什么是自定义数据集?¶
自定义数据集是与你正在解决的特定问题相关的数据集合。
本质上,自定义数据集可以由几乎任何东西组成。
例如,如果我们正在构建一个像Nutrify这样的食物图像分类应用,我们的自定义数据集可能是食物的图像。
或者,如果我们试图构建一个模型来分类网站上的文本评论是正面还是负面,我们的自定义数据集可能是现有的客户评论及其评分。
或者,如果我们试图构建一个声音分类应用,我们的自定义数据集可能是带有样本标签的声音样本。
或者,如果我们试图为在我们网站上购物的客户构建一个推荐系统,我们的自定义数据集可能是其他人购买过的产品示例。

PyTorch包含许多现有的函数来加载TorchVision、TorchText、TorchAudio和TorchRec领域库中的各种自定义数据集。
但有时这些现有的函数可能不够。
在这种情况下,我们总是可以子类化torch.utils.data.Dataset并根据我们的喜好进行定制。
我们将涵盖的内容¶
我们将应用在notebook 01和notebook 02中介绍的PyTorch工作流程来解决一个计算机视觉问题。
但这次我们不会使用PyTorch内置的数据集,而是使用我们自己的披萨、牛排和寿司图像数据集。
我们的目标是将这些图像加载进来,然后构建一个模型对其进行训练和预测。
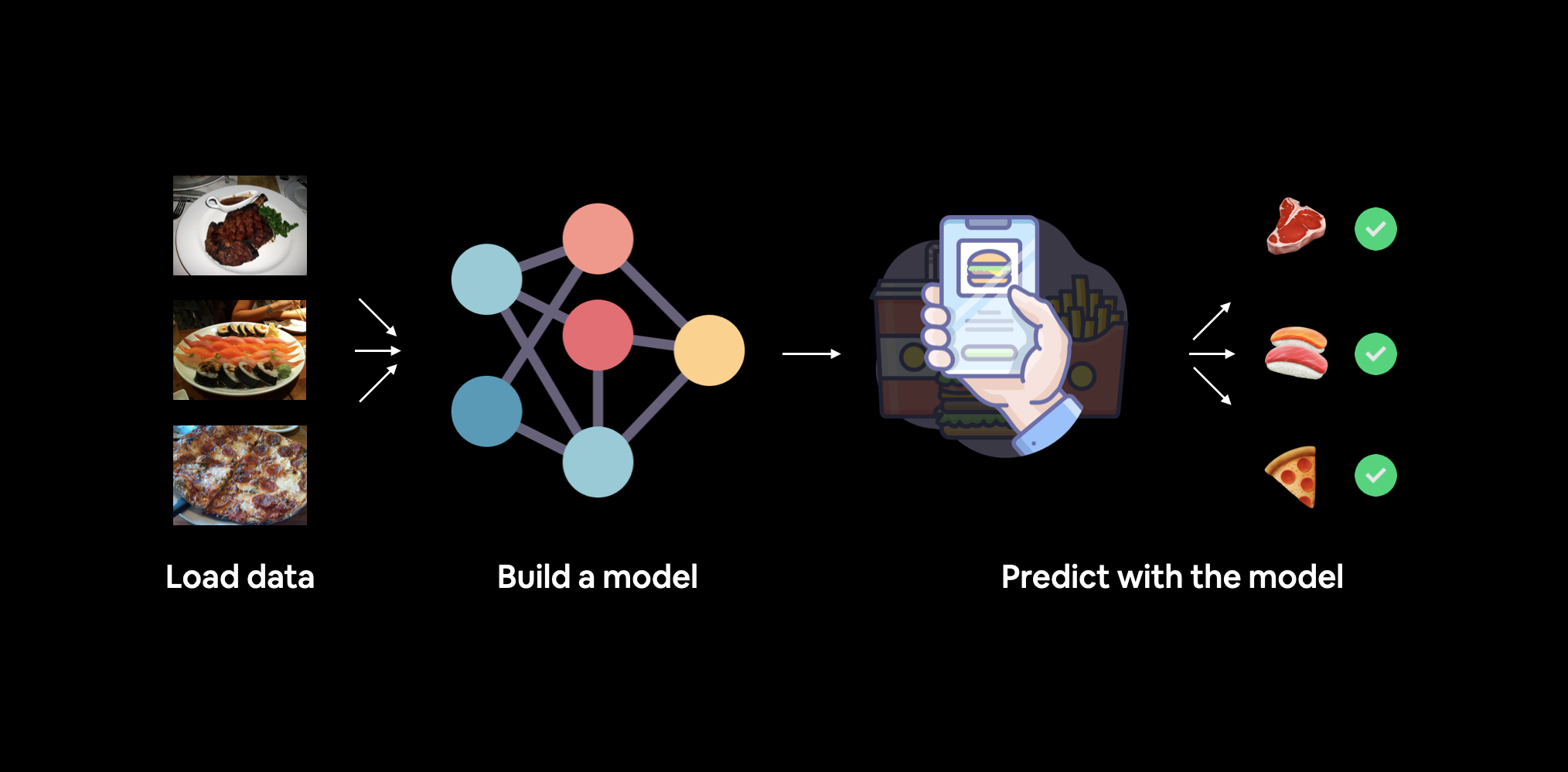
我们将构建的内容。我们将使用torchvision.datasets以及我们自己的自定义Dataset类来加载食物图像,然后我们将构建一个PyTorch计算机视觉模型,希望能够对这些图像进行分类。
具体来说,我们将涵盖以下内容:
| 主题 | 内容 |
|---|---|
| 0. 导入PyTorch并设置设备无关代码 | 让我们加载PyTorch,然后遵循最佳实践来设置我们的代码,使其与设备无关。 |
| 1. 获取数据 | 我们将使用我们自己的自定义数据集,包含披萨、牛排和寿司图像。 |
| 2. 与数据融为一体(数据准备) | 在任何新的机器学习问题开始时,了解你正在处理的数据至关重要。在这里,我们将采取一些步骤来弄清楚我们拥有的数据。 |
| 3. 转换数据 | 通常,你获得的数据不会100%准备好用于机器学习模型,在这里我们将看看一些可以采取的步骤来转换我们的图像,使它们准备好用于模型。 |
4. 使用ImageFolder加载数据(选项1) |
PyTorch有许多内置的数据加载功能,适用于常见类型的数据。ImageFolder在图像处于标准图像分类格式时很有帮助。 |
5. 使用自定义Dataset加载图像数据 |
如果PyTorch没有内置的函数来加载数据怎么办?这时我们可以构建我们自己的torch.utils.data.Dataset子类。 |
| 6. 其他形式的转换(数据增强) | 数据增强是扩展训练数据多样性的常见技术。在这里,我们将探索torchvision的一些内置数据增强功能。 |
| 7. 模型0:不带数据增强的TinyVGG | 到这一步,我们将准备好数据,让我们构建一个能够适应数据的模型。我们还将创建一些用于训练和评估模型的训练和测试函数。 |
| 8. 探索损失曲线 | 损失曲线是查看模型训练/改进随时间变化的好方法。它们也是检查模型是否欠拟合或过拟合的好方法。 |
| 9. 模型1:带数据增强的TinyVGG | 到目前为止,我们已经尝试了一个不带数据增强的模型,现在我们尝试一个带数据增强的模型。 |
| 10. 比较模型结果 | 让我们比较不同模型的损失曲线,看看哪个表现更好,并讨论一些提高性能的选项。 |
| 11. 对自定义图像进行预测 | 我们的模型已经在一个披萨、牛排和寿司图像的数据集上进行了训练。在这一部分,我们将介绍如何使用我们训练好的模型对现有数据集之外的图像进行预测。 |
在哪里可以获得帮助?¶
本课程的所有资料都存放在 GitHub 上。
如果你遇到问题,也可以在课程的 GitHub Discussions 页面 上提问。
当然,还有 PyTorch 文档 和 PyTorch 开发者论坛,这是所有 PyTorch 相关问题的非常有帮助的地方。
0. 导入PyTorch并设置设备无关代码¶
import torch
from torch import nn
# Note: this notebook requires torch >= 1.10.0
torch.__version__
'1.12.1+cu113'
现在,让我们遵循最佳实践,设置与设备无关的代码。
注意: 如果你使用的是 Google Colab,并且还没有启用 GPU,现在是时候通过
Runtime -> Change runtime type -> Hardware accelerator -> GPU来启用一个 GPU 了。如果你这样做,你的运行时可能会重置,你需要通过Runtime -> Run before来运行上面的所有单元格。
# Setup device-agnostic code
device = "cuda" if torch.cuda.is_available() else "cpu"
device
'cuda'
1. 获取数据¶
首先,我们需要一些数据。
就像任何优秀的烹饪节目一样,已经为我们准备好了一些数据。
我们将从小规模开始。
因为我们目前不打算训练最大的模型或使用最大的数据集。
机器学习是一个迭代过程,从小规模开始,先让某些功能运行起来,必要时再增加规模。
我们将使用的数据是 Food101 数据集 的一个子集。
Food101 是一个流行的计算机视觉基准数据集,因为它包含了 101 种不同食物的 1000 张图片,总共 101,000 张图片(75,750 张用于训练,25,250 张用于测试)。
你能想到 101 种不同的食物吗?
你能想到一个用于分类 101 种食物的计算机程序吗?
我可以。
一个机器学习模型!
具体来说,是一个像我们在 notebook 03 中介绍的 PyTorch 计算机视觉模型。
不过,我们不会从 101 种食物类别开始,而是从 3 种开始:披萨、牛排和寿司。
并且,我们不会从每类 1,000 张图片开始,而是从随机 10% 开始(从小规模开始,必要时再增加)。
如果你想查看数据的来源,可以参考以下资源:
- 原始 Food101 数据集和论文网站。
torchvision.datasets.Food101- 我为本笔记本下载的数据版本。extras/04_custom_data_creation.ipynb- 我用于格式化 Food101 数据集以供本笔记本使用的笔记本。data/pizza_steak_sushi.zip- 从 Food101 数据集中提取的披萨、牛排和寿司图片的压缩包,由上述笔记本创建。
让我们编写一些代码,从 GitHub 下载格式化后的数据。
注意: 我们即将使用的数据集已经预先格式化为我们希望使用的形式。然而,你通常需要为你正在解决的任何问题格式化你自己的数据集。这是机器学习领域的常规做法。
import requests
import zipfile
from pathlib import Path
# Setup path to data folder
data_path = Path("data/")
image_path = data_path / "pizza_steak_sushi"
# If the image folder doesn't exist, download it and prepare it...
if image_path.is_dir():
print(f"{image_path} directory exists.")
else:
print(f"Did not find {image_path} directory, creating one...")
image_path.mkdir(parents=True, exist_ok=True)
# Download pizza, steak, sushi data
with open(data_path / "pizza_steak_sushi.zip", "wb") as f:
request = requests.get("https://github.com/mrdbourke/pytorch-deep-learning/raw/main/data/pizza_steak_sushi.zip")
print("Downloading pizza, steak, sushi data...")
f.write(request.content)
# Unzip pizza, steak, sushi data
with zipfile.ZipFile(data_path / "pizza_steak_sushi.zip", "r") as zip_ref:
print("Unzipping pizza, steak, sushi data...")
zip_ref.extractall(image_path)
data/pizza_steak_sushi directory exists.
