03),
size=12)
# 4. Create a legend based on model sizes
handles, labels = scatter.legend_elements(prop="sizes", alpha=0.5)
model_size_legend = ax.legend(handles,
labels,
loc="lower right",
title="Model size (MB)",
fontsize=12)
# Save the figure
!mdkir images/
plt.savefig("images/09-foodvision-mini-inference-speed-vs-performance.jpg")
# Show the figure
plt.show()

哇!
这个图表确实展示了速度与性能的权衡,换句话说,当你拥有一个更大、性能更好的深度模型(比如我们的ViT模型)时,它通常需要更长的时间来执行推理(更高的延迟)。
这个规律也有例外,而且不断有新的研究发表,旨在帮助大型模型更快地执行。
部署最佳性能的模型可能会很诱人,但也要考虑模型将在何处执行。
在我们的案例中,我们的模型在测试损失和测试准确性方面的性能差异并不太大。
但由于我们最初强调速度,我们将坚持部署EffNetB2,因为它更快且占用空间更小。
注意:预测时间在不同硬件类型上会有所不同(例如,Intel i9与Google Colab CPU与GPU),因此考虑和测试模型最终将在何处运行非常重要。提出诸如“模型将在何处运行?”或“运行模型的理想场景是什么?”等问题,并通过实验尝试在部署过程中提供答案,这是非常有帮助的。
7. 通过创建 Gradio 演示让 FoodVision Mini 焕发生机¶
我们决定首先部署 EffNetB2 模型(当然,以后可以随时更改)。
那么我们该如何实现呢?
有多种方式可以部署机器学习模型,每种方式都有特定的应用场景(如上所述)。
我们将专注于可能是最快捷且肯定是最有趣的一种方式,将模型部署到互联网上。
那就是使用 Gradio。
什么是 Gradio?
其主页上的描述非常精彩:
Gradio 是演示你的机器学习模型并提供友好网页界面的最快方式,让任何人都能在任何地方使用它!
为什么要为你的模型创建演示?
因为测试集上的指标虽然看起来不错,但你只有在实际使用中才能真正了解模型的表现。
所以,让我们开始部署吧!
我们将首先使用常见的别名 gr 导入 Gradio,如果它尚未安装,我们将进行安装。
# Import/install Gradio
try:
import gradio as gr
except:
!pip -q install gradio
import gradio as gr
print(f"Gradio version: {gr.__version__}")
Gradio version: 3.1.4
Gradio 准备就绪!
让我们将 FoodVision Mini 转变为一个演示应用程序。
7.1 Gradio 概述¶
Gradio 的整体前提与我们整个课程中反复强调的内容非常相似。
我们的输入和输出是什么?
我们如何实现这一目标?
这就是我们的机器学习模型所做的事情。
输入 -> 机器学习模型 -> 输出
在我们的例子中,对于 FoodVision Mini,我们的输入是食物图片,我们的机器学习模型是 EffNetB2,我们的输出是食物类别(披萨、牛排或寿司)。
食物图片 -> EffNetB2 -> 输出
尽管输入和输出的概念可以桥接到几乎任何其他类型的机器学习问题。
你的输入和输出可能是以下任意组合:
- 图像
- 文本
- 视频
- 表格数据
- 音频
- 数字
- 等等
你构建的机器学习模型将取决于你的输入和输出。
Gradio 通过创建一个从输入到输出的接口(gradio.Interface())来模拟这种范式。
gradio.Interface(fn, inputs, outputs)
其中,fn 是一个将 输入 映射到 输出 的 Python 函数。
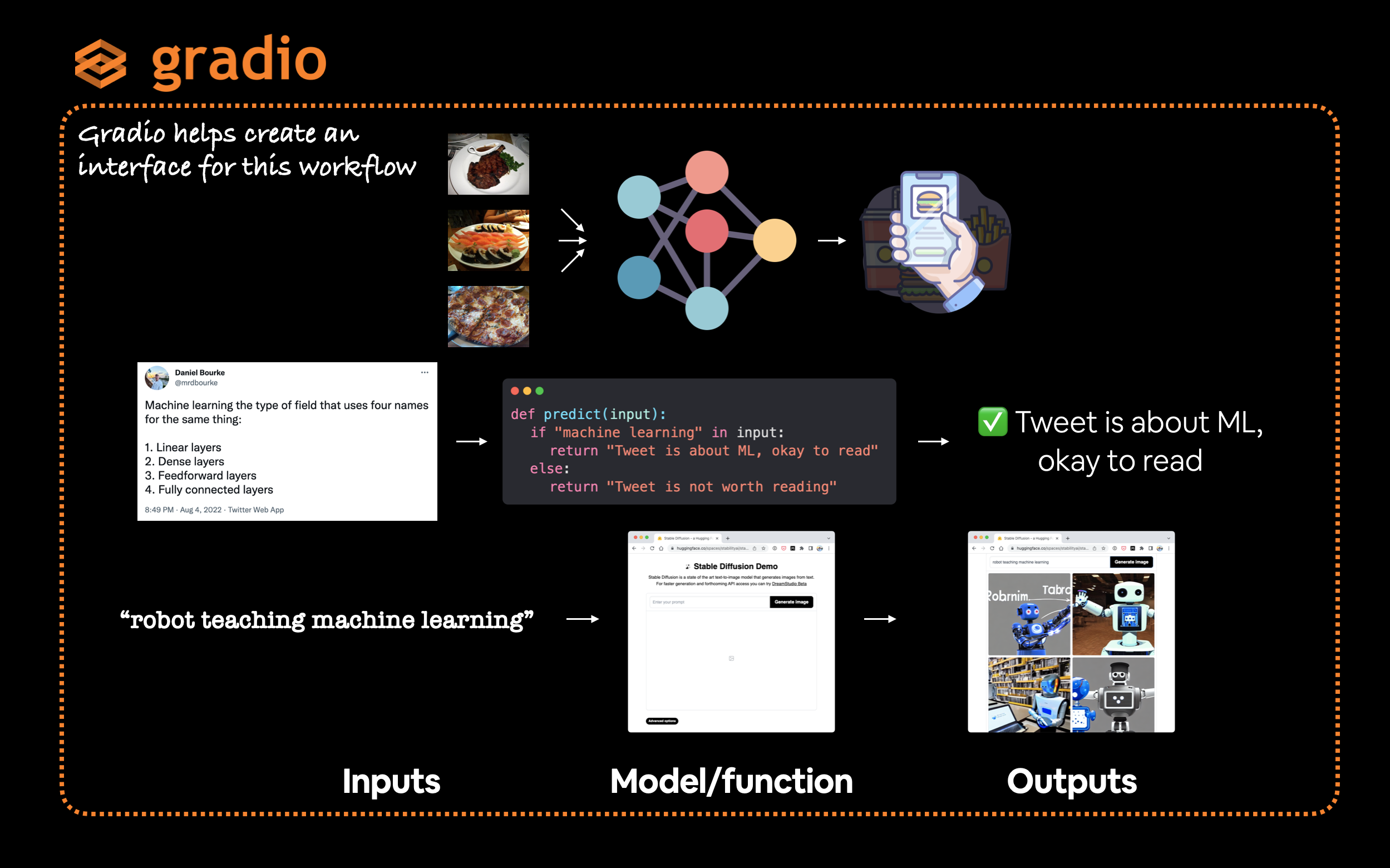
Gradio 提供了一个非常有用的 Interface 类,可以轻松创建一个从输入到模型/函数再到输出的工作流程,其中输入和输出可以是几乎任何你想要的内容。例如,你可能输入推文(文本)来判断它们是否与机器学习相关,或者输入文本提示来生成图像。
注意: Gradio 有大量的可能
输入和输出选项,称为“组件”,从图像到文本到数字到音频到视频等等。你可以在 Gradio 组件文档 中查看所有这些内容。
7.2 创建一个函数来映射我们的输入和输出¶
为了使用 Gradio 创建我们的 FoodVision Mini 演示,我们需要一个函数来将输入映射到输出。
我们之前创建了一个名为 pred_and_store() 的函数,用于使用给定模型对目标文件列表进行预测,并将结果存储在字典列表中。
我们是否可以创建一个类似的函数,但这次专注于使用我们的 EffNetB2 模型对单张图像进行预测?
更具体地说,我们希望一个函数接受图像作为输入,对其进行预处理(变换),使用 EffNetB2 进行预测,然后返回预测结果(简称为 pred 或 pred label)以及预测概率(pred prob)。
同时,我们还可以返回完成这些操作所需的时间:
输入:图像 -> 变换 -> 使用 EffNetB2 预测 -> 输出:预测结果, 预测概率, 时间
这将是我们的 Gradio 接口的 fn 参数。
首先,让我们确保我们的 EffNetB2 模型在 CPU 上(因为我们坚持使用仅 CPU 的预测,但如果你有 GPU 访问权限,可以更改这一点)。
# Put EffNetB2 on CPU
effnetb2.to("cpu")
# Check the device
next(iter(effnetb2.parameters())).device
device(type='cpu')
现在,让我们创建一个名为 predict() 的函数,来复制上述工作流程。
from typing import Tuple, Dict
def predict(img) -> Tuple[Dict, float]:
"""Transforms and performs a prediction on img and returns prediction and time taken.
"""
# Start the timer
start_time = timer()
# Transform the target image and add a batch dimension
img = effnetb2_transforms(img).unsqueeze(0)
# Put model into evaluation mode and turn on inference mode
effnetb2.eval()
with torch.inference_mode():
# Pass the transformed image through the model and turn the prediction logits into prediction probabilities
pred_probs = torch.softmax(effnetb2(img), dim=1)
# Create a prediction label and prediction probability dictionary for each prediction class (this is the required format for Gradio's output parameter)
pred_labels_and_probs = {class_names[i]: float(pred_probs[0][i]) for i in range(len(class_names))}
# Calculate the prediction time
pred_time = round(timer() - start_time, 5)
# Return the prediction dictionary and prediction time
return pred_labels_and_probs, pred_time
太棒了!
