View Source Code | View Slides
05. PyTorch 模块化
本节回答了这样一个问题:“如何将我的笔记本代码转换为 Python 脚本?”
为此,我们将把 notebook 04. PyTorch 自定义数据集 中最有用的代码单元转换为一系列 Python
脚本,保存到名为 going_modular 的目录中。
什么是模块化?
模块化涉及将笔记本代码(来自 Jupyter Notebook 或 Google Colab 笔记本)转换为一系列提供类似功能的 Python 脚本。
例如,我们可以将笔记本代码从一系列单元转换为以下 Python 文件:
data_setup.py- 用于准备和下载数据(如果需要)的文件。engine.py- 包含各种训练函数的文件。model_builder.py或model.py- 用于创建 PyTorch 模型的文件。train.py- 利用所有其他文件并训练目标 PyTorch 模型的文件。utils.py- 专门用于有用工具函数的文件。
注意: 上述文件的命名和布局将取决于您的使用场景和代码需求。Python 脚本与单个笔记本单元一样通用,这意味着,您几乎可以为任何类型的功能创建一个脚本。
为什么要模块化?
笔记本非常适合迭代地探索和快速运行实验。
然而,对于更大规模的项目,您可能会发现 Python 脚本更具可重复性且更易于运行。
尽管这是一个有争议的话题,但像 Netflix 这样的公司已经展示了他们如何使用笔记本进行生产代码。
生产代码 是运行以向某人或某物提供服务的代码。
例如,如果您有一个在线运行的应用程序,其他人可以访问和使用,那么运行该应用程序的代码就被视为 生产代码。
并且像 fast.ai 的 nb-dev(笔记本开发的简称)这样的库,使您能够使用 Jupyter Notebooks 编写整个 Python 库(包括文档)。
笔记本与Python脚本的优缺点
双方都有各自的理由。
但这个列表总结了几个主要议题。
| 优点 | 缺点 | |
|---|---|---|
| 笔记本 | 易于实验/入门 | 版本控制可能很困难 |
| 易于分享(例如,分享一个Google Colab笔记本的链接) | 难以仅使用特定部分 | |
| 非常直观 | 文本和图形可能会妨碍代码 |
| 优点 | 缺点 | |
|---|---|---|
| Python脚本 | 可以将代码打包在一起(避免在不同笔记本中重复编写相似代码) | 实验不够直观(通常需要运行整个脚本而不是单个单元) |
| 可以使用git进行版本控制 | ||
| 许多开源项目使用脚本 | ||
| 大型项目可以在云服务商上运行(对笔记本的支持不如脚本) |