2. 深入理解数据(数据准备)¶
数据集已下载!
现在是深入理解它的时候了。
这是构建模型之前的另一个重要步骤。
正如亚伯拉罕·损失函数所说...

数据准备至关重要。在构建模型之前,深入理解数据。问自己:我在这里试图做什么?来源:@mrdbourke Twitter。
什么是检查数据并深入理解它?
在开始一个项目或构建任何类型的模型之前,了解你正在处理的数据是非常重要的。
在我们的例子中,我们有标准图像分类格式的披萨、牛排和寿司的图像。
图像分类格式包含不同类别的图像,这些图像分别存储在以特定类别名称命名的目录中。
例如,所有 pizza 的图像都包含在 pizza/ 目录中。
这种格式在许多不同的图像分类基准测试中都很流行,包括 ImageNet(最流行的计算机视觉基准数据集之一)。
你可以在下面看到存储格式的示例,图像编号是任意的。
pizza_steak_sushi/ <- 总体数据集文件夹
train/ <- 训练图像
pizza/ <- 类别名称作为文件夹名称
image01.jpeg
image02.jpeg
...
steak/
image24.jpeg
image25.jpeg
...
sushi/
image37.jpeg
...
test/ <- 测试图像
pizza/
image101.jpeg
image102.jpeg
...
steak/
image154.jpeg
image155.jpeg
...
sushi/
image167.jpeg
...
目标是将这种数据存储结构转换为可与 PyTorch 一起使用的数据集。
注意: 你处理的数据结构会根据你正在解决的问题而有所不同。但前提仍然是一样的:深入理解数据,然后找到将其转换为与 PyTorch 兼容的数据集的最佳方法。
我们可以通过编写一个小的辅助函数来遍历每个子目录并计算文件数量,从而检查数据目录中的内容。
为此,我们将使用 Python 内置的 os.walk()。
import os
def walk_through_dir(dir_path):
"""
Walks through dir_path returning its contents.
Args:
dir_path (str or pathlib.Path): target directory
Returns:
A print out of:
number of subdiretories in dir_path
number of images (files) in each subdirectory
name of each subdirectory
"""
for dirpath, dirnames, filenames in os.walk(dir_path):
print(f"There are {len(dirnames)} directories and {len(filenames)} images in '{dirpath}'.")
walk_through_dir(image_path)
There are 2 directories and 1 images in 'data/pizza_steak_sushi'. There are 3 directories and 0 images in 'data/pizza_steak_sushi/test'. There are 0 directories and 19 images in 'data/pizza_steak_sushi/test/steak'. There are 0 directories and 31 images in 'data/pizza_steak_sushi/test/sushi'. There are 0 directories and 25 images in 'data/pizza_steak_sushi/test/pizza'. There are 3 directories and 0 images in 'data/pizza_steak_sushi/train'. There are 0 directories and 75 images in 'data/pizza_steak_sushi/train/steak'. There are 0 directories and 72 images in 'data/pizza_steak_sushi/train/sushi'. There are 0 directories and 78 images in 'data/pizza_steak_sushi/train/pizza'.
太棒了!
看起来我们每个训练类别大约有 75 张图片,每个测试类别大约有 25 张图片。
这应该足够我们开始了。
请记住,这些图像是原始 Food101 数据集的子集。
你可以在数据创建笔记本中查看它们的创建过程。
趁现在,我们来设置训练和测试的路径吧。
# Setup train and testing paths
train_dir = image_path / "train"
test_dir = image_path / "test"
train_dir, test_dir
(PosixPath('data/pizza_steak_sushi/train'),
PosixPath('data/pizza_steak_sushi/test'))
2.1 可视化图像¶
好的,我们已经了解了目录结构的格式。
现在,本着数据探索者的精神,是时候进行 可视化、可视化、可视化!
让我们编写一些代码来:
- 使用
pathlib.Path.glob()获取所有以.jpg结尾的图像路径。 - 使用 Python 的
random.choice()随机选择一个图像路径。 - 使用
pathlib.Path.parent.stem获取图像的类别名称。 - 由于我们正在处理图像,我们将使用
PIL.Image.open()(PIL 代表 Python 图像库)打开随机图像路径。 - 然后我们将显示图像并打印一些元数据。
import random
from PIL import Image
# Set seed
random.seed(42) # <- try changing this and see what happens
# 1. Get all image paths (* means "any combination")
image_path_list = list(image_path.glob("*/*/*.jpg"))
# 2. Get random image path
random_image_path = random.choice(image_path_list)
# 3. Get image class from path name (the image class is the name of the directory where the image is stored)
image_class = random_image_path.parent.stem
# 4. Open image
img = Image.open(random_image_path)
# 5. Print metadata
print(f"Random image path: {random_image_path}")
print(f"Image class: {image_class}")
print(f"Image height: {img.height}")
print(f"Image width: {img.width}")
img
Random image path: data/pizza_steak_sushi/test/pizza/2124579.jpg Image class: pizza Image height: 384 Image width: 512

我们可以对 matplotlib.pyplot.imshow() 做同样的事情,只不过我们需要先将图像转换为 NumPy 数组。
import numpy as np
import matplotlib.pyplot as plt
# Turn the image into an array
img_as_array = np.asarray(img)
# Plot the image with matplotlib
plt.figure(figsize=(10, 7))
plt.imshow(img_as_array)
plt.title(f"Image class: {image_class} | Image shape: {img_as_array.shape} -> [height, width, color_channels]")
plt.axis(False);

3. 数据转换¶
现在,如果我们想将图像数据加载到 PyTorch 中,应该怎么做呢?
在使用 PyTorch 处理图像数据之前,我们需要:
- 将其转换为张量(图像的数值表示)。
- 将其转换为
torch.utils.data.Dataset,进而转换为torch.utils.data.DataLoader,我们简称这些为Dataset和DataLoader。
根据所处理的问题类型,PyTorch 提供了多种预构建的数据集和数据加载器。
| 问题领域 | 预构建的数据集和函数 |
|---|---|
| 视觉 | torchvision.datasets |
| 音频 | torchaudio.datasets |
| 文本 | torchtext.datasets |
| 推荐系统 | torchrec.datasets |
由于我们处理的是视觉问题,我们将使用 torchvision.datasets 进行数据加载,并使用 torchvision.transforms 来准备数据。
让我们导入一些基础库。
import torch
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
3.1 使用 torchvision.transforms 转换数据¶
我们拥有文件夹中的图像,但在使用 PyTorch 之前,我们需要将它们转换为张量。
我们可以使用 torchvision.transforms 模块来实现这一点。
torchvision.transforms 包含许多预构建的方法来格式化图像,将它们转换为张量,甚至进行数据增强(通过改变数据使模型更难以学习,我们稍后会看到这一点)。
为了熟悉 torchvision.transforms,让我们编写一系列转换步骤,这些步骤将:
- 使用
transforms.Resize()调整图像大小(从大约 512x512 调整为 64x64,与 CNN Explainer 网站 上的图像形状相同)。 - 使用
transforms.RandomHorizontalFlip()随机水平翻转我们的图像(这可以被视为数据增强的一种形式,因为它会人为地改变我们的图像数据)。 - 使用
transforms.ToTensor()将我们的图像从 PIL 图像转换为 PyTorch 张量。
我们可以使用 torchvision.transforms.Compose() 将所有这些步骤组合在一起。
# Write transform for image
data_transform = transforms.Compose([
# Resize the images to 64x64
transforms.Resize(size=(64, 64)),
# Flip the images randomly on the horizontal
transforms.RandomHorizontalFlip(p=0.5), # p = probability of flip, 0.5 = 50% chance
# Turn the image into a torch.Tensor
transforms.ToTensor() # this also converts all pixel values from 0 to 255 to be between 0.0 and 1.0
])
现在我们已经有了一个变换的组合,接下来让我们编写一个函数,尝试将这些变换应用于各种图像。
def plot_transformed_images(image_paths, transform, n=3, seed=42):
"""Plots a series of random images from image_paths.
Will open n image paths from image_paths, transform them
with transform and plot them side by side.
Args:
image_paths (list): List of target image paths.
transform (PyTorch Transforms): Transforms to apply to images.
n (int, optional): Number of images to plot. Defaults to 3.
seed (int, optional): Random seed for the random generator. Defaults to 42.
"""
random.seed(seed)
random_image_paths = random.sample(image_paths, k=n)
for image_path in random_image_paths:
with Image.open(image_path) as f:
fig, ax = plt.subplots(1, 2)
ax[0].imshow(f)
ax[0].set_title(f"Original \nSize: {f.size}")
ax[0].axis("off")
# Transform and plot image
# Note: permute() will change shape of image to suit matplotlib
# (PyTorch default is [C, H, W] but Matplotlib is [H, W, C])
transformed_image = transform(f).permute(1, 2, 0)
ax[1].imshow(transformed_image)
ax[1].set_title(f"Transformed \nSize: {transformed_image.shape}")
ax[1].axis("off")
fig.suptitle(f"Class: {image_path.parent.stem}", fontsize=16)
plot_transformed_images(image_path_list,
transform=data_transform,
n=3)



太棒了!
我们现在有了一个方法,可以使用 torchvision.transforms 将图像转换为张量。
如果需要,我们还可以调整它们的大小和方向(有些模型偏好不同大小和形状的图像)。
通常情况下,图像的形状越大,模型能恢复的信息就越多。
例如,大小为 [256, 256, 3] 的图像将比大小为 [64, 64, 3] 的图像多 16 倍的像素((256*256*3)/(64*64*3)=16)。
然而,权衡之处在于,更多的像素需要更多的计算。
练习: 尝试注释掉
data_transform中的一个变换,然后再次运行绘图函数plot_transformed_images(),看看会发生什么?