现在让我们通过在测试数据集中随机选择一张图像进行预测,来看看我们的函数实际运行效果。
首先,我们将从测试目录中获取所有图像路径的列表,然后随机选择一个。
接着,我们将使用 PIL.Image.open() 打开随机选择的图像。
最后,我们将图像传递给我们的 predict() 函数。
import random
from PIL import Image
# Get a list of all test image filepaths
test_data_paths = list(Path(test_dir).glob("*/*.jpg"))
# Randomly select a test image path
random_image_path = random.sample(test_data_paths, k=1)[0]
# Open the target image
image = Image.open(random_image_path)
print(f"[INFO] Predicting on image at path: {random_image_path}\n")
# Predict on the target image and print out the outputs
pred_dict, pred_time = predict(img=image)
print(f"Prediction label and probability dictionary: \n{pred_dict}")
print(f"Prediction time: {pred_time} seconds")
[INFO] Predicting on image at path: data/pizza_steak_sushi_20_percent/test/pizza/3770514.jpg
Prediction label and probability dictionary:
{'pizza': 0.9785208702087402, 'steak': 0.01169557310640812, 'sushi': 0.009783552028238773}
Prediction time: 0.027 seconds
太棒了!
多次运行上面的单元格,我们可以看到EffNetB2模型对每个标签的不同预测概率,以及每次预测所需的时间。
# Create a list of example inputs to our Gradio demo
example_list = [[str(filepath)] for filepath in random.sample(test_data_paths, k=3)]
example_list
[['data/pizza_steak_sushi_20_percent/test/sushi/804460.jpg'], ['data/pizza_steak_sushi_20_percent/test/steak/746921.jpg'], ['data/pizza_steak_sushi_20_percent/test/steak/2117351.jpg']]
完美!
我们的 Gradio 演示将展示这些作为示例输入,以便人们可以尝试并了解其功能,而无需上传任何自己的数据。
7.4 构建一个 Gradio 界面¶
现在是时候把所有内容整合起来,让我们的 FoodVision Mini 演示活起来了!
让我们创建一个 Gradio 界面来复制以下工作流程:
输入:图像 -> 转换 -> 使用 EffNetB2 预测 -> 输出:预测结果、预测概率、耗时
我们可以使用 gradio.Interface() 类,并设置以下参数:
fn- 一个将inputs映射到outputs的 Python 函数,在我们的例子中,我们将使用predict()函数。inputs- 我们界面的输入,例如使用gradio.Image()或"image"的图像。outputs- 输入经过fn处理后的输出,例如使用gradio.Label()的标签(用于模型的预测标签)或使用gradio.Number()的数字(用于模型的预测时间)。- 注意: Gradio 提供了许多内置的
inputs和outputs选项,称为 "Components"。
- 注意: Gradio 提供了许多内置的
examples- 展示给用户的示例列表。title- 演示的标题字符串。description- 演示的描述字符串。article- 演示底部引用的注释。
一旦我们创建了 gr.Interface() 的演示实例,我们可以使用 gradio.Interface().launch() 或 demo.launch() 命令来启动它。
很简单!
import gradio as gr
# Create title, description and article strings
title = "FoodVision Mini 🍕🥩🍣"
description = "An EfficientNetB2 feature extractor computer vision model to classify images of food as pizza, steak or sushi."
article = "Created at [09. PyTorch Model Deployment](https://www.learnpytorch.io/09_pytorch_model_deployment/)."
# Create the Gradio demo
demo = gr.Interface(fn=predict, # mapping function from input to output
inputs=gr.Image(type="pil"), # what are the inputs?
outputs=[gr.Label(num_top_classes=3, label="Predictions"), # what are the outputs?
gr.Number(label="Prediction time (s)")], # our fn has two outputs, therefore we have two outputs
examples=example_list,
title=title,
description=description,
article=article)
# Launch the demo!
demo.launch(debug=False, # print errors locally?
share=True) # generate a publically shareable URL?
Running on local URL: http://127.0.0.1:7860/ Running on public URL: https://27541.gradio.app This share link expires in 72 hours. For free permanent hosting, check out Spaces: https://huggingface.co/spaces
(<gradio.routes.App at 0x7f122dd0f0d0>, 'http://127.0.0.1:7860/', 'https://27541.gradio.app')

FoodVision Mini Gradio 演示在 Google Colab 和浏览器中运行(从 Google Colab 运行的链接仅持续 72 小时)。你可以查看 Hugging Face Spaces 上的永久在线演示。
哇哦!!!多么精彩的演示!!!
FoodVision Mini 已经正式在一个人们可以使用和尝试的界面上活了起来。
如果你在 launch() 方法中设置参数 share=True,Gradio 还会为你提供一个可分享的链接,例如 https://123XYZ.gradio.app(此链接仅为示例,可能已过期),该链接有效期为 72 小时。
该链接提供了一个返回你启动的 Gradio 界面的代理。
对于更长期的托管,你可以将你的 Gradio 应用上传到 Hugging Face Spaces 或其他任何可以运行 Python 代码的地方。
8. 将我们的 FoodVision Mini Gradio 演示转化为可部署的应用¶
我们已经见证了 FoodVision Mini 模型通过 Gradio 演示变得生动起来。
但如果我们想与朋友们分享它呢?
我们可以使用提供的 Gradio 链接,然而,共享链接仅持续 72 小时。
为了让我们的 FoodVision Mini 演示更加持久,我们可以将其打包成一个应用并上传到 Hugging Face Spaces。
8.1 什么是 Hugging Face Spaces?¶
Hugging Face Spaces 是一个资源,允许你托管和分享机器学习应用。
构建一个演示是展示和测试你所做工作的最佳方式之一。
而 Spaces 正是为此而设计的。
你可以将 Hugging Face 视为机器学习的 GitHub。
如果拥有一个优秀的 GitHub 作品集展示了你的编程能力,那么拥有一个优秀的 Hugging Face 作品集则可以展示你的机器学习能力。
注意: 我们还可以将 Gradio 应用上传并托管到其他许多地方,例如 Google Cloud、AWS(亚马逊网络服务)或其他云服务提供商,但由于 Hugging Face Spaces 的使用便捷性和广泛被机器学习社区采用,我们将使用 Hugging Face Spaces。
8.2 部署的 Gradio 应用结构¶
为了上传我们的 Gradio 演示应用,我们需要将与之相关的所有内容放入一个单独的目录中。
例如,我们的演示可能位于路径 demos/foodvision_mini/,其文件结构如下:
demos/
└── foodvision_mini/
├── 09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth
├── app.py
├── examples/
│ ├── example_1.jpg
│ ├── example_2.jpg
│ └── example_3.jpg
├── model.py
└── requirements.txt
其中:
09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth是我们训练好的 PyTorch 模型文件。app.py包含我们的 Gradio 应用(类似于启动应用的代码)。- 注意:
app.py是 Hugging Face Spaces 使用的默认文件名,如果你将应用部署在那里,Spaces 默认会寻找名为app.py的文件来运行。这个文件名可以在设置中更改。
- 注意:
examples/包含用于 Gradio 应用的示例图像。model.py包含模型定义以及与模型相关的任何变换。requirements.txt包含运行应用所需的依赖项,如torch、torchvision和gradio。
为什么要这样组织?
因为这是我们可以开始的最简单的布局之一。
我们的重点是:实验、实验、实验!
我们能够更快地运行较小的实验,那么我们的较大实验就会更好。
我们将逐步重现上述结构,但你也可以在 Hugging Face Spaces 上查看正在运行的实时演示应用以及文件结构:
8.3 创建 demos 文件夹以存储我们的 FoodVision Mini 应用文件¶
首先,让我们创建一个 demos/ 目录,用于存储所有 FoodVision Mini 应用文件。
我们可以使用 Python 的 pathlib.Path("path_to_dir") 来建立目录路径,并使用 pathlib.Path("path_to_dir").mkdir() 来创建该目录。
import shutil
from pathlib import Path
# Create FoodVision mini demo path
foodvision_mini_demo_path = Path("demos/foodvision_mini/")
# Remove files that might already exist there and create new directory
if foodvision_mini_demo_path.exists():
shutil.rmtree(foodvision_mini_demo_path)
foodvision_mini_demo_path.mkdir(parents=True, # make the parent folders?
exist_ok=True) # create it even if it already exists?