我的工作流程
我通常在Jupyter/Google Colab笔记本中开始机器学习项目,以便快速实验和可视化。
然后,当我有了一些成果后,我会将最有用的代码片段移到Python脚本中。
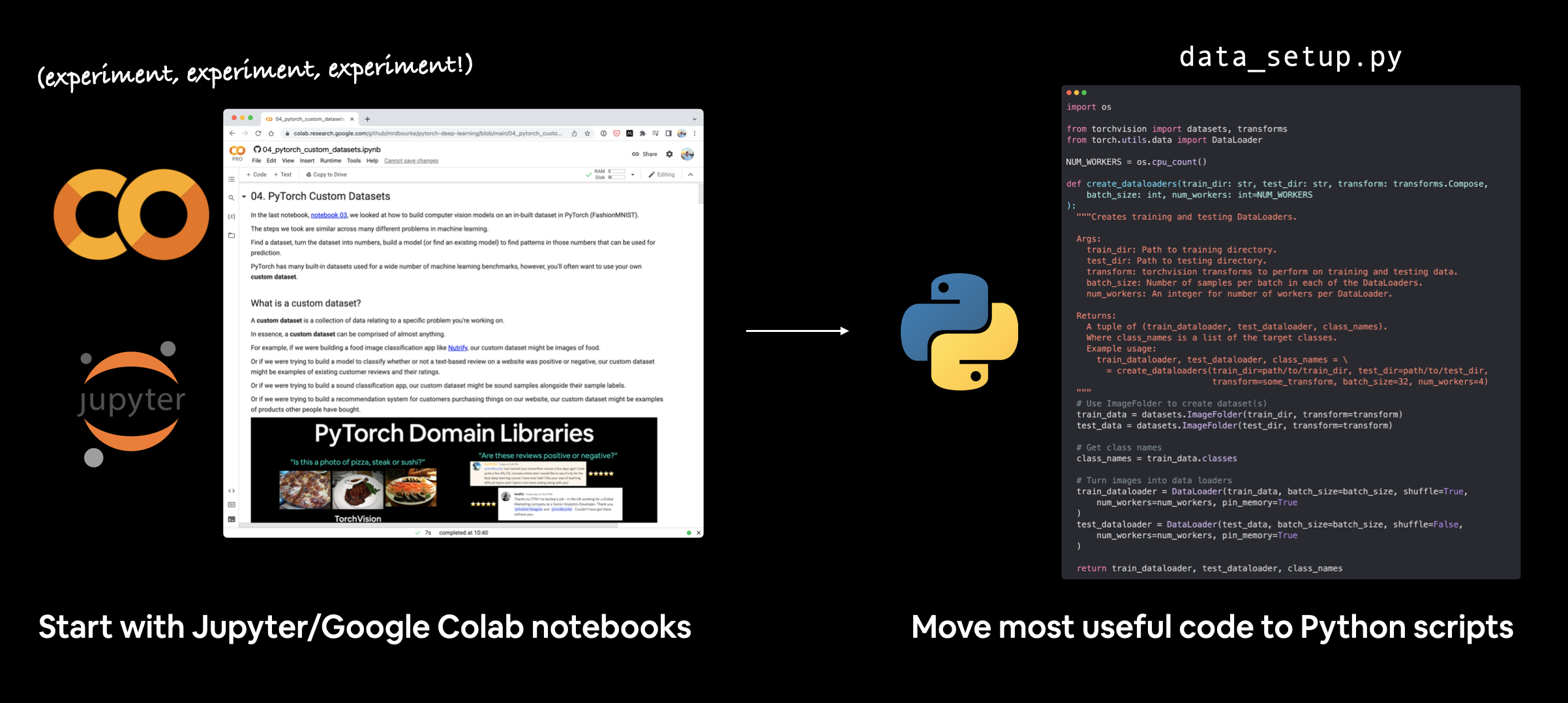
编写机器学习代码有许多可能的工作流程。有些人喜欢从脚本开始,而另一些人(像我一样)更喜欢从笔记本开始,稍后再转到脚本。
实际应用中的PyTorch
在你探索的过程中,你会发现许多基于PyTorch的机器学习项目的代码库都有如何以Python脚本形式运行PyTorch代码的说明。
例如,你可能会被指示在终端/命令行中运行如下代码来训练模型:
python train.py --model MODEL_NAME --batch_size BATCH_SIZE --lr LEARNING_RATE --num_epochs NUM_EPOCHS

在命令行中运行带有各种超参数设置的PyTorch train.py脚本。
在这种情况下,train.py是目标Python脚本,它可能包含训练PyTorch模型的函数。
而--model、--batch_size、--lr和--num_epochs被称为参数标志。
你可以将这些参数设置为任何你喜欢的值,如果它们与train.py兼容,它们就会工作,否则就会报错。
例如,假设我们想用批量大小为32、学习率为0.001的参数训练笔记本04中的TinyVGG模型10个周期:
python train.py --model tinyvgg --batch_size 32 --lr 0.001 --num_epochs 10
你可以在你的train.py脚本中设置任意数量的这些参数标志,以满足你的需求。
PyTorch博客文章中训练最先进的计算机视觉模型也使用了这种风格。

使用8个GPU训练最先进的计算机视觉模型的PyTorch命令行训练脚本配方。 来源:PyTorch博客。
我们将涵盖的内容
本节的主要概念是:将实用的笔记本代码单元转换为可重复使用的Python文件。
这样做可以避免我们一遍又一遍地编写相同的代码。
本节有两个笔记本:
- 05. 模块化:第1部分(单元模式) - 这个笔记本以传统的Jupyter Notebook/Google Colab笔记本运行,是笔记本04的浓缩版本。
- 05. 模块化:第2部分(脚本模式) - 这个笔记本与第1个相同,但增加了将每个主要部分转换为Python脚本的功能,例如
data_setup.py和train.py。
本文档中的文本重点介绍代码单元05. 模块化:第2部分(脚本模式),即顶部带有%%writefile ...的单元。
为什么分两部分?