4. 选项1:使用 ImageFolder 加载图像数据¶
好了,是时候将我们的图像数据转换成一个可以与 PyTorch 一起使用的 Dataset 了。
由于我们的数据采用标准的图像分类格式,我们可以使用 torchvision.datasets.ImageFolder 类。
我们可以将目标图像目录的文件路径以及一系列希望对图像执行的变换传递给它。
让我们在我们的数据文件夹 train_dir 和 test_dir 上测试一下,传递 transform=data_transform 将图像转换为张量。
# Use ImageFolder to create dataset(s)
from torchvision import datasets
train_data = datasets.ImageFolder(root=train_dir, # target folder of images
transform=data_transform, # transforms to perform on data (images)
target_transform=None) # transforms to perform on labels (if necessary)
test_data = datasets.ImageFolder(root=test_dir,
transform=data_transform)
print(f"Train data:\n{train_data}\nTest data:\n{test_data}")
Train data:
Dataset ImageFolder
Number of datapoints: 225
Root location: data/pizza_steak_sushi/train
StandardTransform
Transform: Compose(
Resize(size=(64, 64), interpolation=bilinear, max_size=None, antialias=None)
RandomHorizontalFlip(p=0.5)
ToTensor()
)
Test data:
Dataset ImageFolder
Number of datapoints: 75
Root location: data/pizza_steak_sushi/test
StandardTransform
Transform: Compose(
Resize(size=(64, 64), interpolation=bilinear, max_size=None, antialias=None)
RandomHorizontalFlip(p=0.5)
ToTensor()
)
太棒了!
看起来 PyTorch 已经注册了我们的 Dataset。
让我们通过查看 classes 和 class_to_idx 属性以及我们的训练集和测试集的长度来检查它们。
# Get class names as a list
class_names = train_data.classes
class_names
['pizza', 'steak', 'sushi']
# Can also get class names as a dict
class_dict = train_data.class_to_idx
class_dict
{'pizza': 0, 'steak': 1, 'sushi': 2}
# Check the lengths
len(train_data), len(test_data)
(225, 75)
好的!看起来我们可以用这些作为参考,以备后用。
那么我们的图像和标签呢?
它们看起来怎么样?
我们可以对 train_data 和 test_data 的 Dataset 进行索引,以找到样本及其目标标签。
img, label = train_data[0][0], train_data[0][1]
print(f"Image tensor:\n{img}")
print(f"Image shape: {img.shape}")
print(f"Image datatype: {img.dtype}")
print(f"Image label: {label}")
print(f"Label datatype: {type(label)}")
Image tensor:
tensor([[[0.1137, 0.1020, 0.0980, ..., 0.1255, 0.1216, 0.1176],
[0.1059, 0.0980, 0.0980, ..., 0.1294, 0.1294, 0.1294],
[0.1020, 0.0980, 0.0941, ..., 0.1333, 0.1333, 0.1333],
...,
[0.1098, 0.1098, 0.1255, ..., 0.1686, 0.1647, 0.1686],
[0.0863, 0.0941, 0.1098, ..., 0.1686, 0.1647, 0.1686],
[0.0863, 0.0863, 0.0980, ..., 0.1686, 0.1647, 0.1647]],
[[0.0745, 0.0706, 0.0745, ..., 0.0588, 0.0588, 0.0588],
[0.0706, 0.0706, 0.0745, ..., 0.0627, 0.0627, 0.0627],
[0.0706, 0.0745, 0.0745, ..., 0.0706, 0.0706, 0.0706],
...,
[0.1255, 0.1333, 0.1373, ..., 0.2510, 0.2392, 0.2392],
[0.1098, 0.1176, 0.1255, ..., 0.2510, 0.2392, 0.2314],
[0.1020, 0.1059, 0.1137, ..., 0.2431, 0.2353, 0.2275]],
[[0.0941, 0.0902, 0.0902, ..., 0.0196, 0.0196, 0.0196],
[0.0902, 0.0863, 0.0902, ..., 0.0196, 0.0157, 0.0196],
[0.0902, 0.0902, 0.0902, ..., 0.0157, 0.0157, 0.0196],
...,
[0.1294, 0.1333, 0.1490, ..., 0.1961, 0.1882, 0.1804],
[0.1098, 0.1137, 0.1255, ..., 0.1922, 0.1843, 0.1804],
[0.1059, 0.1020, 0.1059, ..., 0.1843, 0.1804, 0.1765]]])
Image shape: torch.Size([3, 64, 64])
Image datatype: torch.float32
Image label: 0
Label datatype: <class 'int'>
我们的图像现在是以张量形式存在的(形状为 [3, 64, 64]),而标签是以与特定类别相关的整数形式存在的(通过 class_to_idx 属性引用)。
我们如何使用 matplotlib 绘制一个单一的图像张量呢?
首先,我们需要对张量进行维度重排(重新排列其维度的顺序),使其兼容。
目前,我们的图像维度格式是 CHW(颜色通道,高度,宽度),但 matplotlib 更倾向于 HWC(高度,宽度,颜色通道)。
# Rearrange the order of dimensions
img_permute = img.permute(1, 2, 0)
# Print out different shapes (before and after permute)
print(f"Original shape: {img.shape} -> [color_channels, height, width]")
print(f"Image permute shape: {img_permute.shape} -> [height, width, color_channels]")
# Plot the image
plt.figure(figsize=(10, 7))
plt.imshow(img.permute(1, 2, 0))
plt.axis("off")
plt.title(class_names[label], fontsize=14);
Original shape: torch.Size([3, 64, 64]) -> [color_channels, height, width] Image permute shape: torch.Size([64, 64, 3]) -> [height, width, color_channels]

注意,图像现在变得更加像素化(质量降低)。
这是由于图像从 512x512 像素调整到了 64x64 像素。
这里的直觉是,如果你觉得图像更难以识别其中的内容,那么模型也很可能更难以理解它。
4.1 将加载的图像转换为 DataLoader¶
我们已经将图像作为 PyTorch 的 Dataset,现在让我们将它们转换为 DataLoader。
我们将使用 torch.utils.data.DataLoader 来实现这一点。
将我们的 Dataset 转换为 DataLoader 使它们可迭代,这样模型可以学习样本和目标之间的关系(特征和标签)。
为了简单起见,我们将使用 batch_size=1 和 num_workers=1。
什么是 num_workers?
好问题。
它定义了将创建多少个子进程来加载数据。
可以这样理解,num_workers 设置的值越高,PyTorch 将使用更多的计算能力来加载数据。
我个人通常将其设置为我机器上的 CPU 总数,通过 Python 的 os.cpu_count()。
这样可以确保 DataLoader 尽可能多地招募核心来加载数据。
注意: 你可以在 PyTorch 文档 中了解更多关于
torch.utils.data.DataLoader的参数。
# Turn train and test Datasets into DataLoaders
from torch.utils.data import DataLoader
train_dataloader = DataLoader(dataset=train_data,
batch_size=1, # how many samples per batch?
num_workers=1, # how many subprocesses to use for data loading? (higher = more)
shuffle=True) # shuffle the data?
test_dataloader = DataLoader(dataset=test_data,
batch_size=1,
num_workers=1,
shuffle=False) # don't usually need to shuffle testing data
train_dataloader, test_dataloader
(<torch.utils.data.dataloader.DataLoader at 0x7f53c0b9dca0>, <torch.utils.data.dataloader.DataLoader at 0x7f53c0b9de50>)
太好了!
现在我们的数据是可迭代的了。
让我们试一试并检查形状。
img, label = next(iter(train_dataloader))
# Batch size will now be 1, try changing the batch_size parameter above and see what happens
print(f"Image shape: {img.shape} -> [batch_size, color_channels, height, width]")
print(f"Label shape: {label.shape}")
Image shape: torch.Size([1, 3, 64, 64]) -> [batch_size, color_channels, height, width] Label shape: torch.Size([1])
我们现在可以使用这些 DataLoader 在训练和测试循环中来训练一个模型。
但在我们这样做之前,让我们看看另一种加载图像(或几乎任何其他类型的数据)的方法。
5. 选项2:使用自定义的 Dataset 加载图像数据¶
如果像 torchvision.datasets.ImageFolder() 这样的预构建 Dataset 创建器不存在怎么办?
或者针对你的特定问题没有这样的创建器怎么办?
你可以自己构建一个。
但是等等,创建自己的自定义 Dataset 有哪些利弊呢?
创建自定义 Dataset 的优点 |
创建自定义 Dataset 的缺点 |
|---|---|
几乎可以从任何数据源创建 Dataset。 |
虽然你可以从几乎任何数据源创建 Dataset,但这并不意味着它会正常工作。 |
不受限于 PyTorch 预构建的 Dataset 函数。 |
使用自定义 Dataset 通常会导致编写更多代码,这可能会容易出错或性能问题。 |
为了实际操作,让我们通过继承 torch.utils.data.Dataset(PyTorch 中所有 Dataset 的基类)来复制 torchvision.datasets.ImageFolder() 的功能。
首先,我们需要导入所需的模块:
- Python 的
os模块用于处理目录(我们的数据存储在目录中)。 - Python 的
pathlib模块用于处理文件路径(每个图像都有唯一的文件路径)。 torch用于所有 PyTorch 相关操作。- PIL 的
Image类用于加载图像。 torch.utils.data.Dataset用于继承并创建我们自己的自定义Dataset。torchvision.transforms用于将图像转换为张量。- Python 的
typing模块中的各种类型,用于为代码添加类型提示。
注意: 你可以根据你自己的数据集自定义以下步骤。前提是:编写代码以你希望的格式加载数据。
import os
import pathlib
import torch
from PIL import Image
from torch.utils.data import Dataset
from torchvision import transforms
from typing import Tuple, Dict, List
还记得我们使用 torchvision.datasets.ImageFolder() 的实例时,是如何利用 classes 和 class_to_idx 属性的吗?
# Instance of torchvision.datasets.ImageFolder()
train_data.classes, train_data.class_to_idx
(['pizza', 'steak', 'sushi'], {'pizza': 0, 'steak': 1, 'sushi': 2})
5.1 创建一个辅助函数以获取类名¶
我们来编写一个辅助函数,该函数能够在给定目录路径的情况下创建一个类名列表和一个包含类名及其索引的字典。
为此,我们将:
- 使用
os.scandir()遍历目标目录以获取类名(理想情况下,目录应采用标准图像分类格式)。 - 如果找不到类名,则抛出一个错误(如果发生这种情况,可能是目录结构有问题)。
- 将类名转换为数值标签的字典,每个类对应一个标签。
在我们编写完整函数之前,先来看一个小例子,了解步骤1的实现。
# Setup path for target directory
target_directory = train_dir
print(f"Target directory: {target_directory}")
# Get the class names from the target directory
class_names_found = sorted([entry.name for entry in list(os.scandir(image_path / "train"))])
print(f"Class names found: {class_names_found}")
Target directory: data/pizza_steak_sushi/train Class names found: ['pizza', 'steak', 'sushi']
非常好!
我们何不将其转化为一个完整的函数呢?
# Make function to find classes in target directory
def find_classes(directory: str) -> Tuple[List[str], Dict[str, int]]:
"""Finds the class folder names in a target directory.
Assumes target directory is in standard image classification format.
Args:
directory (str): target directory to load classnames from.
Returns:
Tuple[List[str], Dict[str, int]]: (list_of_class_names, dict(class_name: idx...))