else:
# If the file doesn't exist, create it anyway
foodvision_mini_demo_path.mkdir(parents=True,
exist_ok=True)
# Check what's in the folder
!ls demos/foodvision_mini/
8.4 创建一个包含示例图像的文件夹,用于我们的 FoodVision Mini 演示¶
现在我们已经有了一个用于存储 FoodVision Mini 演示文件的目录,接下来让我们添加一些示例图像。
从测试数据集中选择三张示例图像应该足够了。
为此,我们将:
- 在
demos/foodvision_mini目录中创建一个examples/子目录。 - 从测试数据集中随机选择三张图像,并将它们的文件路径收集到一个列表中。
- 将这三张随机选择的测试数据集图像复制到
demos/foodvision_mini/examples/目录中。
import shutil
from pathlib import Path
# 1. Create an examples directory
foodvision_mini_examples_path = foodvision_mini_demo_path / "examples"
foodvision_mini_examples_path.mkdir(parents=True, exist_ok=True)
# 2. Collect three random test dataset image paths
foodvision_mini_examples = [Path('data/pizza_steak_sushi_20_percent/test/sushi/592799.jpg'),
Path('data/pizza_steak_sushi_20_percent/test/steak/3622237.jpg'),
Path('data/pizza_steak_sushi_20_percent/test/pizza/2582289.jpg')]
# 3. Copy the three random images to the examples directory
for example in foodvision_mini_examples:
destination = foodvision_mini_examples_path / example.name
print(f"[INFO] Copying {example} to {destination}")
shutil.copy2(src=example, dst=destination)
[INFO] Copying data/pizza_steak_sushi_20_percent/test/sushi/592799.jpg to demos/foodvision_mini/examples/592799.jpg [INFO] Copying data/pizza_steak_sushi_20_percent/test/steak/3622237.jpg to demos/foodvision_mini/examples/3622237.jpg [INFO] Copying data/pizza_steak_sushi_20_percent/test/pizza/2582289.jpg to demos/foodvision_mini/examples/2582289.jpg
现在,为了确认我们的示例文件已存在,让我们使用os.listdir()列出demos/foodvision_mini/examples/目录的内容,然后将文件路径格式化为列表的列表(以便与Gradio的gradio.Interface()的example参数兼容)。
import os
# Get example filepaths in a list of lists
example_list = [["examples/" + example] for example in os.listdir(foodvision_mini_examples_path)]
example_list
[['examples/3622237.jpg'], ['examples/592799.jpg'], ['examples/2582289.jpg']]
8.5 将我们训练好的EffNetB2模型移动到FoodVision Mini演示目录¶
我们之前将FoodVision Mini的EffNetB2特征提取器模型保存在models/09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth路径下。
为了避免重复保存模型文件,我们将该模型移动到demos/foodvision_mini目录中。
我们可以使用Python的shutil.move()方法,并传入src(目标文件的源路径)和dst(目标文件要移动到的目标路径)参数来实现这一操作。
import shutil
# Create a source path for our target model
effnetb2_foodvision_mini_model_path = "models/09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth"
# Create a destination path for our target model
effnetb2_foodvision_mini_model_destination = foodvision_mini_demo_path / effnetb2_foodvision_mini_model_path.split("/")[1]
# Try to move the file
try:
print(f"[INFO] Attempting to move {effnetb2_foodvision_mini_model_path} to {effnetb2_foodvision_mini_model_destination}")
# Move the model
shutil.move(src=effnetb2_foodvision_mini_model_path,
dst=effnetb2_foodvision_mini_model_destination)
print(f"[INFO] Model move complete.")
# If the model has already been moved, check if it exists
except:
print(f"[INFO] No model found at {effnetb2_foodvision_mini_model_path}, perhaps its already been moved?")
print(f"[INFO] Model exists at {effnetb2_foodvision_mini_model_destination}: {effnetb2_foodvision_mini_model_destination.exists()}")
[INFO] Attempting to move models/09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth to demos/foodvision_mini/09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth [INFO] Model move complete.
8.6 将我们的EffNetB2模型转换为Python脚本(model.py)¶
我们当前模型的state_dict已保存到demos/foodvision_mini/09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth。
为了加载它,我们可以使用model.load_state_dict()以及torch.load()。
注意: 关于保存和加载模型(或PyTorch中模型的
state_dict)的复习,请参阅01. PyTorch工作流程基础 第5节:保存和加载PyTorch模型,或参阅PyTorch的教程PyTorch中的state_dict是什么?
但在我们能够这样做之前,我们首先需要一种方法来实例化一个model。
为了以模块化的方式实现这一点,我们将创建一个名为model.py的脚本,其中包含我们在第3.1节:创建一个函数来制作EffNetB2特征提取器中创建的create_effnetb2_model()函数。
这样我们就可以在另一个脚本(见下面的app.py)中导入该函数,然后使用它来创建我们的EffNetB2 model实例,并获取其适当的转换。
就像在05. PyTorch模块化中一样,我们将使用%%writefile path/to/file魔法命令将代码单元格转换为文件。
%%writefile demos/foodvision_mini/model.py
import torch
import torchvision
from torch import nn
def create_effnetb2_model(num_classes:int=3,
seed:int=42):
"""Creates an EfficientNetB2 feature extractor model and transforms.
Args:
num_classes (int, optional): number of classes in the classifier head.
Defaults to 3.
seed (int, optional): random seed value. Defaults to 42.
Returns:
model (torch.nn.Module): EffNetB2 feature extractor model.
transforms (torchvision.transforms): EffNetB2 image transforms.
"""
# Create EffNetB2 pretrained weights, transforms and model
weights = torchvision.models.EfficientNet_B2_Weights.DEFAULT
transforms = weights.transforms()
model = torchvision.models.efficientnet_b2(weights=weights)
# Freeze all layers in base model
for param in model.parameters():
param.requires_grad = False
# Change classifier head with random seed for reproducibility
torch.manual_seed(seed)
model.classifier = nn.Sequential(
nn.Dropout(p=0.3, inplace=True),
nn.Linear(in_features=1408, out_features=num_classes),
)
return model, transforms
Writing demos/foodvision_mini/model.py
8.7 将我们的 FoodVision Mini Gradio 应用转换为 Python 脚本 (app.py)¶
现在我们已经有了一个 model.py 脚本以及一个可以加载的保存模型 state_dict 的路径。
是时候构建 app.py 了。
我们将其命名为 app.py,因为默认情况下,当你创建一个 HuggingFace Space 时,它会寻找一个名为 app.py 的文件来运行和托管(尽管你可以在设置中更改这一点)。
我们的 app.py 脚本将把所有拼图的碎片组合在一起,创建我们的 Gradio 演示,并将有四个主要部分:
- 导入和类名设置 - 在这里,我们将导入演示所需的各种依赖项,包括来自
model.py的create_effnetb2_model()函数,以及设置我们的 FoodVision Mini 应用的不同类名。 - 模型和转换准备 - 在这里,我们将创建一个 EffNetB2 模型实例以及与之对应的转换,然后我们将加载保存的模型权重/
state_dict。当我们加载模型时,我们还会在torch.load()中设置map_location=torch.device("cpu"),以便我们的模型无论在哪个设备上训练,都会被加载到 CPU 上(我们这样做是因为在部署时我们不一定有 GPU,如果我们的模型在 GPU 上训练但在没有明确说明的情况下尝试部署到 CPU 上,我们会得到一个错误)。 - 预测函数 - Gradio 的
gradio.Interface()接受一个fn参数来映射输入到输出,我们的predict()函数将与我们在 第 7.2 节:创建一个函数来映射我们的输入和输出 中定义的函数相同,它将接收一张图像,然后使用加载的转换对其进行预处理,再使用加载的模型对其进行预测。- 注意: 我们需要通过
examples参数动态创建示例列表。我们可以通过创建examples/目录中的文件列表来实现:[["examples/" + example] for example in os.listdir("examples")]。
- 注意: 我们需要通过
- Gradio 应用 - 这是我们演示的主要逻辑所在,我们将创建一个名为
demo的gradio.Interface()实例,将我们的输入、predict()函数和输出组合在一起。最后,我们将通过调用demo.launch()来启动我们的 FoodVision Mini 演示!
%%writefile demos/foodvision_mini/app.py
### 1. Imports and class names setup ###
import gradio as gr
import os
import torch
from model import create_effnetb2_model
from timeit import default_timer as timer
from typing import Tuple, Dict
# Setup class names
class_names = ["pizza", "steak", "sushi"]
### 2. Model and transforms preparation ###
# Create EffNetB2 model
effnetb2, effnetb2_transforms = create_effnetb2_model(
num_classes=3, # len(class_names) would also work
)
# Load saved weights
effnetb2.load_state_dict(
torch.load(
f="09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth",
map_location=torch.device("cpu"), # load to CPU
)
)
### 3. Predict function ###
# Create predict function
def predict(img) -> Tuple[Dict, float]:
"""Transforms and performs a prediction on img and returns prediction and time taken.
"""
# Start the timer
start_time = timer()
# Transform the target image and add a batch dimension
img = effnetb2_transforms(img).unsqueeze(0)
# Put model into evaluation mode and turn on inference mode
effnetb2.eval()
with torch.inference_mode():
# Pass the transformed image through the model and turn the prediction logits into prediction probabilities
pred_probs = torch.softmax(effnetb2(img), dim=1)
# Create a prediction label and prediction probability dictionary for each prediction class (this is the required format for Gradio's output parameter)
pred_labels_and_probs = {class_names[i]: float(pred_probs[0][i]) for i in range(len(class_names))}
# Calculate the prediction time
pred_time = round(timer() - start_time, 5)
# Return the prediction dictionary and prediction time
return pred_labels_and_probs, pred_time
### 4. Gradio app ###
# Create title, description and article strings
title = "FoodVision Mini 🍕🥩🍣"
description = "An EfficientNetB2 feature extractor computer vision model to classify images of food as pizza, steak or sushi."
article = "Created at [09. PyTorch Model Deployment](https://www.learnpytorch.io/09_pytorch_model_deployment/)."
# Create examples list from "examples/" directory
example_list = [["examples/" + example] for example in os.listdir("examples")]
# Create the Gradio demo
demo = gr.Interface(fn=predict, # mapping function from input to output
inputs=gr.Image(type="pil"), # what are the inputs?
outputs=[gr.Label(num_top_classes=3, label="Predictions"), # what are the outputs?
gr.Number(label="Prediction time (s)")], # our fn has two outputs, therefore we have two outputs
# Create examples list from "examples/" directory
examples=example_list,
title=title,
description=description,
article=article)
# Launch the demo!
demo.launch()
Writing demos/foodvision_mini/app.py
8.8 为 FoodVision Mini 创建需求文件 (requirements.txt)¶
我们需要为 FoodVision Mini 应用创建的最后一个文件是 requirements.txt 文件。
这将是一个包含我们演示所需所有依赖项的文本文件。
当我们将演示应用部署到 Hugging Face Spaces 时,它会搜索这个文件并安装我们定义的依赖项,以便我们的应用能够运行。
好消息是,只有三个!
torch==1.12.0torchvision==0.13.0gradio==3.1.4
"==1.12.0" 表示要安装的版本号。
定义版本号并不是 100% 必需的,但我们现在会这样做,以便在未来发布中出现任何破坏性更新时,我们的应用仍然能够运行(PS:如果你发现任何错误,欢迎在课程 GitHub Issues 上发帖)。
%%writefile demos/foodvision_mini/requirements.txt
torch==1.12.0
torchvision==0.13.0
gradio==3.1.4
Writing demos/foodvision_mini/requirements.txt
太棒了!