因为有时学习某件事的最佳方式是看它与别的事有何不同。
如果你并排运行每个笔记本,你会看到它们的不同之处,这就是关键的学习点。
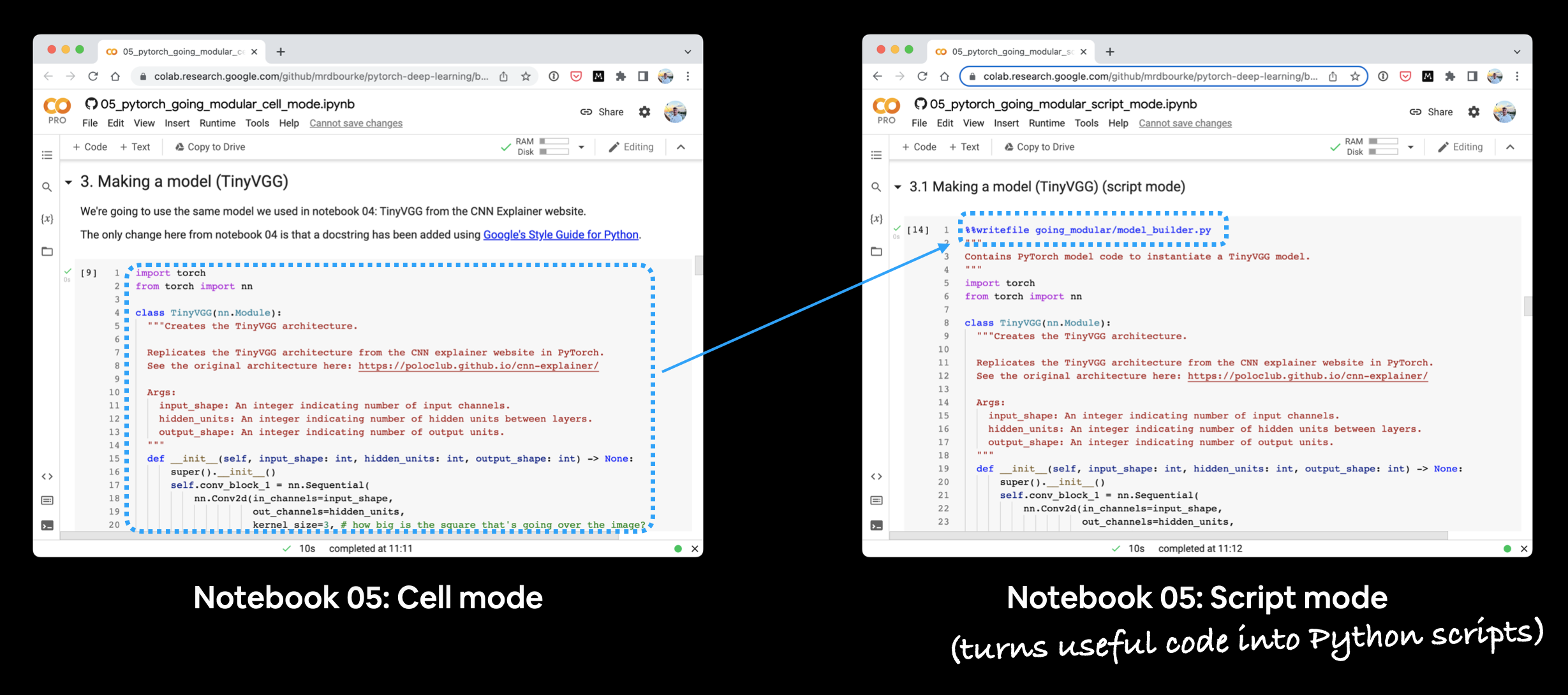
并排运行第05节的两本笔记本。你会注意到脚本模式笔记本有额外的代码单元,将单元模式笔记本的代码转换为Python脚本。
我们的目标
通过本节的学习,我们希望达到以下两点:
- 能够通过命令行中的一行代码训练我们在笔记本04(Food Vision Mini)中构建的模型:
python train.py。 - 一个可重复使用的Python脚本目录结构,例如:
going_modular/
├── going_modular/
│ ├── data_setup.py
│ ├── engine.py
│ ├── model_builder.py
│ ├── train.py
│ └── utils.py
├── models/
│ ├── 05_going_modular_cell_mode_tinyvgg_model.pth
│ └── 05_going_modular_script_mode_tinyvgg_model.pth
└── data/
└── pizza_steak_sushi/
├── train/
│ ├── pizza/
│ │ ├── image01.jpeg
│ │ └── ...