Example:
find_classes("food_images/train")
>>> (["class_1", "class_2"], {"class_1": 0, ...})
"""
# 1. Get the class names by scanning the target directory
classes = sorted(entry.name for entry in os.scandir(directory) if entry.is_dir())
# 2. Raise an error if class names not found
if not classes:
raise FileNotFoundError(f"Couldn't find any classes in {directory}.")
# 3. Create a dictionary of index labels (computers prefer numerical rather than string labels)
class_to_idx = {cls_name: i for i, cls_name in enumerate(classes)}
return classes, class_to_idx
看起来不错!
现在让我们测试一下我们的 find_classes() 函数。
find_classes(train_dir)
(['pizza', 'steak', 'sushi'], {'pizza': 0, 'steak': 1, 'sushi': 2})
哇哦!看起来不错!
5.2 创建自定义 Dataset 以复制 ImageFolder¶
现在我们准备好构建自己的自定义 Dataset 了。
我们将构建一个以复制 torchvision.datasets.ImageFolder() 的功能。
这将是一个很好的练习,此外,它还会揭示一些创建自己的自定义 Dataset 所需的步骤。
这会是一段相当多的代码...但我们完全可以应对!
让我们逐步分解:
- 继承
torch.utils.data.Dataset类。 - 使用
targ_dir参数(目标数据目录)和transform参数(以便在需要时对数据进行转换)初始化我们的子类。 - 创建几个属性,包括
paths(目标图像的路径)、transform(我们可能希望使用的转换,可以是None)、classes和class_to_idx(从我们的find_classes()函数中获取)。 - 创建一个函数,从文件加载图像并返回它们,可以使用
PIL或torchvision.io(用于视觉数据的输入/输出)。 - 重写
torch.utils.data.Dataset的__len__方法,以返回Dataset中的样本数量,这是推荐的但不是必需的。这样你可以调用len(Dataset)。 - 重写
torch.utils.data.Dataset的__getitem__方法,以从Dataset中返回单个样本,这是必需的。
让我们开始吧!
# Write a custom dataset class (inherits from torch.utils.data.Dataset)
from torch.utils.data import Dataset
# 1. Subclass torch.utils.data.Dataset
class ImageFolderCustom(Dataset):
# 2. Initialize with a targ_dir and transform (optional) parameter
def __init__(self, targ_dir: str, transform=None) -> None:
# 3. Create class attributes
# Get all image paths
self.paths = list(pathlib.Path(targ_dir).glob("*/*.jpg")) # note: you'd have to update this if you've got .png's or .jpeg's
# Setup transforms
self.transform = transform
# Create classes and class_to_idx attributes
self.classes, self.class_to_idx = find_classes(targ_dir)
# 4. Make function to load images
def load_image(self, index: int) -> Image.Image:
"Opens an image via a path and returns it."
image_path = self.paths[index]
return Image.open(image_path)
# 5. Overwrite the __len__() method (optional but recommended for subclasses of torch.utils.data.Dataset)
def __len__(self) -> int:
"Returns the total number of samples."
return len(self.paths)
# 6. Overwrite the __getitem__() method (required for subclasses of torch.utils.data.Dataset)
def __getitem__(self, index: int) -> Tuple[torch.Tensor, int]:
"Returns one sample of data, data and label (X, y)."
img = self.load_image(index)
class_name = self.paths[index].parent.name # expects path in data_folder/class_name/image.jpeg
class_idx = self.class_to_idx[class_name]
# Transform if necessary
if self.transform:
return self.transform(img), class_idx # return data, label (X, y)
else:
return img, class_idx # return data, label (X, y)
哇!一大堆代码来加载我们的图像。
这是创建自己的自定义 Dataset 的一个缺点。
不过,现在我们已经写了一次,可以将其移到一个 .py 文件中,例如 data_loader.py,并加入一些其他有用的数据函数,以便以后重复使用。
在我们测试新的 ImageFolderCustom 类之前,让我们创建一些变换来准备我们的图像。
# Augment train data
train_transforms = transforms.Compose([
transforms.Resize((64, 64)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor()
])
# Don't augment test data, only reshape
test_transforms = transforms.Compose([
transforms.Resize((64, 64)),
transforms.ToTensor()
])
现在到了揭晓真相的时刻!
让我们将训练图像(包含在 train_dir 中)和测试图像(包含在 test_dir 中)使用我们自定义的 ImageFolderCustom 类转换为 Dataset。
train_data_custom = ImageFolderCustom(targ_dir=train_dir,
transform=train_transforms)
test_data_custom = ImageFolderCustom(targ_dir=test_dir,
transform=test_transforms)
train_data_custom, test_data_custom
(<__main__.ImageFolderCustom at 0x7f5461f70c70>, <__main__.ImageFolderCustom at 0x7f5461f70c40>)
嗯... 没有错误,成功了吗?
我们来尝试对新的 Dataset 调用 len(),并查找 classes 和 class_to_idx 属性。
len(train_data_custom), len(test_data_custom)
(225, 75)
train_data_custom.classes
['pizza', 'steak', 'sushi']
train_data_custom.class_to_idx
{'pizza': 0, 'steak': 1, 'sushi': 2}
len(test_data_custom) == len(test_data) 并且 len(test_data_custom) == len(test_data) 是的!!!
看起来它起作用了。
我们也可以检查由 torchvision.datasets.ImageFolder() 类创建的 Dataset 是否相等。
# Check for equality amongst our custom Dataset and ImageFolder Dataset
print((len(train_data_custom) == len(train_data)) & (len(test_data_custom) == len(test_data)))
print(train_data_custom.classes == train_data.classes)
print(train_data_custom.class_to_idx == train_data.class_to_idx)
True True True
呵呵!
看看我们进展得多顺利!
三个 True!
这已经相当不错了。
不如我们再提升一个档次,绘制一些随机图像来测试我们的 __getitem__ 重写?
5.3 创建一个显示随机图像的函数¶
你知道现在是什么时候了!
是时候戴上我们的数据探索者帽子,可视化,可视化,可视化!
让我们创建一个名为 display_random_images() 的辅助函数,帮助我们在 Dataset 中可视化图像。
具体来说,它将:
- 接受一个
Dataset和一些其他参数,如classes(目标类别的名称)、要显示的图像数量n和一个随机种子。 - 为了防止显示失控,我们将
n限制在 10 张图像以内。 - 设置随机种子以确保绘图的可重复性(如果设置了
seed)。 - 获取一个随机样本索引列表(我们可以使用 Python 的
random.sample()来实现这一点)以进行绘图。 - 设置一个
matplotlib绘图环境。 - 遍历在步骤 4 中找到的随机样本索引,并使用
matplotlib绘制它们。 - 确保样本图像的形状为
HWC(高度,宽度,颜色通道),以便我们可以绘制它们。
# 1. Take in a Dataset as well as a list of class names
def display_random_images(dataset: torch.utils.data.dataset.Dataset,
classes: List[str] = None,
n: int = 10,
display_shape: bool = True,
seed: int = None):
# 2. Adjust display if n too high
if n > 10:
n = 10
display_shape = False
print(f"For display purposes, n shouldn't be larger than 10, setting to 10 and removing shape display.")
# 3. Set random seed
if seed:
random.seed(seed)
# 4. Get random sample indexes
random_samples_idx = random.sample(range(len(dataset)), k=n)
# 5. Setup plot
plt.figure(figsize=(16, 8))
# 6. Loop through samples and display random samples
for i, targ_sample in enumerate(random_samples_idx):
targ_image, targ_label = dataset[targ_sample][0], dataset[targ_sample][1]
# 7. Adjust image tensor shape for plotting: [color_channels, height, width] -> [color_channels, height, width]
targ_image_adjust = targ_image.permute(1, 2, 0)
# Plot adjusted samples
plt.subplot(1, n, i+1)
plt.imshow(targ_image_adjust)
plt.axis("off")
if classes:
title = f"class: {classes[targ_label]}"
if display_shape:
title = title + f"\nshape: {targ_image_adjust.shape}"
plt.title(title)
这个函数看起来真不错!
我们先在用 torchvision.datasets.ImageFolder() 创建的 Dataset 上测试一下。
# Display random images from ImageFolder created Dataset
display_random_images(train_data,
n=5,
classes=class_names,
seed=None)

现在,我们有了使用自定义的 ImageFolderCustom 创建的 Dataset。
# Display random images from ImageFolderCustom Dataset
display_random_images(train_data_custom,
n=12,
classes=class_names,
seed=None) # Try setting the seed for reproducible images
For display purposes, n shouldn't be larger than 10, setting to 10 and removing shape display.

太棒了!
看来我们的 ImageFolderCustom 运行得正如我们所期望的那样。
5.4 将自定义加载的图像转换为 DataLoader¶
我们已经有了通过 ImageFolderCustom 类将原始图像转换为 Dataset 的方法(即将特征映射到标签或 X 映射到 y)。
那么,我们如何将自定义的 Dataset 转换为 DataLoader 呢?
如果你猜是通过使用 torch.utils.data.DataLoader(),那就对了!
因为我们的自定义 Dataset 继承自 torch.utils.data.Dataset,所以我们可以直接将它们与 torch.utils.data.DataLoader() 一起使用。
我们可以使用与之前非常相似的步骤,只不过这次我们将使用我们自定义创建的 Dataset。
# Turn train and test custom Dataset's into DataLoader's
from torch.utils.data import DataLoader
train_dataloader_custom = DataLoader(dataset=train_data_custom, # use custom created train Dataset
batch_size=1, # how many samples per batch?
num_workers=0, # how many subprocesses to use for data loading? (higher = more)
shuffle=True) # shuffle the data?
test_dataloader_custom = DataLoader(dataset=test_data_custom, # use custom created test Dataset
batch_size=1,
num_workers=0,
shuffle=False) # don't usually need to shuffle testing data
train_dataloader_custom, test_dataloader_custom
(<torch.utils.data.dataloader.DataLoader at 0x7f5460ab8400>, <torch.utils.data.dataloader.DataLoader at 0x7f5460ab8490>)
样品的形状看起来是否相同?
# Get image and label from custom DataLoader
img_custom, label_custom = next(iter(train_dataloader_custom))
# Batch size will now be 1, try changing the batch_size parameter above and see what happens
print(f"Image shape: {img_custom.shape} -> [batch_size, color_channels, height, width]")
print(f"Label shape: {label_custom.shape}")
Image shape: torch.Size([1, 3, 64, 64]) -> [batch_size, color_channels, height, width] Label shape: torch.Size([1])
确实如此!