我们已经正式集齐了部署FoodVision Mini演示所需的所有文件!
9. 将我们的 FoodVision Mini 应用部署到 HuggingFace Spaces¶
我们已经有了包含 FoodVision Mini 演示的文件,现在如何让它在 Hugging Face Spaces 上运行呢?
上传到 Hugging Face Space(也称为 Hugging Face 仓库,类似于 git 仓库)主要有两种方式:
- 通过 Hugging Face 网页界面上传(最简单)。
- 通过命令行或终端上传。
- 额外提示: 你还可以使用
huggingface_hub库 与 Hugging Face 进行交互,这是上述两种选项的良好扩展。
- 额外提示: 你还可以使用
你可以自由阅读这两种选项的文档,但我们选择第二种方式。
注意: 要在 Hugging Face 上托管任何内容,你需要注册一个免费的 Hugging Face 账户。
9.1 下载我们的 FoodVision Mini 应用文件¶
让我们查看一下 demos/foodvision_mini 目录中的演示文件。
为此,我们可以使用 !ls 命令,后跟目标文件路径。
ls 代表“列出”,而 ! 表示我们希望在 shell 级别执行该命令。
!ls demos/foodvision_mini
09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth app.py examples model.py requirements.txt
这些是我们创建的所有文件!
要开始将我们的文件上传到 Hugging Face,让我们现在从 Google Colab(或您运行此笔记本的任何地方)下载它们。
为此,我们首先通过以下命令将文件压缩到一个单独的 zip 文件夹中:
zip -r ../foodvision_mini.zip * -x "*.pyc" "*.ipynb" "*__pycache__*" "*ipynb_checkpoints*"
其中:
zip表示“压缩”,即“请将以下目录中的文件压缩在一起”。-r表示“递归”,即“遍历目标目录中的所有文件”。../foodvision_mini.zip是我们希望文件被压缩到的目标目录。*表示“当前目录中的所有文件”。-x表示“排除这些文件”。
我们可以使用 google.colab.files.download("demos/foodvision_mini.zip") 从 Google Colab 下载我们的 zip 文件(我们将把这个放在 try 和 except 块中,以防我们不在 Google Colab 中运行代码,如果是这样,我们将打印一条消息,提示手动下载文件)。
让我们试试看!
# Change into and then zip the foodvision_mini folder but exclude certain files
!cd demos/foodvision_mini && zip -r ../foodvision_mini.zip * -x "*.pyc" "*.ipynb" "*__pycache__*" "*ipynb_checkpoints*"
# Download the zipped FoodVision Mini app (if running in Google Colab)
try:
from google.colab import files
files.download("demos/foodvision_mini.zip")
except:
print("Not running in Google Colab, can't use google.colab.files.download(), please manually download.")
updating: 09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth (deflated 8%) updating: app.py (deflated 57%) updating: examples/ (stored 0%) updating: examples/3622237.jpg (deflated 0%) updating: examples/592799.jpg (deflated 1%) updating: examples/2582289.jpg (deflated 17%) updating: model.py (deflated 56%) updating: requirements.txt (deflated 4%) Not running in Google Colab, can't use google.colab.files.download(), please manually download.
哇哦!
看来我们的 zip 命令执行成功了。
如果你是在 Google Colab 上运行这个笔记本,你应该会在浏览器中看到一个文件开始下载。
否则,你可以在 课程 GitHub 的 demos/ 目录下 找到 foodvision_mini.zip 文件夹(以及更多内容)。
9.2 在本地运行我们的 FoodVision Mini 演示¶
如果你下载了 foodvision_mini.zip 文件,可以通过以下步骤在本地测试它:
- 解压缩文件。
- 打开终端或命令行提示符。
- 切换到
foodvision_mini目录(cd foodvision_mini)。 - 创建一个环境(
python3 -m venv env)。 - 激活环境(
source env/bin/activate)。 - 安装需求文件(
pip install -r requirements.txt,"-r" 表示递归)。- 注意: 这一步可能需要 5-10 分钟,具体取决于你的网络连接。如果你遇到错误,可能需要先升级
pip:pip install --upgrade pip。
- 注意: 这一步可能需要 5-10 分钟,具体取决于你的网络连接。如果你遇到错误,可能需要先升级
- 运行应用(
python3 app.py)。
这将导致一个 Gradio 演示程序,就像我们上面构建的那样,在你的机器上本地运行,URL 可能是 http://127.0.0.1:7860/。
注意: 如果你在本地运行应用,并且注意到一个
flagged/目录出现,它包含已经被“标记”的样本。例如,如果有人尝试使用演示程序,而模型产生了错误的结果,该样本可以被“标记”并留待后续审查。
有关 Gradio 中的标记功能的更多信息,请参阅 标记文档。
9.3 上传到 Hugging Face¶
我们已经验证了 FoodVision Mini 应用在本地运行正常,但是创建机器学习演示的乐趣在于向其他人展示并允许他们使用它。
为此,我们将把 FoodVision Mini 演示上传到 Hugging Face。
注意: 以下步骤系列使用 Git(一个文件跟踪系统)工作流程。要了解 Git 的工作原理,建议通过 freeCodeCamp 上的 Git 和 GitHub 初学者教程。
- 注册 一个 Hugging Face 账户。
- 通过访问您的个人资料并点击“New Space” 来创建一个新的 Hugging Face Space。
- 注意: Hugging Face 中的 Space 也被称为“代码仓库”(存储代码/文件的地方),简称“repo”。
- 给 Space 命名,例如,我的是
mrdbourke/foodvision_mini,您可以在这里看到:https://huggingface.co/spaces/mrdbourke/foodvision_mini - 选择一个许可证(我使用了 MIT)。
- 选择 Gradio 作为 Space SDK(软件开发工具包)。
- 注意: 您可以使用其他选项,如 Streamlit,但由于我们的应用是基于 Gradio 构建的,我们将继续使用 Gradio。
- 选择您的 Space 是公开的还是私有的(我选择了公开,因为我希望我的 Space 对其他人可用)。
- 点击“Create Space”。
- 通过在终端或命令提示符中运行类似
git clone https://huggingface.co/spaces/[YOUR_USERNAME]/[YOUR_SPACE_NAME]的命令,将仓库克隆到本地。- 注意: 您也可以通过在“Files and versions”标签下上传文件来添加文件。
- 将下载的
foodvision_mini文件夹的内容复制/移动到克隆的仓库文件夹中。 - 要上传和跟踪较大的文件(例如超过 10MB 的文件,或者在我们的例子中,PyTorch 模型文件),您需要安装 Git LFS(即“git 大文件存储”)。
- 安装 Git LFS 后,您可以通过运行
git lfs install来激活它。 - 在
foodvision_mini目录中,使用 Git LFS 跟踪超过 10MB 的文件,命令为git lfs track "*.file_extension"。- 跟踪 EffNetB2 PyTorch 模型文件,命令为
git lfs track "09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth"。
- 跟踪 EffNetB2 PyTorch 模型文件,命令为
- 跟踪
.gitattributes文件(从 HuggingFace 克隆时自动创建,该文件将帮助确保我们的大文件通过 Git LFS 进行跟踪)。您可以在 FoodVision Mini Hugging Face Space 上看到一个示例.gitattributes文件。git add .gitattributes
- 添加
foodvision_mini应用的其他文件并提交它们:git add *git commit -m "first commit"
- 推送(上传)文件到 Hugging Face:
git push
- 等待 3-5 分钟让构建完成(未来的构建会更快),您的应用就会上线!
如果一切顺利,您应该会看到一个像这里一样的 FoodVision Mini Gradio 演示的实时运行示例:https://huggingface.co/spaces/mrdbourke/foodvision_mini
我们甚至可以将 FoodVision Mini Gradio 演示嵌入到我们的笔记本中作为一个 iframe,使用 IPython.display.IFrame 和链接格式 https://hf.space/embed/[YOUR_USERNAME]/[YOUR_SPACE_NAME]/+。
# IPython is a library to help make Python interactive
from IPython.display import IFrame
# Embed FoodVision Mini Gradio demo
IFrame(src="https://hf.space/embed/mrdbourke/foodvision_mini/+", width=900, height=750)
10. 创建 FoodVision Big¶
在前几节和章节中,我们一直在努力将 FoodVision Mini 变为现实。
现在我们已经看到它在实时演示中运行,不如我们再提升一个档次?
怎么做?
FoodVision Big!
既然 FoodVision Mini 是基于 Food101 数据集(101 种食物 x 每种 1000 张图片)中的披萨、牛排和寿司图片进行训练的,我们何不通过训练一个涵盖所有 101 个类别的模型来打造 FoodVision Big 呢?
我们将从三个类别扩展到 101 个类别!
从披萨、牛排、寿司扩展到披萨、牛排、寿司、热狗、苹果派、胡萝卜蛋糕、巧克力蛋糕、薯条、蒜蓉面包、拉面、玉米片、塔可等等!
怎么做?