│ ├── steak/
│ └── sushi/
└── test/
├── pizza/
├── steak/
└── sushi/
注意事项
- 文档字符串 - 编写可复现且易于理解的代码至关重要。鉴于此,我们在编写脚本中的每个函数/类时都遵循了 Google 的 Python 文档字符串风格。
- 脚本顶部导入模块 - 由于我们将要创建的所有 Python 脚本都可以被视为独立的程序,因此所有脚本都需要在其开头导入所需的模块,例如:
# Import modules required for train.py
import os
import torch
import data_setup, engine, model_builder, utils
from torchvision import transforms
在哪里可以获得帮助?
本课程的所有材料都可以在 GitHub 上找到。
如果你遇到问题,可以在课程的 GitHub Discussions 页面上提问。
当然,还有 PyTorch 文档和 PyTorch 开发者论坛,这是一个非常有用的 PyTorch 相关资源。
0. 单元模式 vs. 脚本模式
单元模式笔记本,例如 05. 模块化第1部分(单元模式),是一个正常运行的笔记本,每个单元格要么是代码,要么是 Markdown。
脚本模式笔记本,例如 05. 模块化第2部分(脚本模式),与单元模式笔记本非常相似,但许多代码单元格可能被转换为 Python 脚本。
注意: 你不需要通过笔记本创建 Python 脚本,你可以直接通过 VS Code 等集成开发环境(IDE)创建它们。将脚本模式笔记本作为本节的一部分只是为了演示从笔记本到 Python 脚本的一种方式。
1. 获取数据
在每个 05 笔记本中获取数据的方式与 笔记本 04 相同。
通过 Python 的 requests 模块向 GitHub 发出请求,下载一个 .zip 文件并解压。
import os
import requests
import zipfile
from pathlib import Path
# Setup path to data folder
data_path = Path("data/")
image_path = data_path / "pizza_steak_sushi"
# If the image folder doesn't exist, download it and prepare it...
if image_path.is_dir():
print(f"{image_path} directory exists.")
else:
print(f"Did not find {image_path} directory, creating one...")
image_path.mkdir(parents=True, exist_ok=True)
# Download pizza, steak, sushi data
with open(data_path / "pizza_steak_sushi.zip", "wb") as f:
request = requests.get("https://github.com/mrdbourke/pytorch-deep-learning/raw/main/data/pizza_steak_sushi.zip")
print("Downloading pizza, steak, sushi data...")
f.write(request.content)
# Unzip pizza, steak, sushi data
with zipfile.ZipFile(data_path / "pizza_steak_sushi.zip", "r") as zip_ref:
print("Unzipping pizza, steak, sushi data...")
zip_ref.extractall(image_path)
# Remove zip file
os.remove(data_path / "pizza_steak_sushi.zip")
这样就会得到一个名为 data 的文件夹,其中包含一个名为 pizza_steak_sushi 的目录,里面有披萨、牛排和寿司的图片,格式为标准的图像分类格式。
data/
└── pizza_steak_sushi/
├── train/
│ ├── pizza/
│ │ ├── train_image01.jpeg
│ │ ├── test_image02.jpeg
│ │ └── ...
│ ├── steak/
│ │ └── ...
│ └── sushi/
│ └── ...
└── test/
├── pizza/
│ ├── test_image01.jpeg
│ └── test_image02.jpeg
├── steak/
└── sushi/
2. 创建数据集和数据加载器 (data_setup.py)
当我们获取数据后,可以将其转换为 PyTorch 的 Dataset 和 DataLoader(一个用于训练数据,一个用于测试数据)。
我们将有用的 Dataset 和 DataLoader 创建代码封装成一个名为 create_dataloaders() 的函数。
并通过 %%writefile going_modular/data_setup.py 将其写入文件。
%%writefile going_modular/data_setup.py
"""
Contains functionality for creating PyTorch DataLoaders for
image classification data.
"""
import os
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
NUM_WORKERS = os.cpu_count()
def create_dataloaders(
train_dir: str,
test_dir: str,
transform: transforms.Compose,
batch_size: int,
num_workers: int=NUM_WORKERS
):
"""Creates training and testing DataLoaders.
Takes in a training directory and testing directory path and turns
them into PyTorch Datasets and then into PyTorch DataLoaders.
Args:
train_dir: Path to training directory.
test_dir: Path to testing directory.
transform: torchvision transforms to perform on training and testing data.
batch_size: Number of samples per batch in each of the DataLoaders.
num_workers: An integer for number of workers per DataLoader.
Returns:
A tuple of (train_dataloader, test_dataloader, class_names).
Where class_names is a list of the target classes.