现在让我们来看看其他形式的数据转换。
6. 其他形式的变换(数据增强)¶
我们已经了解了一些数据变换的方法,但实际上还有很多。
你可以在 torchvision.transforms 文档中查看所有变换。
变换的目的是以某种方式改变你的图像。
这可能是将你的图像转换为张量(如我们之前所见)。
或者是裁剪图像、随机擦除部分区域或随机旋转它们。
这类变换通常被称为数据增强。
数据增强是通过改变数据的方式来人工增加训练集的多样性。
在这种人工改变的数据集上训练模型,有望使模型具有更好的泛化能力(它学到的模式对未来的未见示例更加鲁棒)。
你可以在 PyTorch 的 变换示例图解中看到许多使用 torchvision.transforms 对图像进行数据增强的不同示例。
但让我们自己尝试一下。
机器学习都是关于利用随机性的力量,研究表明随机变换(如 transforms.RandAugment() 和 transforms.TrivialAugmentWide())通常比手工挑选的变换表现更好。
TrivialAugment 背后的想法...嗯,很简单。
你有一组变换,随机选择其中一些对图像进行变换,并在给定范围内随机选择变换的强度(强度越高意味着越强烈)。
PyTorch 团队甚至使用 TrivialAugment 训练了他们最新的最先进的视觉模型。
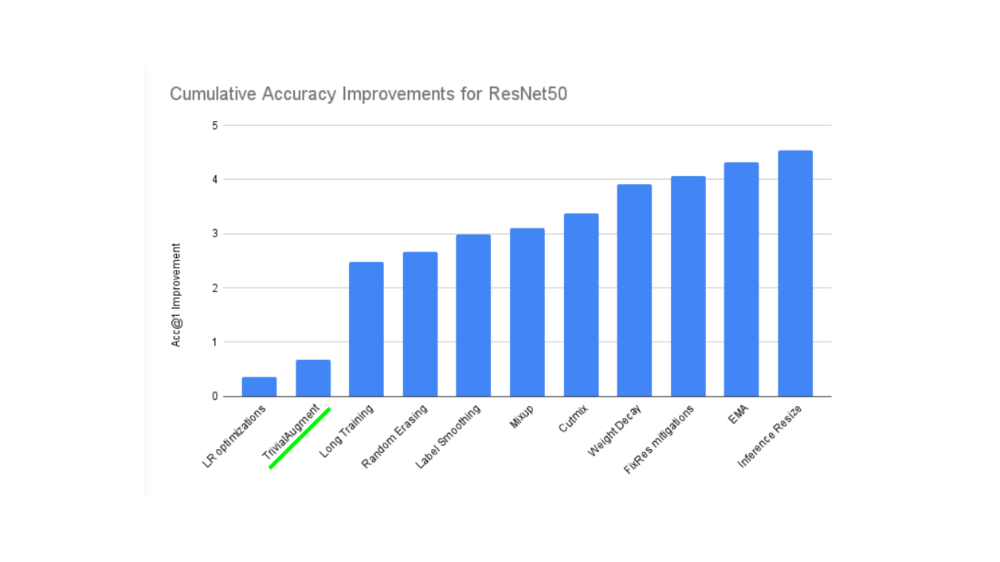
TrivialAugment 是最近对各种 PyTorch 视觉模型进行最先进训练升级的成分之一。
我们何不自己测试一下呢?
在 transforms.TrivialAugmentWide() 中需要注意的主要参数是 num_magnitude_bins=31。
它定义了一个强度值将选择多大的范围来应用某个变换,0 表示没有范围,31 表示最大范围(最高强度的高概率)。
我们可以将 transforms.TrivialAugmentWide() 合并到 transforms.Compose() 中。
from torchvision import transforms
train_transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.TrivialAugmentWide(num_magnitude_bins=31), # how intense
transforms.ToTensor() # use ToTensor() last to get everything between 0 & 1
])
# Don't need to perform augmentation on the test data
test_transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor()
])
注意: 通常情况下,你不会对测试集进行数据增强。数据增强的目的是通过人工增加训练集的多样性,以便更好地预测测试集。
然而,你需要确保测试集图像被转换为张量。我们还将测试图像的大小调整为与训练图像相同,不过,如果有必要,推理可以在不同大小的图像上进行(尽管这可能会影响性能)。
很好,现在我们有了一个包含数据增强的训练变换和一个不包含数据增强的测试变换。
让我们来测试一下数据增强的效果吧!
# Get all image paths
image_path_list = list(image_path.glob("*/*/*.jpg"))
# Plot random images
plot_transformed_images(
image_paths=image_path_list,
transform=train_transforms,
n=3,
seed=None
)



尝试多次运行上面的单元格,观察原始图像在变换过程中是如何变化的。
7. 模型0:无数据增强的TinyVGG¶
好了,我们已经了解了如何将文件夹中的图像数据转换为经过变换的张量。
现在,让我们构建一个计算机视觉模型,看看我们是否能够分类出图像是否为披萨、牛排或寿司。
首先,我们将从一个简单的变换开始,仅将图像大小调整为 (64, 64) 并将其转换为张量。
7.1 为模型0创建转换和加载数据¶
# Create simple transform
simple_transform = transforms.Compose([
transforms.Resize((64, 64)),
transforms.ToTensor(),
])
很好,现在我们有了一个简单的转换,接下来让我们:
- 加载数据,将我们的训练和测试文件夹首先转换为
Dataset,使用torchvision.datasets.ImageFolder() - 然后转换为
DataLoader,使用torch.utils.data.DataLoader()。- 我们将设置
batch_size=32,并将num_workers设置为机器上的 CPU 数量(这取决于你使用的机器)。
- 我们将设置
# 1. Load and transform data
from torchvision import datasets
train_data_simple = datasets.ImageFolder(root=train_dir, transform=simple_transform)
test_data_simple = datasets.ImageFolder(root=test_dir, transform=simple_transform)
# 2. Turn data into DataLoaders
import os
from torch.utils.data import DataLoader
# Setup batch size and number of workers
BATCH_SIZE = 32
NUM_WORKERS = os.cpu_count()
print(f"Creating DataLoader's with batch size {BATCH_SIZE} and {NUM_WORKERS} workers.")
# Create DataLoader's
train_dataloader_simple = DataLoader(train_data_simple,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=NUM_WORKERS)
test_dataloader_simple = DataLoader(test_data_simple,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=NUM_WORKERS)
train_dataloader_simple, test_dataloader_simple
Creating DataLoader's with batch size 32 and 16 workers.
(<torch.utils.data.dataloader.DataLoader at 0x7f5460ad2f70>, <torch.utils.data.dataloader.DataLoader at 0x7f5460ad23d0>)
DataLoader 创建好了!
接下来我们构建一个模型。
7.2 创建 TinyVGG 模型类¶
在笔记本 03中,我们使用了来自CNN Explainer 网站的 TinyVGG 模型。
让我们重新创建相同的模型,只不过这次我们将使用彩色图像而不是灰度图像(对于 RGB 像素,in_channels=3 而不是 in_channels=1)。
class TinyVGG(nn.Module):
"""
Model architecture copying TinyVGG from:
https://poloclub.github.io/cnn-explainer/
"""
def __init__(self, input_shape: int, hidden_units: int, output_shape: int) -> None:
super().__init__()
self.conv_block_1 = nn.Sequential(
nn.Conv2d(in_channels=input_shape,
out_channels=hidden_units,
kernel_size=3, # how big is the square that's going over the image?
stride=1, # default
padding=1), # options = "valid" (no padding) or "same" (output has same shape as input) or int for specific number
nn.ReLU(),
nn.Conv2d(in_channels=hidden_units,
out_channels=hidden_units,
kernel_size=3,
stride=1,
padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,
stride=2) # default stride value is same as kernel_size
)
self.conv_block_2 = nn.Sequential(
nn.Conv2d(hidden_units, hidden_units, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(hidden_units, hidden_units, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.classifier = nn.Sequential(
nn.Flatten(),
# Where did this in_features shape come from?
# It's because each layer of our network compresses and changes the shape of our inputs data.
nn.Linear(in_features=hidden_units*16*16,
out_features=output_shape)
)
def forward(self, x: torch.Tensor):
x = self.conv_block_1(x)
# print(x.shape)
x = self.conv_block_2(x)
# print(x.shape)
x = self.classifier(x)
# print(x.shape)
return x
# return self.classifier(self.conv_block_2(self.conv_block_1(x))) # <- leverage the benefits of operator fusion
torch.manual_seed(42)
model_0 = TinyVGG(input_shape=3, # number of color channels (3 for RGB)
hidden_units=10,
output_shape=len(train_data.classes)).to(device)
model_0
TinyVGG(
(conv_block_1): Sequential(
(0): Conv2d(3, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(10, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(conv_block_2): Sequential(
(0): Conv2d(10, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(10, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): Linear(in_features=2560, out_features=3, bias=True)
)
)
注意: 在 GPU 上加速深度学习模型计算的方法之一是利用 算子融合。
这意味着在我们上述模型的
forward()方法中,我们不是每次调用一个层块并重新赋值x,而是连续调用每个块(参见上述模型中forward()方法的最后一行作为示例)。这样可以节省重新赋值
x(内存密集型)所花费的时间,并专注于仅对x进行计算。更多加速机器学习模型的方法,请参阅 Horace He 的文章 Making Deep Learning Go Brrrr From First Principles。
现在这是一个看起来很棒的模型!
我们何不通过在单张图像上进行前向传播来测试一下呢?