我们已经有了所有的步骤,我们只需要稍微调整我们的 EffNetB2 模型,并准备一个不同的数据集。
为了完成第三阶段项目,让我们重新创建一个类似于 FoodVision Mini(三个类别)的 Gradio 演示,但这次是为 FoodVision Big(101 个类别)。

FoodVision Mini 适用于三个食物类别:披萨、牛排和寿司。而 FoodVision Big 则提升了一个档次,适用于 101 个食物类别:所有 Food101 数据集中的类别。
# Create EffNetB2 model capable of fitting to 101 classes for Food101
effnetb2_food101, effnetb2_transforms = create_effnetb2_model(num_classes=101)
太棒了!
现在让我们来获取模型的总结信息。
from torchinfo import summary
# # Get a summary of EffNetB2 feature extractor for Food101 with 101 output classes (uncomment for full output)
# summary(effnetb2_food101,
# input_size=(1, 3, 224, 224),
# col_names=["input_size", "output_size", "num_params", "trainable"],
# col_width=20,
# row_settings=["var_names"])
太棒了!
看看我们的 EffNetB2 模型是如何与 FoodVision Mini 相似的,基础层被冻结(这些层在 ImageNet 上进行了预训练),而外层(分类器层)是可训练的,输出形状为 [batch_size, 101](101 代表 Food101 中的 101 个类别)。
现在,由于我们将处理比平时更多的数据,我们不妨在变换(effnetb2_transforms)中增加一些数据增强,以增强训练数据。
注意: 数据增强是一种技术,用于改变输入训练样本的外观(例如旋转图像或轻微扭曲),以人工增加训练数据集的多样性,希望防止过拟合。你可以在 04. PyTorch 自定义数据集 第6节 中了解更多关于数据增强的内容。
让我们组合一个 torchvision.transforms 管道,使用 torchvision.transforms.TrivialAugmentWide()(与 PyTorch 团队在其计算机视觉食谱中使用的相同数据增强)以及 effnetb2_transforms 来变换我们的训练图像。
# Create Food101 training data transforms (only perform data augmentation on the training images)
food101_train_transforms = torchvision.transforms.Compose([
torchvision.transforms.TrivialAugmentWide(),
effnetb2_transforms,
])
太棒了!
现在我们来比较一下 food101_train_transforms(用于训练数据)和 effnetb2_transforms(用于测试/推理数据)。
print(f"Training transforms:\n{food101_train_transforms}\n")
print(f"Testing transforms:\n{effnetb2_transforms}")
Training transforms:
Compose(
TrivialAugmentWide(num_magnitude_bins=31, interpolation=InterpolationMode.NEAREST, fill=None)
ImageClassification(
crop_size=[288]
resize_size=[288]
mean=[0.485, 0.456, 0.406]
std=[0.229, 0.224, 0.225]
interpolation=InterpolationMode.BICUBIC
)
)
Testing transforms:
ImageClassification(
crop_size=[288]
resize_size=[288]
mean=[0.485, 0.456, 0.406]
std=[0.229, 0.224, 0.225]
interpolation=InterpolationMode.BICUBIC
)
10.2 获取 FoodVision Big 的数据¶
对于 FoodVision Mini,我们自己制作了整个 Food101 数据集的自定义数据分割。
要获取整个 Food101 数据集,我们可以使用 torchvision.datasets.Food101()。
我们首先设置一个路径到 data/ 目录来存储图像。
然后,我们将使用 food101_train_transforms 和 effnetb2_transforms 分别转换训练和测试数据集分割,下载并转换这些数据集。
注意: 如果你使用的是 Google Colab,下面的单元格将需要大约 3-5 分钟来完全运行并从 PyTorch 下载 Food101 图像。
这是因为要下载超过 10 万张图像(101 个类别 x 每个类别 1000 张图像)。如果你重启了 Google Colab 运行时并返回到这个单元格,图像将需要重新下载。或者,如果你在本地运行这个笔记本,图像将被缓存并存储在
torchvision.datasets.Food101()的root参数指定的目录中。
from torchvision import datasets
# Setup data directory
from pathlib import Path
data_dir = Path("data")
# Get training data (~750 images x 101 food classes)
train_data = datasets.Food101(root=data_dir, # path to download data to
split="train", # dataset split to get
transform=food101_train_transforms, # perform data augmentation on training data
download=True) # want to download?
# Get testing data (~250 images x 101 food classes)
test_data = datasets.Food101(root=data_dir,
split="test",
transform=effnetb2_transforms, # perform normal EffNetB2 transforms on test data
download=True)
数据已下载!
现在我们可以使用 train_data.classes 获取所有类别名称的列表。
# Get Food101 class names
food101_class_names = train_data.classes
# View the first 10
food101_class_names[:10]
['apple_pie', 'baby_back_ribs', 'baklava', 'beef_carpaccio', 'beef_tartare', 'beet_salad', 'beignets', 'bibimbap', 'bread_pudding', 'breakfast_burrito']
呵呵!那些听起来真是美味的食物(虽然我从未听说过“贝奈特饼”...更新:经过快速谷歌搜索后,贝奈特饼看起来也很美味)。
你可以在课程的GitHub上查看Food101类的完整名称列表,位于 extras/food101_class_names.txt。
10.3 创建 Food101 数据集的子集以加快实验速度¶
这一部分是可选的。
我们并不必须创建另一个 Food101 数据集的子集,我们完全可以对整个包含 101,000 张图片的数据集进行模型训练和评估。
但为了保持训练速度,我们创建一个包含训练集和测试集各 20% 的子集。
我们的目标是看看是否能仅用 20% 的数据就超越原始 Food101 论文 的最佳结果。
以下是我们使用/将使用的数据集细分:
| 笔记本编号 | 项目名称 | 数据集 | 类别数量 | 训练图像数量 | 测试图像数量 |
|---|---|---|---|---|---|
| 04, 05, 06, 07, 08 | FoodVision Mini (10% 数据) | Food101 自定义分割 | 3 (披萨、牛排、寿司) | 225 | 75 |
| 07, 08, 09 | FoodVision Mini (20% 数据) | Food101 自定义分割 | 3 (披萨、牛排、寿司) | 450 | 150 |
| 09 (本笔记本) | FoodVision Big (20% 数据) | Food101 自定义分割 | 101 (所有 Food101 类别) | 15150 | 5050 |
| 扩展 | FoodVision Big | Food101 全部数据 | 101 | 75750 | 25250 |
你能看出其中的趋势吗?
就像我们模型的规模逐渐增大一样,我们用于实验的数据集规模也在逐渐增大。
注意: 要真正用 20% 的数据超越原始 Food101 论文的结果,我们需要在 20% 的训练数据上训练模型,然后在整个测试集上评估我们的模型,而不是在我们创建的分割数据上。我将其留作一个扩展练习,供你尝试。我也鼓励你尝试在整个 Food101 训练数据集上训练模型。
为了创建我们的 FoodVision Big (20% 数据) 分割,我们定义一个名为 split_dataset() 的函数,用于将给定数据集按特定比例分割。
我们可以使用 torch.utils.data.random_split() 通过 lengths 参数创建指定大小的分割。
lengths 参数接受一个期望分割长度的列表,列表的总和必须等于数据集的总长度。
例如,对于一个大小为 100 的数据集,你可以传入 lengths=[20, 80] 来获得 20% 和 80% 的分割。
我们希望函数返回两个分割,一个包含目标长度(例如训练数据的 20%),另一个包含剩余长度(例如训练数据的剩余 80%)。
最后,我们将 generator 参数设置为 torch.manual_seed() 值,以确保可重复性。
def split_dataset(dataset:torchvision.datasets, split_size:float=0.2, seed:int=42):
"""Randomly splits a given dataset into two proportions based on split_size and seed.
Args:
dataset (torchvision.datasets): A PyTorch Dataset, typically one from torchvision.datasets.
split_size (float, optional): How much of the dataset should be split?
E.g. split_size=0.2 means there will be a 20% split and an 80% split. Defaults to 0.2.
seed (int, optional): Seed for random generator. Defaults to 42.
Returns:
tuple: (random_split_1, random_split_2) where random_split_1 is of size split_size*len(dataset) and
random_split_2 is of size (1-split_size)*len(dataset).
"""
# Create split lengths based on original dataset length
length_1 = int(len(dataset) * split_size) # desired length
length_2 = len(dataset) - length_1 # remaining length
# Print out info
print(f"[INFO] Splitting dataset of length {len(dataset)} into splits of size: {length_1} ({int(split_size*100)}%), {length_2} ({int((1-split_size)*100)}%)")
# Create splits with given random seed
random_split_1, random_split_2 = torch.utils.data.random_split(dataset,
lengths=[length_1, length_2],
generator=torch.manual_seed(seed)) # set the random seed for reproducible splits
return random_split_1, random_split_2
数据集分割函数已创建!
现在让我们通过创建一个20%的训练和测试数据集分割来测试一下Food101数据集。
# Create training 20% split of Food101
train_data_food101_20_percent, _ = split_dataset(dataset=train_data,
split_size=0.2)
# Create testing 20% split of Food101
test_data_food101_20_percent, _ = split_dataset(dataset=test_data,
split_size=0.2)
len(train_data_food101_20_percent), len(test_data_food101_20_percent)
[INFO] Splitting dataset of length 75750 into splits of size: 15150 (20%), 60600 (80%) [INFO] Splitting dataset of length 25250 into splits of size: 5050 (20%), 20200 (80%)
(15150, 5050)
太棒了!
import os
import torch
BATCH_SIZE = 32
NUM_WORKERS = 2 if os.cpu_count() <= 4 else 4 # this value is very experimental and will depend on the hardware you have available, Google Colab generally provides 2x CPUs
# Create Food101 20 percent training DataLoader
train_dataloader_food101_20_percent = torch.utils.data.DataLoader(train_data_food101_20_percent,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=NUM_WORKERS)
# Create Food101 20 percent testing DataLoader
test_dataloader_food101_20_percent = torch.utils.data.DataLoader(test_data_food101_20_percent,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=NUM_WORKERS)
10.5 训练 FoodVision Big 模型¶
FoodVision Big 模型和 DataLoader 准备就绪!