Example usage:
train_dataloader, test_dataloader, class_names = \
= create_dataloaders(train_dir=path/to/train_dir,
test_dir=path/to/test_dir,
transform=some_transform,
batch_size=32,
num_workers=4)
"""
# Use ImageFolder to create dataset(s)
train_data = datasets.ImageFolder(train_dir, transform=transform)
test_data = datasets.ImageFolder(test_dir, transform=transform)
# Get class names
class_names = train_data.classes
# Turn images into data loaders
train_dataloader = DataLoader(
train_data,
batch_size=batch_size,
shuffle=True,
num_workers=num_workers,
pin_memory=True,
)
test_dataloader = DataLoader(
test_data,
batch_size=batch_size,
shuffle=False, # don't need to shuffle test data
num_workers=num_workers,
pin_memory=True,
)
return train_dataloader, test_dataloader, class_names
如果我们想要创建DataLoader,现在可以像这样使用data_setup.py中的函数:
# Import data_setup.py
from going_modular import data_setup
# Create train/test dataloader and get class names as a list
train_dataloader, test_dataloader, class_names = data_setup.create_dataloaders(...)
3. 构建模型 (model_builder.py)
在过去的几个笔记本(笔记本03和笔记本04)中,我们已经多次构建了TinyVGG模型。
因此,将模型放入其文件中以便我们可以反复重用是很有意义的。
让我们将TinyVGG()模型类放入一个脚本中,使用行%%writefile going_modular/model_builder.py:
%%writefile going_modular/model_builder.py
"""
Contains PyTorch model code to instantiate a TinyVGG model.
"""
import torch
from torch import nn
class TinyVGG(nn.Module):
"""Creates the TinyVGG architecture.
Replicates the TinyVGG architecture from the CNN explainer website in PyTorch.
See the original architecture here: https://poloclub.github.io/cnn-explainer/
Args:
input_shape: An integer indicating number of input channels.
hidden_units: An integer indicating number of hidden units between layers.
output_shape: An integer indicating number of output units.
"""
def __init__(self, input_shape: int, hidden_units: int, output_shape: int) -> None:
super().__init__()
self.conv_block_1 = nn.Sequential(
nn.Conv2d(in_channels=input_shape,
out_channels=hidden_units,
kernel_size=3,
stride=1,
padding=0),
nn.ReLU(),
nn.Conv2d(in_channels=hidden_units,
out_channels=hidden_units,
kernel_size=3,
stride=1,
padding=0),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,
stride=2)
)
self.conv_block_2 = nn.Sequential(
nn.Conv2d(hidden_units, hidden_units, kernel_size=3, padding=0),
nn.ReLU(),
nn.Conv2d(hidden_units, hidden_units, kernel_size=3, padding=0),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.classifier = nn.Sequential(
nn.Flatten(),
# Where did this in_features shape come from?
# It's because each layer of our network compresses and changes the shape of our inputs data.
nn.Linear(in_features=hidden_units*13*13,
out_features=output_shape)
)
def forward(self, x: torch.Tensor):
x = self.conv_block_1(x)
x = self.conv_block_2(x)
x = self.classifier(x)
return x
# return self.classifier(self.conv_block_2(self.conv_block_1(x))) # <- leverage the benefits of operator fusion
现在,我们可以使用以下方法导入 TinyVGG 模型,而不是每次都从头开始编写 TinyVGG 模型:
import torch
# Import model_builder.py
from going_modular import model_builder
device = "cuda" if torch.cuda.is_available() else "cpu"
# Instantiate an instance of the model from the "model_builder.py" script
torch.manual_seed(42)
model = model_builder.TinyVGG(input_shape=3,
hidden_units=10,
output_shape=len(class_names)).to(device)
4. 创建 train_step() 和 test_step() 函数,并用 train() 组合它们
我们在 notebook 04 中编写了几个训练函数:
train_step()- 接受一个模型、一个DataLoader、一个损失函数和一个优化器,并在DataLoader上训练模型。test_step()- 接受一个模型、一个DataLoader和一个损失函数,并在DataLoader上评估模型。train()- 针对给定的 epoch 数,执行 1 和 2,并返回一个结果字典。
由于这些将是我们的模型训练的 引擎,我们可以将它们全部放入一个名为 engine.py 的 Python 脚本中,使用 %%writefile going_modular/engine.py 命令:
%%writefile going_modular/engine.py
"""