7.3 对单张图像进行前向传播(测试模型)¶
测试模型的一个好方法是针对单个数据样本进行前向传播。
这也是测试我们不同层的输入和输出形状的便捷方法。
要对单张图像进行前向传播,我们可以:
- 从
DataLoader中获取一批图像和标签。 - 从批次中获取一张图像,并使用
unsqueeze()方法将其扩展为具有批量大小1的图像(以便其形状适合模型)。 - 对单张图像进行推理(确保将图像发送到目标
device)。 - 打印出发生的情况,并使用
torch.softmax()将模型的原始输出 logits 转换为预测概率(因为我们处理的是多类数据),然后使用torch.argmax()将预测概率转换为预测标签。
# 1. Get a batch of images and labels from the DataLoader
img_batch, label_batch = next(iter(train_dataloader_simple))
# 2. Get a single image from the batch and unsqueeze the image so its shape fits the model
img_single, label_single = img_batch[0].unsqueeze(dim=0), label_batch[0]
print(f"Single image shape: {img_single.shape}\n")
# 3. Perform a forward pass on a single image
model_0.eval()
with torch.inference_mode():
pred = model_0(img_single.to(device))
# 4. Print out what's happening and convert model logits -> pred probs -> pred label
print(f"Output logits:\n{pred}\n")
print(f"Output prediction probabilities:\n{torch.softmax(pred, dim=1)}\n")
print(f"Output prediction label:\n{torch.argmax(torch.softmax(pred, dim=1), dim=1)}\n")
print(f"Actual label:\n{label_single}")
Single image shape: torch.Size([1, 3, 64, 64]) Output logits: tensor([[0.0578, 0.0634, 0.0352]], device='cuda:0') Output prediction probabilities: tensor([[0.3352, 0.3371, 0.3277]], device='cuda:0') Output prediction label: tensor([1], device='cuda:0') Actual label: 2
太好了,看来我们的模型输出的结果和我们预期的一致。
你可以多次运行上面的单元格,每次都会对不同的图像进行预测。
你可能会注意到,预测结果往往是不正确的。
这是正常的,因为模型还没有经过训练,它实际上是使用随机权重进行猜测。
# Install torchinfo if it's not available, import it if it is
try:
import torchinfo
except:
!pip install torchinfo
import torchinfo
from torchinfo import summary
summary(model_0, input_size=[1, 3, 64, 64]) # do a test pass through of an example input size
========================================================================================== Layer (type:depth-idx) Output Shape Param # ========================================================================================== TinyVGG [1, 3] -- ├─Sequential: 1-1 [1, 10, 32, 32] -- │ └─Conv2d: 2-1 [1, 10, 64, 64] 280 │ └─ReLU: 2-2 [1, 10, 64, 64] -- │ └─Conv2d: 2-3 [1, 10, 64, 64] 910 │ └─ReLU: 2-4 [1, 10, 64, 64] -- │ └─MaxPool2d: 2-5 [1, 10, 32, 32] -- ├─Sequential: 1-2 [1, 10, 16, 16] -- │ └─Conv2d: 2-6 [1, 10, 32, 32] 910 │ └─ReLU: 2-7 [1, 10, 32, 32] -- │ └─Conv2d: 2-8 [1, 10, 32, 32] 910 │ └─ReLU: 2-9 [1, 10, 32, 32] -- │ └─MaxPool2d: 2-10 [1, 10, 16, 16] -- ├─Sequential: 1-3 [1, 3] -- │ └─Flatten: 2-11 [1, 2560] -- │ └─Linear: 2-12 [1, 3] 7,683 ========================================================================================== Total params: 10,693 Trainable params: 10,693 Non-trainable params: 0 Total mult-adds (M): 6.75 ========================================================================================== Input size (MB): 0.05 Forward/backward pass size (MB): 0.82 Params size (MB): 0.04 Estimated Total Size (MB): 0.91 ==========================================================================================
太棒了!
torchinfo.summary() 的输出为我们提供了关于模型的许多信息。
例如 Total params,即模型中的参数总数,以及 Estimated Total Size (MB),即模型的估计总大小。
你还可以看到数据在以某个 input_size 输入模型时,输入和输出形状的变化。
目前,我们的参数数量和模型总大小都很低。
这是因为我们从一个较小的模型开始。
如果以后需要增加模型的大小,我们可以这样做。
7.5 创建训练与测试循环函数¶
我们已经有了数据,也构建了模型。
现在,让我们创建一些训练和测试循环函数,以便在训练数据上训练模型,并在测试数据上评估模型。
为了确保我们能够重复使用这些训练和测试循环,我们将它们函数化。
具体来说,我们将创建三个函数:
train_step()- 接受一个模型、一个DataLoader、一个损失函数和一个优化器,并在DataLoader上训练模型。test_step()- 接受一个模型、一个DataLoader和一个损失函数,并在DataLoader上评估模型。train()- 执行 1 和 2,一起进行给定数量的 epoch,并返回一个结果字典。
注意: 我们在 notebook 01 中介绍了 PyTorch 优化循环的步骤,以及 非官方的 PyTorch 优化循环歌曲,并且在 notebook 03 中构建了类似的函数。
让我们从构建 train_step() 开始。
由于我们在 DataLoader 中处理批次数据,我们将在训练过程中累积模型的损失和准确度值(通过为每个批次累加它们),然后在最后调整它们后再返回。
def train_step(model: torch.nn.Module,
dataloader: torch.utils.data.DataLoader,
loss_fn: torch.nn.Module,
optimizer: torch.optim.Optimizer):
# Put model in train mode
model.train()
# Setup train loss and train accuracy values
train_loss, train_acc = 0, 0
# Loop through data loader data batches
for batch, (X, y) in enumerate(dataloader):
# Send data to target device
X, y = X.to(device), y.to(device)
# 1. Forward pass
y_pred = model(X)
# 2. Calculate and accumulate loss
loss = loss_fn(y_pred, y)
train_loss += loss.item()
# 3. Optimizer zero grad
optimizer.zero_grad()
# 4. Loss backward
loss.backward()
# 5. Optimizer step
optimizer.step()
# Calculate and accumulate accuracy metric across all batches
y_pred_class = torch.argmax(torch.softmax(y_pred, dim=1), dim=1)
train_acc += (y_pred_class == y).sum().item()/len(y_pred)
# Adjust metrics to get average loss and accuracy per batch
train_loss = train_loss / len(dataloader)
train_acc = train_acc / len(dataloader)
return train_loss, train_acc
哇哦!train_step() 函数完成了。
接下来让我们为 test_step() 函数做同样的事情。
这里的主要区别在于 test_step() 不会接收优化器,因此不会执行梯度下降。
但由于我们将进行推理,我们会确保开启 torch.inference_mode() 上下文管理器来进行预测。
def test_step(model: torch.nn.Module,
dataloader: torch.utils.data.DataLoader,
loss_fn: torch.nn.Module):
# Put model in eval mode
model.eval()
# Setup test loss and test accuracy values
test_loss, test_acc = 0, 0
# Turn on inference context manager
with torch.inference_mode():
# Loop through DataLoader batches
for batch, (X, y) in enumerate(dataloader):
# Send data to target device
X, y = X.to(device), y.to(device)
# 1. Forward pass
test_pred_logits = model(X)
# 2. Calculate and accumulate loss
loss = loss_fn(test_pred_logits, y)
test_loss += loss.item()
# Calculate and accumulate accuracy
test_pred_labels = test_pred_logits.argmax(dim=1)
test_acc += ((test_pred_labels == y).sum().item()/len(test_pred_labels))
# Adjust metrics to get average loss and accuracy per batch
test_loss = test_loss / len(dataloader)
test_acc = test_acc / len(dataloader)
return test_loss, test_acc
太棒了!
7.6 创建一个 train() 函数来组合 train_step() 和 test_step()¶
现在我们需要一种方法将 train_step() 和 test_step() 函数结合起来。
为此,我们将它们打包在一个 train() 函数中。
这个函数将训练模型并对其进行评估。
具体来说,它将:
- 接受一个模型、用于训练和测试集的
DataLoader、一个优化器、一个损失函数以及每个训练和测试步骤要执行的周期数。 - 创建一个空的 results 字典,用于存储
train_loss、train_acc、test_loss和test_acc值(我们可以在训练过程中填充这个字典)。 - 对一定数量的周期循环执行训练和测试步骤函数。
- 在每个周期结束时打印出当前的进展情况。
- 使用每个周期的更新指标更新空的 results 字典。
- 返回填充好的 results 字典。
为了跟踪我们已经经历了多少个周期,让我们从 tqdm.auto 导入 tqdm(tqdm 是 Python 中最流行的进度条库之一,tqdm.auto 会自动决定最适合你的计算环境的进度条类型,例如 Jupyter Notebook 与 Python 脚本)。
from tqdm.auto import tqdm
# 1. Take in various parameters required for training and test steps
def train(model: torch.nn.Module,
train_dataloader: torch.utils.data.DataLoader,
test_dataloader: torch.utils.data.DataLoader,
optimizer: torch.optim.Optimizer,
loss_fn: torch.nn.Module = nn.CrossEntropyLoss(),
epochs: int = 5):
# 2. Create empty results dictionary
results = {"train_loss": [],
"train_acc": [],
"test_loss": [],
"test_acc": []
}
# 3. Loop through training and testing steps for a number of epochs
for epoch in tqdm(range(epochs)):
train_loss, train_acc = train_step(model=model,
dataloader=train_dataloader,
loss_fn=loss_fn,
optimizer=optimizer)
test_loss, test_acc = test_step(model=model,
dataloader=test_dataloader,
loss_fn=loss_fn)
# 4. Print out what's happening
print(
f"Epoch: {epoch+1} | "
f"train_loss: {train_loss:.4f} | "
f"train_acc: {train_acc:.4f} | "
f"test_loss: {test_loss:.4f} | "
f"test_acc: {test_acc:.4f}"
)
# 5. Update results dictionary
results["train_loss"].append(train_loss)
results["train_acc"].append(train_acc)
results["test_loss"].append(test_loss)
results["test_acc"].append(test_acc)
# 6. Return the filled results at the end of the epochs
return results
7.7 训练和评估模型0¶
好了,好了,好了,我们已经准备好了所有需要的成分来训练和评估我们的模型。
现在是时候将我们的 TinyVGG 模型、DataLoader 和 train() 函数结合起来,看看我们是否能构建一个能够区分披萨、牛排和寿司的模型!
让我们重新创建 model_0(我们不需要这样做,但为了完整性我们会这样做),然后调用我们的 train() 函数并传入必要的参数。
为了保持实验的快速,我们将训练我们的模型 5 个周期(尽管你可以根据需要增加这个数字)。
至于 优化器 和 损失函数,我们将使用 torch.nn.CrossEntropyLoss()(因为我们处理的是多类别分类数据)和 torch.optim.Adam(),学习率为 1e-3。
为了查看训练时间,我们将导入 Python 的 timeit.default_timer() 方法来计算训练时间。
# Set random seeds
torch.manual_seed(42)
torch.cuda.manual_seed(42)
# Set number of epochs
NUM_EPOCHS = 5
# Recreate an instance of TinyVGG
model_0 = TinyVGG(input_shape=3, # number of color channels (3 for RGB)
hidden_units=10,
output_shape=len(train_data.classes)).to(device)
# Setup loss function and optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(params=model_0.parameters(), lr=0.001)
# Start the timer
from timeit import default_timer as timer
start_time = timer()
# Train model_0
model_0_results = train(model=model_0,
train_dataloader=train_dataloader_simple,
test_dataloader=test_dataloader_simple,
optimizer=optimizer,
loss_fn=loss_fn,
epochs=NUM_EPOCHS)
# End the timer and print out how long it took
end_time = timer()
print(f"Total training time: {end_time-start_time:.3f} seconds")
0%| | 0/5 [00:00<?, ?it/s]
Epoch: 1 | train_loss: 1.1078 | train_acc: 0.2578 | test_loss: 1.1360 | test_acc: 0.2604 Epoch: 2 | train_loss: 1.0847 | train_acc: 0.4258 | test_loss: 1.1620 | test_acc: 0.1979 Epoch: 3 | train_loss: 1.1157 | train_acc: 0.2930 | test_loss: 1.1697 | test_acc: 0.1979 Epoch: 4 | train_loss: 1.0956 | train_acc: 0.4141 | test_loss: 1.1384 | test_acc: 0.1979 Epoch: 5 | train_loss: 1.0985 | train_acc: 0.2930 | test_loss: 1.1426 | test_acc: 0.1979 Total training time: 4.935 seconds
嗯...