现在是训练的时候了。
我们将使用 torch.optim.Adam() 创建一个优化器,学习率为 1e-3。
并且由于我们有如此多的类别,我们还将使用 torch.nn.CrossEntropyLoss() 设置一个损失函数,并设置 label_smoothing=0.1,这与 torchvision 的最新训练方法一致。
什么是 标签平滑?
标签平滑是一种正则化技术(正则化是描述防止过拟合过程的另一种说法),它减少了模型对任何单一标签的重视程度,并将这种重视分散到其他标签上。
本质上,标签平滑不是让模型对单一标签过于自信,而是给其他标签赋予非零值,以帮助模型更好地泛化。
例如,如果一个没有标签平滑的模型对5个类别的输出如下:
[0, 0, 0.99, 0.01, 0]
一个带有标签平滑的模型可能会有如下输出:
[0.01, 0.01, 0.96, 0.01, 0.01]
模型仍然对其预测的类别3充满信心,但给其他标签赋予小值会迫使模型至少考虑其他选项。
最后,为了保持快速,我们将使用我们在 05. PyTorch Going Modular 第4节 中创建的 engine.train() 函数,对模型进行五个周期的训练,目标是击败原始 Food101 论文在测试集上的 56.4% 准确率结果。
让我们训练迄今为止最大的模型!
注意: 运行下面的单元格将在 Google Colab 上花费约 15-20 分钟。这是因为我们正在训练迄今为止使用的最大模型和最大数据量(15,150 张训练图像,5050 张测试图像)。这也是我们之前决定将完整 Food101 数据集的 20% 分离出来的原因(以免训练时间超过一小时)。
from going_modular.going_modular import engine
# Setup optimizer
optimizer = torch.optim.Adam(params=effnetb2_food101.parameters(),
lr=1e-3)
# Setup loss function
loss_fn = torch.nn.CrossEntropyLoss(label_smoothing=0.1) # throw in a little label smoothing because so many classes
# Want to beat original Food101 paper with 20% of data, need 56.4%+ acc on test dataset
set_seeds()
effnetb2_food101_results = engine.train(model=effnetb2_food101,
train_dataloader=train_dataloader_food101_20_percent,
test_dataloader=test_dataloader_food101_20_percent,
optimizer=optimizer,
loss_fn=loss_fn,
epochs=5,
device=device)
0%| | 0/5 [00:00<?, ?it/s]
Epoch: 1 | train_loss: 3.6317 | train_acc: 0.2869 | test_loss: 2.7670 | test_acc: 0.4937 Epoch: 2 | train_loss: 2.8615 | train_acc: 0.4388 | test_loss: 2.4653 | test_acc: 0.5387 Epoch: 3 | train_loss: 2.6585 | train_acc: 0.4844 | test_loss: 2.3547 | test_acc: 0.5649 Epoch: 4 | train_loss: 2.5494 | train_acc: 0.5116 | test_loss: 2.3038 | test_acc: 0.5755 Epoch: 5 | train_loss: 2.5006 | train_acc: 0.5239 | test_loss: 2.2805 | test_acc: 0.5810
哇呼!!!
看起来我们仅用20%的训练数据就超越了原始Food101论文中56.4%的准确率(尽管我们也只评估了20%的测试数据,为了完全复现结果,我们可以评估100%的测试数据)。
这就是迁移学习的威力!
10.6 检查 FoodVision Big 模型的损失曲线¶
让我们将 FoodVision Big 的损失曲线可视化。
我们可以使用 helper_functions.py 中的 plot_loss_curves() 函数来实现这一点。
from helper_functions import plot_loss_curves
# Check out the loss curves for FoodVision Big
plot_loss_curves(effnetb2_food101_results)

太棒了!
看来我们的正则化技术(数据增强和标签平滑)有助于防止模型过拟合(训练损失仍然高于测试损失),这表明我们的模型还有更多的学习能力,通过进一步训练可能会有所提升。
10.7 保存和加载 FoodVision Big¶
现在我们已经训练了我们迄今为止最大的模型,让我们将其保存起来,以便稍后可以重新加载它。
from going_modular.going_modular import utils
# Create a model path
effnetb2_food101_model_path = "09_pretrained_effnetb2_feature_extractor_food101_20_percent.pth"
# Save FoodVision Big model
utils.save_model(model=effnetb2_food101,
target_dir="models",
model_name=effnetb2_food101_model_path)
[INFO] Saving model to: models/09_pretrained_effnetb2_feature_extractor_food101_20_percent.pth
模型已保存!
在我们继续之前,让我们确保可以重新加载它。
我们将首先通过 create_effnetb2_model(num_classes=101) 创建一个模型实例(101 个类别对应 Food101 的所有类别)。
然后使用 torch.nn.Module.load_state_dict() 和 torch.load() 加载保存的 state_dict()。
# Create Food101 compatible EffNetB2 instance
loaded_effnetb2_food101, effnetb2_transforms = create_effnetb2_model(num_classes=101)
# Load the saved model's state_dict()
loaded_effnetb2_food101.load_state_dict(torch.load("models/09_pretrained_effnetb2_feature_extractor_food101_20_percent.pth"))
<All keys matched successfully>
10.8 检查 FoodVision Big 模型大小¶
我们的 FoodVision Big 模型能够分类 101 个类别,相较于 FoodVision Mini 的 3 个类别,增加了 33.6 倍!
这对模型大小有何影响?
让我们一探究竟。
from pathlib import Path
# Get the model size in bytes then convert to megabytes
pretrained_effnetb2_food101_model_size = Path("models", effnetb2_food101_model_path).stat().st_size // (1024*1024) # division converts bytes to megabytes (roughly)
print(f"Pretrained EffNetB2 feature extractor Food101 model size: {pretrained_effnetb2_food101_model_size} MB")
Pretrained EffNetB2 feature extractor Food101 model size: 30 MB
看起来模型的尺寸基本保持不变(FoodVision Big 为 30 MB,FoodVision Mini 为 29 MB),尽管类别数量大幅增加。
这是因为 FoodVision Big 的额外参数仅在最后一层(分类器头)中。
FoodVision Big 和 FoodVision Mini 的所有基础层都是相同的。
回到上面比较模型摘要可以提供更多细节。
| 模型 | 输出形状(类别数) | 可训练参数 | 总参数 | 模型大小(MB) |
|---|---|---|---|---|
| FoodVision Mini(EffNetB2 特征提取器) | 3 | 4,227 | 7,705,221 | 29 |
| FoodVision Big(EffNetB2 特征提取器) | 101 | 142,309 | 7,843,303 | 30 |
11. 将我们的 FoodVision Big 模型转化为可部署应用¶
我们已经在一个包含 20% 的 Food101 数据集上训练并保存了一个 EffNetB2 模型。
与其让我们的模型一直存放在文件夹中,不如将其部署起来!
我们将以与部署 FoodVision Mini 模型相同的方式,将 FoodVision Big 模型部署为 Hugging Face Spaces 上的 Gradio 演示。
首先,让我们创建一个 demos/foodvision_big/ 目录来存储我们的 FoodVision Big 演示文件,以及一个 demos/foodvision_big/examples 目录来存放用于测试演示的示例图像。
完成后,我们将拥有以下文件结构:
demos/
foodvision_big/
09_pretrained_effnetb2_feature_extractor_food101_20_percent.pth
app.py
class_names.txt
examples/
example_1.jpg
model.py
requirements.txt
其中:
09_pretrained_effnetb2_feature_extractor_food101_20_percent.pth是我们训练好的 PyTorch 模型文件。app.py包含我们的 FoodVision Big Gradio 应用。class_names.txt包含 FoodVision Big 的所有类别名称。examples/包含用于 Gradio 应用的示例图像。model.py包含模型定义以及与模型相关的任何转换。requirements.txt包含运行我们应用所需的依赖项,如torch、torchvision和gradio。
from pathlib import Path
# Create FoodVision Big demo path
foodvision_big_demo_path = Path("demos/foodvision_big/")
# Make FoodVision Big demo directory
foodvision_big_demo_path.mkdir(parents=True, exist_ok=True)
# Make FoodVision Big demo examples directory
(foodvision_big_demo_path / "examples").mkdir(parents=True, exist_ok=True)
11.1 下载示例图片并将其移动到 examples 目录¶
我们将使用可靠的 pizza-dad 图片(一张我爸爸吃披萨的照片)作为示例图片。
{kind=link}
让我们通过 !wget 命令从课程的 GitHub 上下载这张图片,然后使用 !mv 命令("move" 的简写)将其移动到 demos/foodvision_big/examples 目录中。
同时,我们还将从 models/09_pretrained_effnetb2_feature_extractor_food101_20_percent.pth 移动我们训练好的 Food101 EffNetB2 模型到 demos/foodvision_big 目录。
# Download and move an example image
!wget https://raw.githubusercontent.com/mrdbourke/pytorch-deep-learning/main/images/04-pizza-dad.jpeg
!mv 04-pizza-dad.jpeg demos/foodvision_big/examples/04-pizza-dad.jpg
# Move trained model to FoodVision Big demo folder (will error if model is already moved)
!mv models/09_pretrained_effnetb2_feature_extractor_food101_20_percent.pth demos/foodvision_big
--2022-08-25 14:24:41-- https://raw.githubusercontent.com/mrdbourke/pytorch-deep-learning/main/images/04-pizza-dad.jpeg Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.111.133, 185.199.110.133, 185.199.109.133, ... Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.111.133|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 2874848 (2.7M) [image/jpeg] Saving to: '04-pizza-dad.jpeg’ 04-pizza-dad.jpeg 100%[===================>] 2.74M 7.85MB/s in 0.3s 2022-08-25 14:24:43 (7.85 MB/s) - '04-pizza-dad.jpeg’ saved [2874848/2874848]
11.2 将Food101类别名称保存到文件(class_names.txt)¶
由于Food101数据集包含众多类别,我们不将其类别名称以列表形式存储在app.py文件中,而是将其保存到.txt文件中,并在需要时读取。
首先,我们通过查看food101_class_names来提醒自己它们的样子。
# Check out the first 10 Food101 class names
food101_class_names[:10]
['apple_pie', 'baby_back_ribs', 'baklava', 'beef_carpaccio', 'beef_tartare', 'beet_salad', 'beignets', 'bibimbap', 'bread_pudding', 'breakfast_burrito']
太好了,现在我们可以通过以下步骤将这些内容写入一个文本文件:首先创建一个指向 demos/foodvision_big/class_names.txt 的路径,然后使用 Python 的 open() 函数打开文件,并逐行写入每个类别名称,每行一个类别。
理想情况下,我们希望类别名称保存成如下格式:
apple_pie
baby_back_ribs
baklava
beef_carpaccio
beef_tartare
...