包含用于训练和测试 PyTorch 模型的函数。
"""
import torch
from tqdm.auto import tqdm
from typing import Dict, List, Tuple
def train_step(model: torch.nn.Module,
dataloader: torch.utils.data.DataLoader,
loss_fn: torch.nn.Module,
optimizer: torch.optim.Optimizer,
device: torch.device) -> Tuple[float, float]:
"""训练一个 PyTorch 模型的一个 epoch。
将目标 PyTorch 模型设置为训练模式,然后
执行所有必需的训练步骤(前向传播、损失计算、优化器步骤)。
Args:
model: 要训练的 PyTorch 模型。
dataloader: 用于模型训练的 DataLoader 实例。
loss_fn: 要最小化的 PyTorch 损失函数。
optimizer: 帮助最小化损失函数的 PyTorch 优化器。
device: 计算目标设备(例如 "cuda" 或 "cpu")。
Returns:
一个包含训练损失和训练准确度指标的元组。
形式为 (train_loss, train_accuracy)。例如:
(0.1112, 0.8743)
"""
# Put model in train mode
model.train()
# Setup train loss and train accuracy values
train_loss, train_acc = 0, 0
# Loop through data loader data batches
for batch, (X, y) in enumerate(dataloader):
# Send data to target device
X, y = X.to(device), y.to(device)
# 1. Forward pass
y_pred = model(X)
# 2. Calculate and accumulate loss
loss = loss_fn(y_pred, y)
train_loss += loss.item()
# 3. Optimizer zero grad
optimizer.zero_grad()
# 4. Loss backward
loss.backward()
# 5. Optimizer step
optimizer.step()
# Calculate and accumulate accuracy metric across all batches
y_pred_class = torch.argmax(torch.softmax(y_pred, dim=1), dim=1)
train_acc += (y_pred_class == y).sum().item()/len(y_pred)
# Adjust metrics to get average loss and accuracy per batch
train_loss = train_loss / len(dataloader)
train_acc = train_acc / len(dataloader)
return train_loss, train_acc
def test_step(model: torch.nn.Module,
dataloader: torch.utils.data.DataLoader,
loss_fn: torch.nn.Module,
device: torch.device) -> Tuple[float, float]:
"""Tests a PyTorch model for a single epoch.
Turns a target PyTorch model to "eval" mode and then performs
a forward pass on a testing dataset.
Args:
model: A PyTorch model to be tested.
dataloader: A DataLoader instance for the model to be tested on.
loss_fn: A PyTorch loss function to calculate loss on the test data.
device: A target device to compute on (e.g. "cuda" or "cpu").
Returns:
A tuple of testing loss and testing accuracy metrics.
In the form (test_loss, test_accuracy). For example:
(0.0223, 0.8985)
"""
# Put model in eval mode
model.eval()
# Setup test loss and test accuracy values
test_loss, test_acc = 0, 0
# Turn on inference context manager
with torch.inference_mode():
# Loop through DataLoader batches
for batch, (X, y) in enumerate(dataloader):
# Send data to target device
X, y = X.to(device), y.to(device)
# 1. Forward pass
test_pred_logits = model(X)
# 2. Calculate and accumulate loss
loss = loss_fn(test_pred_logits, y)
test_loss += loss.item()
# Calculate and accumulate accuracy
test_pred_labels = test_pred_logits.argmax(dim=1)
test_acc += ((test_pred_labels == y).sum().item()/len(test_pred_labels))
# Adjust metrics to get average loss and accuracy per batch
test_loss = test_loss / len(dataloader)
test_acc = test_acc / len(dataloader)
return test_loss, test_acc
def train(model: torch.nn.Module,
train_dataloader: torch.utils.data.DataLoader,
test_dataloader: torch.utils.data.DataLoader,
optimizer: torch.optim.Optimizer,
loss_fn: torch.nn.Module,
epochs: int,
device: torch.device) -> Dict[str, List]:
"""训练和测试一个 PyTorch 模型。
通过 train_step() 和 test_step() 函数对目标 PyTorch 模型进行若干轮次的训练和测试,
在同一个轮次循环中完成训练和测试。
在整个过程中计算、打印并存储评估指标。
Args:
model: 需要训练和测试的 PyTorch 模型。
train_dataloader: 用于模型训练的 DataLoader 实例。
test_dataloader: 用于模型测试的 DataLoader 实例。
optimizer: 帮助最小化损失函数的 PyTorch 优化器。
loss_fn: 用于计算两个数据集上损失的 PyTorch 损失函数。
epochs: 表示训练轮次的整数。
device: 计算目标设备(例如 "cuda" 或 "cpu")。
Returns:
A dictionary of training and testing loss as well as training and
testing accuracy metrics. Each metric has a value in a list for
each epoch.