看起来我们的模型表现相当糟糕。
但目前没关系,我们会继续坚持下去。
有哪些方法可以潜在地改进它呢?
注意: 查看笔记本 02 中的从模型角度改进模型部分,了解改进我们 TinyVGG 模型的想法。
7.8 绘制模型0的损失曲线¶
从我们训练model_0的输出结果来看,它的表现似乎并不理想。
但我们可以通过绘制模型的损失曲线进一步评估它。
损失曲线展示了模型随时间变化的结果。
它们是查看模型在不同数据集(例如训练集和测试集)上表现的一种极好方式。
让我们创建一个函数来绘制model_0_results字典中的值。
# Check the model_0_results keys
model_0_results.keys()
dict_keys(['train_loss', 'train_acc', 'test_loss', 'test_acc'])
我们需要提取每一个键,并将它们转化为图表。
def plot_loss_curves(results: Dict[str, List[float]]):
"""Plots training curves of a results dictionary.
Args:
results (dict): dictionary containing list of values, e.g.
{"train_loss": [...],
"train_acc": [...],
"test_loss": [...],
"test_acc": [...]}
"""
# Get the loss values of the results dictionary (training and test)
loss = results['train_loss']
test_loss = results['test_loss']
# Get the accuracy values of the results dictionary (training and test)
accuracy = results['train_acc']
test_accuracy = results['test_acc']
# Figure out how many epochs there were
epochs = range(len(results['train_loss']))
# Setup a plot
plt.figure(figsize=(15, 7))
# Plot loss
plt.subplot(1, 2, 1)
plt.plot(epochs, loss, label='train_loss')
plt.plot(epochs, test_loss, label='test_loss')
plt.title('Loss')
plt.xlabel('Epochs')
plt.legend()
# Plot accuracy
plt.subplot(1, 2, 2)
plt.plot(epochs, accuracy, label='train_accuracy')
plt.plot(epochs, test_accuracy, label='test_accuracy')
plt.title('Accuracy')
plt.xlabel('Epochs')
plt.legend();
好的,让我们来测试一下 plot_loss_curves() 函数。
plot_loss_curves(model_0_results)

哇哦。
看起来事情一团糟...
但我们多少预料到了这一点,因为我们的模型在训练期间的打印输出结果并没有显示出太多希望。
你可以尝试将模型训练更长时间,看看在更长的时间跨度上绘制损失曲线会发生什么变化。
8. 理想的损失曲线应该是什么样的?¶
观察训练和测试损失曲线是判断模型是否过拟合的好方法。
过拟合模型是指在训练集上的表现(通常有较大差距)优于验证/测试集的模型。
如果你的训练损失远低于测试损失,你的模型就是过拟合。
也就是说,它对训练数据中的模式学习得过于透彻,而这些模式并没有泛化到测试数据中。
另一方面,如果你的训练和测试损失没有你期望的那么低,这就是欠拟合。
理想的训练和测试损失曲线的位置是它们彼此紧密对齐。
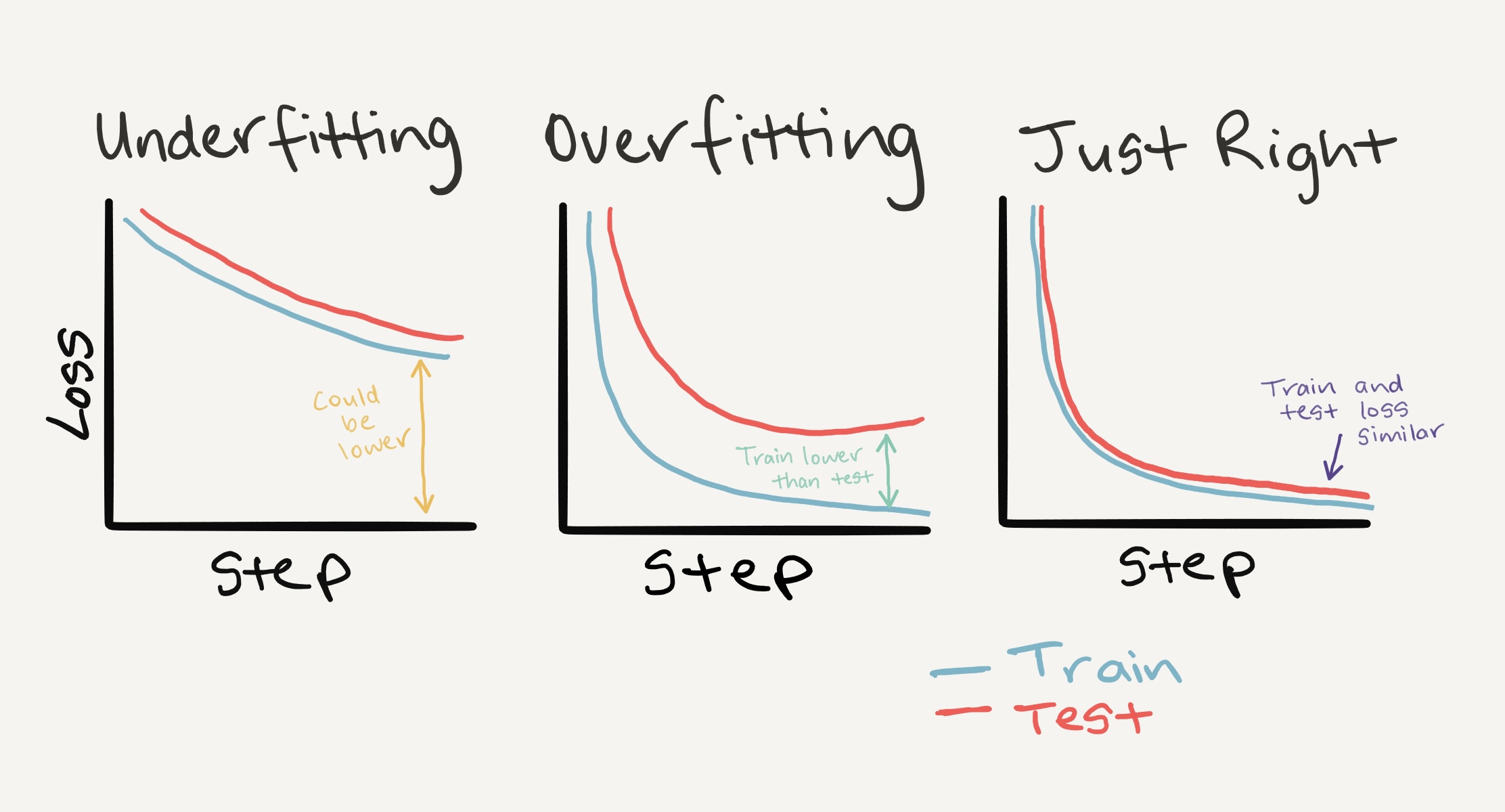
左:如果你的训练和测试损失曲线没有你期望的那么低,这就是欠拟合。中间:当你的测试/验证损失高于训练损失时,这就是过拟合。右:理想的情景是你的训练和测试损失曲线随时间对齐。这意味着你的模型泛化得很好。还有更多组合和损失曲线可能出现的不同情况,更多信息请参见谷歌的解释损失曲线指南。
8.1 如何处理过拟合¶
过拟合的主要问题是模型对训练数据的拟合过于精确,因此你需要使用一些技术来“约束”它。
防止过拟合的常见技术称为正则化。
我喜欢将其视为“使我们的模型更规范”,即能够适应更多类型的数据。
让我们讨论几种防止过拟合的方法。
| 防止过拟合的方法 | 是什么? |
|---|---|
| 获取更多数据 | 拥有更多数据使模型有更多机会学习模式,这些模式可能更适用于新样本。 |
| 简化模型 | 如果当前模型已经过拟合训练数据,那么它可能过于复杂。这意味着它过于精确地学习了数据的模式,无法很好地泛化到未见过的数据。简化模型的一种方法是通过减少层数或减少每层中的隐藏单元数量。 |
| 使用数据增强 | 数据增强通过操纵训练数据,使模型更难以学习,因为它人为地增加了数据的多样性。如果模型能够学习增强数据中的模式,那么它可能更好地泛化到未见过的数据。 |
| 使用迁移学习 | 迁移学习利用一个模型学到的模式(也称为预训练权重)作为自己任务的基础。在我们的例子中,可以使用一个在大范围图像上预训练的计算机视觉模型,然后稍微调整使其更适合食品图像。 |
| 使用 dropout 层 | Dropout 层随机移除神经网络中隐藏层之间的连接,有效地简化模型,同时也使剩余连接更好。更多信息请参见 torch.nn.Dropout()。 |
| 使用学习率衰减 | 这里的想法是随着模型训练逐渐降低学习率。这类似于伸手去拿沙发后面的硬币。你越接近,你的步子就越小。学习率也是如此,越接近收敛,你希望权重更新越小。 |
| 使用早停法 | 早停法在模型开始过拟合之前停止训练。例如,假设模型的损失在过去10个周期内没有减少(这个数字是任意的),你可能希望在此停止模型训练,并使用损失最低的模型权重(10个周期之前)。 |
还有更多处理过拟合的方法,但这些是一些主要的方法。
随着你开始构建越来越多的深度模型,你会发现由于深度学习在数据中学习模式的能力非常强,处理过拟合是深度学习的主要问题之一。
8.2 如何处理欠拟合¶
当一个模型欠拟合时,它被认为在训练集和测试集上的预测能力较差。
本质上,欠拟合的模型无法将损失值降低到期望的水平。
现在,观察我们当前的损失曲线,我认为我们的 TinyVGG 模型 model_0 欠拟合了数据。
处理欠拟合的主要思路是提高模型的预测能力。
有几种方法可以做到这一点。
| 防止欠拟合的方法 | 是什么? |
|---|---|
| 增加模型的层数/单元数 | 如果模型欠拟合,可能是因为它没有足够的容量来学习数据所需的模式/权重/表示以进行预测。增加隐藏层/单元数是提高模型预测能力的一种方法。 |
| 调整学习率 | 也许模型的初始学习率太高,每次迭代更新权重过多,反而没有学到任何东西。在这种情况下,可以降低学习率并观察效果。 |
| 使用迁移学习 | 迁移学习能够防止过拟合和欠拟合。它涉及使用先前工作模型的模式,并将其调整到自己的问题上。 |
| 延长训练时间 | 有时候模型只是需要更多时间来学习数据的表示。如果在小规模实验中发现模型没有学到任何东西,可能让它训练更多迭代会提高性能。 |
| 减少正则化 | 也许模型欠拟合是因为你试图防止过拟合过度。减少正则化技术可以帮助模型更好地拟合数据。 |
8.3 过拟合与欠拟合之间的平衡¶
上述方法都不是万能的,也就是说,它们并不总是有效。
防止过拟合和欠拟合可能是机器学习研究中最活跃的领域。
因为每个人都希望他们的模型拟合得更好(减少欠拟合),但又不能好到无法很好地泛化并在现实世界中表现(减少过拟合)。
过拟合和欠拟合之间有一条微妙的界限。
因为过多的任何一个都可能导致另一个。
迁移学习可能是处理你自己问题中过拟合和欠拟合的最强大技术之一。
与其手工设计不同的过拟合和欠拟合技术,迁移学习使你能够采用一个已经在类似你的问题空间中有效工作的模型(比如来自paperswithcode.com/sota或Hugging Face 模型),并将其应用于你自己的数据集。
我们将在后面的笔记本中看到迁移学习的强大之处。
# Create training transform with TrivialAugment
train_transform_trivial_augment = transforms.Compose([
transforms.Resize((64, 64)),
transforms.TrivialAugmentWide(num_magnitude_bins=31),
transforms.ToTensor()
])
# Create testing transform (no data augmentation)
test_transform = transforms.Compose([
transforms.Resize((64, 64)),
transforms.ToTensor()
])
太棒了!