# Create path to Food101 class names
foodvision_big_class_names_path = foodvision_big_demo_path / "class_names.txt"
# Write Food101 class names list to file
with open(foodvision_big_class_names_path, "w") as f:
print(f"[INFO] Saving Food101 class names to {foodvision_big_class_names_path}")
f.write("\n".join(food101_class_names)) # leave a new line between each class
[INFO] Saving Food101 class names to demos/foodvision_big/class_names.txt
非常好,现在我们来确保能够读取它们。
为此,我们将使用 Python 的 open() 函数以读取模式("r")打开文件,然后使用 readlines() 方法读取 class_names.txt 文件中的每一行。
我们可以通过列表推导式和 strip() 方法去除每个类名中的换行符,从而将类名保存到一个列表中。
# Open Food101 class names file and read each line into a list
with open(foodvision_big_class_names_path, "r") as f:
food101_class_names_loaded = [food.strip() for food in f.readlines()]
# View the first 5 class names loaded back in
food101_class_names_loaded[:5]
['apple_pie', 'baby_back_ribs', 'baklava', 'beef_carpaccio', 'beef_tartare']
11.3 将我们的 FoodVision Big 模型转换为 Python 脚本 (model.py)¶
就像 FoodVision Mini 演示一样,让我们创建一个脚本,该脚本能够实例化一个 EffNetB2 特征提取器模型及其所需的转换。
%%writefile demos/foodvision_big/model.py
import torch
import torchvision
from torch import nn
def create_effnetb2_model(num_classes:int=3,
seed:int=42):
"""Creates an EfficientNetB2 feature extractor model and transforms.
Args:
num_classes (int, optional): number of classes in the classifier head.
Defaults to 3.
seed (int, optional): random seed value. Defaults to 42.
Returns:
model (torch.nn.Module): EffNetB2 feature extractor model.
transforms (torchvision.transforms): EffNetB2 image transforms.
"""
# Create EffNetB2 pretrained weights, transforms and model
weights = torchvision.models.EfficientNet_B2_Weights.DEFAULT
transforms = weights.transforms()
model = torchvision.models.efficientnet_b2(weights=weights)
# Freeze all layers in base model
for param in model.parameters():
param.requires_grad = False
# Change classifier head with random seed for reproducibility
torch.manual_seed(seed)
model.classifier = nn.Sequential(
nn.Dropout(p=0.3, inplace=True),
nn.Linear(in_features=1408, out_features=num_classes),
)
return model, transforms
Overwriting demos/foodvision_big/model.py
11.4 将我们的 FoodVision Big Gradio 应用转换为 Python 脚本 (app.py)¶
我们已经有了一个 FoodVision Big 的 model.py 脚本,现在让我们创建一个 FoodVision Big 的 app.py 脚本。
这基本上与 FoodVision Mini 的 app.py 脚本相同,除了以下几点需要更改:
- 导入和类名设置 -
class_names变量将是一个包含所有 Food101 类别的列表,而不是披萨、牛排、寿司。我们可以通过demos/foodvision_big/class_names.txt访问这些类别。 - 模型和转换准备 -
model将具有num_classes=101而不是num_classes=3。我们还将确保从"09_pretrained_effnetb2_feature_extractor_food101_20_percent.pth"(我们的 FoodVision Big 模型路径)加载权重。 - 预测函数 - 这将保持与 FoodVision Mini 的
app.py相同。 - Gradio 应用 - Gradio 界面将具有不同的
title、description和article参数,以反映 FoodVision Big 的详细信息。
我们还将确保使用 %%writefile 魔法命令将其保存到 demos/foodvision_big/app.py。
%%writefile demos/foodvision_big/app.py
### 1. Imports and class names setup ###
import gradio as gr
import os
import torch
from model import create_effnetb2_model
from timeit import default_timer as timer
from typing import Tuple, Dict
# Setup class names
with open("class_names.txt", "r") as f: # reading them in from class_names.txt
class_names = [food_name.strip() for food_name in f.readlines()]
### 2. Model and transforms preparation ###
# Create model
effnetb2, effnetb2_transforms = create_effnetb2_model(
num_classes=101, # could also use len(class_names)
)
# Load saved weights
effnetb2.load_state_dict(
torch.load(
f="09_pretrained_effnetb2_feature_extractor_food101_20_percent.pth",
map_location=torch.device("cpu"), # load to CPU
)
)
### 3. Predict function ###
# Create predict function
def predict(img) -> Tuple[Dict, float]:
"""Transforms and performs a prediction on img and returns prediction and time taken.
"""
# Start the timer
start_time = timer()
# Transform the target image and add a batch dimension
img = effnetb2_transforms(img).unsqueeze(0)
# Put model into evaluation mode and turn on inference mode
effnetb2.eval()
with torch.inference_mode():
# Pass the transformed image through the model and turn the prediction logits into prediction probabilities
pred_probs = torch.softmax(effnetb2(img), dim=1)
# Create a prediction label and prediction probability dictionary for each prediction class (this is the required format for Gradio's output parameter)
pred_labels_and_probs = {class_names[i]: float(pred_probs[0][i]) for i in range(len(class_names))}
# Calculate the prediction time
pred_time = round(timer() - start_time, 5)
# Return the prediction dictionary and prediction time
return pred_labels_and_probs, pred_time
### 4. Gradio app ###
# Create title, description and article strings
title = "FoodVision Big 🍔👁"
description = "An EfficientNetB2 feature extractor computer vision model to classify images of food into [101 different classes](https://github.com/mrdbourke/pytorch-deep-learning/blob/main/extras/food101_class_names.txt)."
article = "Created at [09. PyTorch Model Deployment](https://www.learnpytorch.io/09_pytorch_model_deployment/)."
# Create examples list from "examples/" directory
example_list = [["examples/" + example] for example in os.listdir("examples")]
# Create Gradio interface
demo = gr.Interface(
fn=predict,
inputs=gr.Image(type="pil"),
outputs=[
gr.Label(num_top_classes=5, label="Predictions"),
gr.Number(label="Prediction time (s)"),
],
examples=example_list,
title=title,
description=description,
article=article,
)
# Launch the app!
demo.launch()
Overwriting demos/foodvision_big/app.py
11.5 为 FoodVision Big 创建需求文件(requirements.txt)¶
现在我们只需要一个 requirements.txt 文件,用来告诉我们的 Hugging Face Space 平台 FoodVision Big 应用所需的依赖项。
%%writefile demos/foodvision_big/requirements.txt
torch==1.12.0
torchvision==0.13.0
gradio==3.1.4
Overwriting demos/foodvision_big/requirements.txt
11.6 下载我们的 FoodVision Big 应用文件¶
我们已经拥有了在 Hugging Face 上部署 FoodVision Big 应用所需的所有文件,现在让我们将它们压缩并下载下来。
我们将使用与上述 第9.1节:下载我们的 FoodVision Mini 应用文件 中为 FoodVision Mini 应用所用的相同流程。
# Zip foodvision_big folder but exclude certain files
!cd demos/foodvision_big && zip -r ../foodvision_big.zip * -x "*.pyc" "*.ipynb" "*__pycache__*" "*ipynb_checkpoints*"
# Download the zipped FoodVision Big app (if running in Google Colab)
try:
from google.colab import files
files.download("demos/foodvision_big.zip")
except:
print("Not running in Google Colab, can't use google.colab.files.download()")
updating: 09_pretrained_effnetb2_feature_extractor_food101_20_percent.pth (deflated 8%) updating: app.py (deflated 54%) updating: class_names.txt (deflated 48%) updating: examples/ (stored 0%) updating: flagged/ (stored 0%) updating: model.py (deflated 56%) updating: requirements.txt (deflated 4%) updating: examples/04-pizza-dad.jpg (deflated 0%) Not running in Google Colab, can't use google.colab.files.download()
11.7 将我们的 FoodVision Big 应用部署到 HuggingFace Spaces¶
棒极了!
是时候将我们整个课程中最大的模型变为现实了!
让我们将 FoodVision Big 的 Gradio 演示部署到 Hugging Face Spaces,以便我们可以交互式地测试它,并让其他人体验我们机器学习努力的魔力!