In the form: {train_loss: [...],
train_acc: [...],
test_loss: [...],
test_acc: [...]}
For example if training for epochs=2:
{train_loss: [2.0616, 1.0537],
train_acc: [0.3945, 0.3945],
test_loss: [1.2641, 1.5706],
test_acc: [0.3400, 0.2973]}
"""
# Create empty results dictionary
results = {"train_loss": [],
"train_acc": [],
"test_loss": [],
"test_acc": []
}
# Loop through training and testing steps for a number of epochs
for epoch in tqdm(range(epochs)):
train_loss, train_acc = train_step(model=model,
dataloader=train_dataloader,
loss_fn=loss_fn,
optimizer=optimizer,
device=device)
test_loss, test_acc = test_step(model=model,
dataloader=test_dataloader,
loss_fn=loss_fn,
device=device)
# Print out what's happening
print(
f"Epoch: {epoch+1} | "
f"train_loss: {train_loss:.4f} | "
f"train_acc: {train_acc:.4f} | "
f"test_loss: {test_loss:.4f} | "
f"test_acc: {test_acc:.4f}"
)
# Update results dictionary
results["train_loss"].append(train_loss)
results["train_acc"].append(train_acc)
results["test_loss"].append(test_loss)
results["test_acc"].append(test_acc)
# Return the filled results at the end of the epochs
return results
现在我们有了 engine.py 脚本,我们可以通过以下方式从中导入函数:
# Import engine.py
from going_modular import engine
# Use train() by calling it from engine.py
engine.train(...)
5. 创建保存模型的函数(utils.py)
在训练过程中或训练后,通常需要保存模型。
由于我们在之前的笔记本中已经多次编写了保存模型的代码,因此将其转换为函数并保存到文件中是合理的。
将辅助函数存储在名为 utils.py 的文件中是一种常见做法(utilities 的缩写)。
让我们将 save_model() 函数保存到一个名为 utils.py 的文件中,使用命令 %%writefile going_modular/utils.py:
%%writefile going_modular/utils.py
"""
Contains various utility functions for PyTorch model training and saving.
"""
import torch
from pathlib import Path
def save_model(model: torch.nn.Module,
target_dir: str,
model_name: str):
"""Saves a PyTorch model to a target directory.
Args:
model: A target PyTorch model to save.
target_dir: A directory for saving the model to.
model_name: A filename for the saved model. Should include
either ".pth" or ".pt" as the file extension.
Example usage:
save_model(model=model_0,
target_dir="models",
model_name="05_going_modular_tingvgg_model.pth")
"""
# Create target directory
target_dir_path = Path(target_dir)
target_dir_path.mkdir(parents=True,
exist_ok=True)
# Create model save path
assert model_name.endswith(".pth") or model_name.endswith(".pt"), "model_name should end with '.pt' or '.pth'"
model_save_path = target_dir_path / model_name
# Save the model state_dict()
print(f"[INFO] Saving model to: {model_save_path}")
torch.save(obj=model.state_dict(),
f=model_save_path)
现在,如果我们想使用 save_model() 函数,而不是重新编写一遍,我们可以导入它并通过以下方式使用:
# Import utils.py
from going_modular import utils
# Save a model to file
save_model(model=...
target_dir=...,
model_name=...)
6. 训练、评估并保存模型(train.py)
如前所述,你经常会遇到将所有功能整合在一个 train.py 文件中的 PyTorch 仓库。
这个文件本质上是在说“使用任何可用数据训练模型”。
在我们的 train.py 文件中,我们将结合我们创建的其他 Python 脚本的所有功能,并用它来训练一个模型。
这样,我们就可以在命令行中使用一行代码来训练一个 PyTorch 模型:
python train.py
为了创建 train.py,我们将按照以下步骤进行:
- 导入各种依赖项,即
torch、os、torchvision.transforms以及going_modular目录中的所有脚本,包括data_setup、engine、model_builder、utils。 - 注意: 由于
train.py将位于going_modular目录内部,我们可以通过import ...而不是from going_modular import ...来导入其他模块。 - 设置各种超参数,如批次大小、训练轮数、学习率和隐藏单元数量(这些参数未来可以通过 Python 的
argparse进行设置)。 - 设置训练和测试目录。
- 设置设备无关代码。
- 创建必要的数据转换。
- 使用
data_setup.py创建 DataLoader。 - 使用
model_builder.py创建模型。 - 设置损失函数和优化器。
- 使用
engine.py训练模型。 - 使用
utils.py保存模型。
我们可以在笔记本单元格中使用以下命令 %%writefile going_modular/train.py 来创建文件:
%%writefile going_modular/train.py
"""
Trains a PyTorch image classification model using device-agnostic code.
"""
import os
import torch
import data_setup, engine, model_builder, utils
from torchvision import transforms
# Setup hyperparameters
NUM_EPOCHS = 5
BATCH_SIZE = 32
HIDDEN_UNITS = 10
LEARNING_RATE = 0.001
# Setup directories
train_dir = "data/pizza_steak_sushi/train"
test_dir = "data/pizza_steak_sushi/test"
# Setup target device
device = "cuda" if torch.cuda.is_available() else "cpu"
# Create transforms
data_transform = transforms.Compose([
transforms.Resize((64, 64)),
transforms.ToTensor()
])
# Create DataLoaders with help from data_setup.py
train_dataloader, test_dataloader, class_names = data_setup.create_dataloaders(
train_dir=train_dir,
test_dir=test_dir,
transform=data_transform,
batch_size=BATCH_SIZE
)
# Create model with help from model_builder.py
model = model_builder.TinyVGG(
input_shape=3,
hidden_units=HIDDEN_UNITS,
output_shape=len(class_names)
).to(device)
# Set loss and optimizer
loss_fn = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(),
lr=LEARNING_RATE)
# Start training with help from engine.py
engine.train(model=model,
train_dataloader=train_dataloader,
test_dataloader=test_dataloader,
loss_fn=loss_fn,
optimizer=optimizer,
epochs=NUM_EPOCHS,
device=device)
# Save the model with help from utils.py
utils.save_model(model=model,
target_dir="models",
model_name="05_going_modular_script_mode_tinyvgg_model.pth")
哇哦!
现在我们可以通过在命令行中运行以下命令来训练一个 PyTorch 模型:
python train.py
这样做将利用我们创建的所有其他代码脚本。
如果我们愿意,我们可以调整 train.py 文件,使用 Python 的 argparse 模块来处理参数标志输入,这将允许我们提供不同的超参数设置,就像之前讨论的那样:
python train.py --model MODEL_NAME --batch_size BATCH_SIZE --lr LEARNING_RATE --num_epochs NUM_EPOCHS
练习
资源:
练习:
- 将获取数据的代码(来自上面的第 1 节 获取数据)转换为 Python 脚本,例如
get_data.py。- 当你运行脚本
python get_data.py时,它应该检查数据是否已经存在并跳过下载(如果存在)。 - 如果数据下载成功,你应该能够从
data目录访问pizza_steak_sushi图像。
- 当你运行脚本
- 使用 Python 的
argparse模块 来为训练过程发送train.py自定义超参数值。- 添加一个用于使用不同的参数:
- 训练/测试目录
- 学习率
- 批量大小
- 训练的周期数
- TinyVGG 模型中的隐藏单元数
- 保持每个参数的默认值为其当前值(如笔记本 05 中所示)。
- 例如,你应该能够运行类似于以下命令来训练一个学习率为 0.003 且批量大小为 64 的 TinyVGG 模型,训练 20 个周期:
python train.py --learning_rate 0.003 --batch_size 64 --num_epochs 20。 - 注意: 由于
train.py利用了我们创建的其他脚本,例如model_builder.py、utils.py和engine.py,你需要确保它们也可用。你可以在课程 GitHub 上的going_modular文件夹 中找到这些脚本。
- 添加一个用于使用不同的参数:
- 创建一个预测脚本(例如
predict.py),使用保存的模型对给定文件路径的目标图像进行预测。- 例如,你应该能够运行命令
python predict.py some_image.jpeg,并让训练好的 PyTorch 模型对图像进行预测并返回其预测结果。 - 要查看示例预测代码,请查看笔记本 04 中的 对自定义图像进行预测部分。
- 你可能还需要编写代码来加载训练好的模型。
- 例如,你应该能够运行命令
额外课程
- 要了解有关构建 Python 项目的更多信息,请查看 Real Python 的指南 Python 应用程序布局。
- 要了解有关样式化 PyTorch 代码的想法,请查看 Igor Susmelj 的 PyTorch 样式指南(本章中的许多样式基于此指南 + 各种类似的 PyTorch 仓库)。
- 要查看由 PyTorch 团队编写的
train.py脚本和其他各种 PyTorch 脚本,以训练最先进的图像分类模型,请查看他们的 GitHub 上的classification仓库。