注意: 有多种方式上传文件到 Hugging Face Spaces。以下步骤将 Hugging Face 视为一个 git 仓库来跟踪文件。然而,你也可以通过网页界面或
huggingface_hub库直接上传到 Hugging Face Spaces。
好消息是,我们已经通过 FoodVision Mini 完成了这些步骤,现在我们只需要将其定制以适应 FoodVision Big:
- 注册一个 Hugging Face 账户。
- 通过访问你的个人资料并点击“New Space”来创建一个新的 Hugging Face Space。
- 注意: Hugging Face 中的 Space 也被称为“代码仓库”(存储代码/文件的地方),简称“repo”。
- 给 Space 命名,例如,我的是
mrdbourke/foodvision_big,你可以在这里看到它:https://huggingface.co/spaces/mrdbourke/foodvision_big - 选择一个许可证(我使用了 MIT)。
- 选择 Gradio 作为 Space SDK(软件开发工具包)。
- 注意: 你可以使用其他选项,如 Streamlit,但由于我们的应用是使用 Gradio 构建的,我们将坚持使用 Gradio。
- 选择你的 Space 是公开的还是私有的(我选择了公开,因为我希望我的 Space 对其他人可用)。
- 点击“Create Space”。
- 通过在终端或命令提示符中运行
git clone https://huggingface.co/spaces/[YOUR_USERNAME]/[YOUR_SPACE_NAME]来本地克隆仓库。- 注意: 你也可以通过在“Files and versions”标签下上传文件来添加文件。
- 将下载的
foodvision_big文件夹的内容复制/移动到克隆的仓库文件夹中。 - 要上传和跟踪较大的文件(例如,超过 10MB 的文件,或者在我们的例子中,我们的 PyTorch 模型文件),你需要安装 Git LFS(即“git large file storage”)。
- 安装 Git LFS 后,你可以通过运行
git lfs install来激活它。 - 在
foodvision_big目录中,使用 Git LFS 跟踪超过 10MB 的文件,使用git lfs track "*.file_extension"。- 跟踪 EffNetB2 PyTorch 模型文件,使用
git lfs track "09_pretrained_effnetb2_feature_extractor_food101_20_percent.pth"。 - 注意: 如果你在上传图像时遇到任何错误,你可能也需要使用
git lfs跟踪它们,例如git lfs track "examples/04-pizza-dad.jpg"。
- 跟踪 EffNetB2 PyTorch 模型文件,使用
- 跟踪
.gitattributes(从 HuggingFace 克隆时自动创建,这个文件将帮助确保我们的大文件通过 Git LFS 被跟踪)。你可以在 FoodVision Big Hugging Face Space 上看到一个示例.gitattributes文件。git add .gitattributes
- 添加其余的
foodvision_big应用文件并通过以下命令提交它们:git add *git commit -m "first commit"
- 推送(上传)文件到 Hugging Face:
git push
- 等待 3-5 分钟让构建完成(未来的构建会更快),你的应用就会上线!
如果一切正常,我们的 FoodVision Big Gradio 演示应该准备好了进行分类!
你可以在这里看到我的版本:https://huggingface.co/spaces/mrdbourke/foodvision_big/
或者我们甚至可以将我们的 FoodVision Big Gradio 演示直接嵌入到我们的笔记本中作为一个 iframe,使用 IPython.display.IFrame 和一个链接,格式为 https://hf.space/embed/[YOUR_USERNAME]/[YOUR_SPACE_NAME]/+。
# IPython is a library to help work with Python iteractively
from IPython.display import IFrame
# Embed FoodVision Big Gradio demo as an iFrame
IFrame(src="https://hf.space/embed/mrdbourke/foodvision_big/+", width=900, height=750)
真是太酷了!?
从构建预测直线的PyTorch模型到现在,我们已经走过了漫长的道路...现在我们正在构建面向全球人民的计算机视觉模型!
主要收获¶
- 部署与训练同样重要。 一旦你拥有了一个表现良好的模型,你的首要问题应该是:我如何部署这个模型并使其对他人可用?部署让你能够在现实世界中测试模型,而不仅仅是在私有训练和测试集上。
- 机器学习模型部署的三个问题:
- 模型最理想的使用场景是什么(它的表现如何,速度如何)?
- 模型将部署在哪里(是在设备上还是在云端)?
- 模型的功能如何实现(预测是在线还是离线)?
- 部署选项众多。 但最好从简单开始。目前最好的方法之一(我说目前是因为这些事情总是在变化)是使用 Gradio 创建一个演示并将其托管在 Hugging Face Spaces 上。从简单开始,并在需要时进行扩展。
- 永不停止实验。 你的机器学习模型需求可能会随时间变化,因此部署单个模型并不是最后一步。你可能会发现数据集发生变化,因此需要更新模型。或者新的研究发布,有更好的架构可以使用。
- 因此,部署一个模型是一个很好的步骤,但你可能会希望随着时间的推移对其进行更新。
- 机器学习模型部署是 MLOps(机器学习运维)工程实践的一部分。 MLOps 是 DevOps(开发运维)的扩展,涉及围绕模型训练的所有工程部分:数据收集和存储、数据预处理、模型部署、模型监控、版本控制等。这是一个快速发展的领域,但有一些可靠的资源可以学习更多,其中许多资源在 PyTorch 额外资源中。
练习¶
所有练习都专注于实践上述代码。
你应该能够通过参考每个部分或遵循链接的资源来完成它们。
资源:
- 09 练习模板笔记本。
- 09 练习示例解决方案笔记本 在查看这个之前尝试练习。
- 在 YouTube 上观看解决方案的视频演示(包括所有错误)。
- 使用 GPU (
device="cuda") 对测试数据集上的两个特征提取器模型进行预测并计时。比较模型在 GPU 和 CPU 上的预测时间 - 这会缩小它们之间的差距吗?也就是说,在 GPU 上进行预测是否使 ViT 特征提取器的预测时间更接近 EffNetB2 特征提取器的预测时间?- 你可以在第 5 节:使用我们训练好的模型进行预测并计时和第 6 节:比较模型结果、预测时间和大小中找到执行这些步骤的代码。
- ViT 特征提取器似乎比 EffNetB2 具有更多的学习能力(由于参数更多),它在整个 Food101 数据集的 20% 分割上表现如何?
- 在 20% 的 Food101 数据集上训练一个 ViT 特征提取器,就像我们在第 10 节:创建 FoodVision Big 中对 EffNetB2 所做的那样,进行 5 个 epoch。
- 使用练习 2 中的 ViT 特征提取器对 20% 的 Food101 测试数据集进行预测,并找出“最错误”的预测。
- 这些预测将是具有最高预测概率但具有错误预测标签的预测。
- 写一两句关于为什么你认为模型会做出这些错误预测的原因。
- 在整个 Food101 测试数据集上评估 ViT 特征提取器,而不是仅仅在 20% 的版本上,它的表现如何?
- 它是否击败了原始 Food101 论文的最佳结果 56.4% 的准确率?
- 前往 Paperswithcode.com 并找到 Food101 数据集上当前表现最好的模型。
- 它使用了什么模型架构?
- 写下我们部署的 FoodVision 模型可能存在的 1-3 个潜在失败点以及一些可能的解决方案。
- 例如,如果有人上传了一张不是食物的照片到我们的 FoodVision Mini 模型中会发生什么?
- 从
torchvision.datasets中选择任意数据集,并使用torchvision.models中的模型(你可以使用我们已经创建的模型,例如 EffNetB2 或 ViT)对其进行 5 个 epoch 的特征提取器训练,然后将你的模型作为 Gradio 应用部署到 Hugging Face Spaces。- 你可能希望选择较小的数据集或对其进行较小的分割,以便训练不会花费太长时间。
- 我很想看到你部署的模型!所以请务必在 Discord 或课程 GitHub 讨论页面上分享它们。
课外学习¶
- 机器学习模型的部署通常是一个工程挑战,而不是纯粹的机器学习挑战,了解更多资源请参见 PyTorch 额外资源机器学习工程部分。
- 其中你会找到 Chip Huyen 的书 Designing Machine Learning Systems(特别是关于模型部署的第7章)和 Goku Mohandas 的 Made with ML MLOps 课程 等推荐资源。
- 随着你开始构建越来越多的项目,你可能会频繁使用 Git(以及可能的 GitHub)。了解更多关于这两者的信息,我推荐观看 freeCodeCamp YouTube 频道的 Git 和 GitHub 初学者速成课程 视频。
- 我们仅触及了 Gradio 可能性的表面。更多信息,我建议查看 完整文档,特别是:
- 所有不同类型的 输入和输出组件。
- 用于更高级工作流的 Gradio Blocks API。
- Hugging Face 课程章节关于 如何使用 Gradio 与 Hugging Face。
- 边缘设备不仅限于手机,还包括像树莓派这样的小型计算机,PyTorch 团队有一篇 精彩的博客文章教程 关于将 PyTorch 模型部署到其中一个设备上。
- 关于开发 AI 和 ML 驱动的应用程序的绝佳指南,请参见 Google 的 People + AI Guidebook。我最喜欢的部分是关于 设定正确的期望。
- 我在 2021年4月版 Machine Learning Monthly(我每月发送的包含 ML 领域最新动态的通讯)中涵盖了更多这类资源,包括来自 Apple、Microsoft 等的指南。
- 如果你想加快模型在 CPU 上的运行时间,你应该了解 TorchScript、ONNX(开放神经网络交换)和 OpenVINO。从纯 PyTorch 转换到 ONNX/OpenVINO 模型,我看到了性能提升约2倍以上。
- 关于将模型转化为可部署和可扩展的 API,请参见 TorchServe 库。
- 关于为什么在浏览器中部署机器学习模型(一种边缘部署形式)提供多种优势(无需网络传输延迟)的精彩示例和理由,请参见 Jo Kristian Bergum 的文章 Moving ML Inference from the Cloud to the Edge。