现在,让我们使用 torchvision.datasets.ImageFolder() 将图像转换为 Dataset,然后使用 torch.utils.data.DataLoader() 将其转换为 DataLoader。
9.2 创建训练和测试的 Dataset 和 DataLoader¶
我们将确保训练 Dataset 使用 train_transform_trivial_augment,而测试 Dataset 使用 test_transform。
# Turn image folders into Datasets
train_data_augmented = datasets.ImageFolder(train_dir, transform=train_transform_trivial_augment)
test_data_simple = datasets.ImageFolder(test_dir, transform=test_transform)
train_data_augmented, test_data_simple
(Dataset ImageFolder
Number of datapoints: 225
Root location: data/pizza_steak_sushi/train
StandardTransform
Transform: Compose(
Resize(size=(64, 64), interpolation=bilinear, max_size=None, antialias=None)
TrivialAugmentWide(num_magnitude_bins=31, interpolation=InterpolationMode.NEAREST, fill=None)
ToTensor()
),
Dataset ImageFolder
Number of datapoints: 75
Root location: data/pizza_steak_sushi/test
StandardTransform
Transform: Compose(
Resize(size=(64, 64), interpolation=bilinear, max_size=None, antialias=None)
ToTensor()
))
我们将创建 DataLoader,其 batch_size 设为 32,并将 num_workers 设置为机器上可用的 CPU 数量(我们可以使用 Python 的 os.cpu_count() 来获取这个值)。
# Turn Datasets into DataLoader's
import os
BATCH_SIZE = 32
NUM_WORKERS = os.cpu_count()
torch.manual_seed(42)
train_dataloader_augmented = DataLoader(train_data_augmented,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=NUM_WORKERS)
test_dataloader_simple = DataLoader(test_data_simple,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=NUM_WORKERS)
train_dataloader_augmented, test_dataloader
(<torch.utils.data.dataloader.DataLoader at 0x7f53c6d64040>, <torch.utils.data.dataloader.DataLoader at 0x7f53c0b9de50>)
# Create model_1 and send it to the target device
torch.manual_seed(42)
model_1 = TinyVGG(
input_shape=3,
hidden_units=10,
output_shape=len(train_data_augmented.classes)).to(device)
model_1
TinyVGG(
(conv_block_1): Sequential(
(0): Conv2d(3, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(10, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(conv_block_2): Sequential(
(0): Conv2d(10, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(10, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): Linear(in_features=2560, out_features=3, bias=True)
)
)
模型准备就绪!
开始训练!
既然我们已经有了训练循环的函数(train_step())和测试循环的函数(test_step()),以及将它们组合在一起的train()函数,让我们重用这些函数。
我们将使用与model_0相同的设置,仅在train_dataloader参数上有所不同:
- 训练 5 个周期。
- 在
train()中使用train_dataloader=train_dataloader_augmented作为训练数据。 - 使用
torch.nn.CrossEntropyLoss()作为损失函数(因为我们处理的是多类别分类问题)。 - 使用
torch.optim.Adam(),学习率lr=0.001作为优化器。
# Set random seeds
torch.manual_seed(42)
torch.cuda.manual_seed(42)
# Set number of epochs
NUM_EPOCHS = 5
# Setup loss function and optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(params=model_1.parameters(), lr=0.001)
# Start the timer
from timeit import default_timer as timer
start_time = timer()
# Train model_1
model_1_results = train(model=model_1,
train_dataloader=train_dataloader_augmented,
test_dataloader=test_dataloader_simple,
optimizer=optimizer,
loss_fn=loss_fn,
epochs=NUM_EPOCHS)
# End the timer and print out how long it took
end_time = timer()
print(f"Total training time: {end_time-start_time:.3f} seconds")
0%| | 0/5 [00:00<?, ?it/s]
Epoch: 1 | train_loss: 1.1074 | train_acc: 0.2500 | test_loss: 1.1058 | test_acc: 0.2604 Epoch: 2 | train_loss: 1.0791 | train_acc: 0.4258 | test_loss: 1.1382 | test_acc: 0.2604 Epoch: 3 | train_loss: 1.0803 | train_acc: 0.4258 | test_loss: 1.1685 | test_acc: 0.2604 Epoch: 4 | train_loss: 1.1285 | train_acc: 0.3047 | test_loss: 1.1623 | test_acc: 0.2604 Epoch: 5 | train_loss: 1.0880 | train_acc: 0.4258 | test_loss: 1.1472 | test_acc: 0.2604 Total training time: 4.924 seconds
嗯...
看起来我们的模型表现又不太理想。
让我们来看看它的损失曲线。
9.4 绘制模型1的损失曲线¶
由于我们已经将 model_1 的结果保存在一个名为 model_1_results 的结果字典中,我们可以使用 plot_loss_curves() 来绘制它们。
plot_loss_curves(model_1_results)

哇...
这些看起来也不太好...
我们的模型是欠拟合还是过拟合?
还是两者都有?
理想情况下,我们希望它的准确性更高,损失更低,对吧?
你可以尝试哪些方法来实现这些目标呢?
import pandas as pd
model_0_df = pd.DataFrame(model_0_results)
model_1_df = pd.DataFrame(model_1_results)
model_0_df
| train_loss | train_acc | test_loss | test_acc | |
|---|---|---|---|---|
| 0 | 1.107833 | 0.257812 | 1.136041 | 0.260417 |
| 1 | 1.084713 | 0.425781 | 1.162014 | 0.197917 |
| 2 | 1.115697 | 0.292969 | 1.169704 | 0.197917 |
| 3 | 1.095564 | 0.414062 | 1.138373 | 0.197917 |
| 4 | 1.098520 | 0.292969 | 1.142631 | 0.197917 |
现在我们可以使用 matplotlib 编写一些绘图代码,将 model_0 和 model_1 的结果一起可视化。
# Setup a plot
plt.figure(figsize=(15, 10))
# Get number of epochs
epochs = range(len(model_0_df))
# Plot train loss
plt.subplot(2, 2, 1)
plt.plot(epochs, model_0_df["train_loss"], label="Model 0")
plt.plot(epochs, model_1_df["train_loss"], label="Model 1")
plt.title("Train Loss")
plt.xlabel("Epochs")
plt.legend()
# Plot test loss
plt.subplot(2, 2, 2)
plt.plot(epochs, model_0_df["test_loss"], label="Model 0")
plt.plot(epochs, model_1_df["test_loss"], label="Model 1")
plt.title("Test Loss")
plt.xlabel("Epochs")
plt.legend()
# Plot train accuracy
plt.subplot(2, 2, 3)
plt.plot(epochs, model_0_df["train_acc"], label="Model 0")
plt.plot(epochs, model_1_df["train_acc"], label="Model 1")
plt.title("Train Accuracy")
plt.xlabel("Epochs")
plt.legend()
# Plot test accuracy
plt.subplot(2, 2, 4)
plt.plot(epochs, model_0_df["test_acc"], label="Model 0")
plt.plot(epochs, model_1_df["test_acc"], label="Model 1")
plt.title("Test Accuracy")
plt.xlabel("Epochs")
plt.legend();

看起来我们的两个模型表现都不太理想,且波动较大(指标急剧上升和下降)。
如果你构建了 model_2,为了尝试提高性能,你可能会考虑以下几个方面:
数据预处理:
- 检查数据是否存在缺失值或异常值,并进行适当的处理。
- 标准化或归一化数据,以确保所有特征在同一尺度上。
- 考虑使用数据增强技术,尤其是对于图像或文本数据。
特征工程:
- 探索更多的特征组合或变换,以提取更有信息量的特征。
- 使用特征选择方法,如相关性分析、递归特征消除(RFE)等,以减少冗余特征。
模型选择与调优:
- 尝试不同的模型架构,如增加网络层数、改变激活函数等。
- 使用交叉验证来评估模型的泛化能力。
- 应用超参数调优技术,如网格搜索(Grid Search)或随机搜索(Random Search),以找到最佳参数组合。
正则化:
- 引入正则化项(如L1、L2正则化),以防止过拟合。
- 尝试使用 dropout 或 batch normalization 等技术。
集成学习:
- 考虑使用集成方法,如 bagging、boosting 或 stacking,以提高模型的稳定性和性能。
学习率调整:
- 使用学习率衰减策略,如余弦退火(Cosine Annealing)或学习率调度器(Learning Rate Scheduler)。
评估与监控:
- 定期检查训练过程中的指标变化,确保模型在正确的方向上优化。
- 使用可视化工具,如 TensorBoard,来监控训练过程和模型表现。
通过这些方法,你可以系统地改进 model_2,以期望获得更好的性能。
11. 对自定义图像进行预测¶
如果你已经在一个特定数据集上训练了一个模型,你很可能会希望在自己的自定义数据上进行预测。
在我们的例子中,由于我们已经在披萨、牛排和寿司图像上训练了一个模型,我们如何使用这个模型来对我们自己的一张图像进行预测呢?
为此,我们可以加载一张图像,然后以一种与模型训练数据类型相匹配的方式对其进行预处理。
换句话说,我们需要将我们自己的自定义图像转换为张量,并确保它在传递给模型之前具有正确的数据类型。
让我们首先下载一张自定义图像。
由于我们的模型预测图像是否包含披萨、牛排或寿司,让我们下载一张我爸爸对一张大披萨竖起两个大拇指的照片,来自《使用 PyTorch 进行深度学习》GitHub 仓库。
{kind=link}
我们使用 Python 的 requests 模块下载图像。
注意: 如果你使用的是 Google Colab,你也可以通过左侧菜单 -> 文件 -> 上传到会话存储来上传一张图像到当前会话。不过要注意,当你的 Google Colab 会话结束时,这张图像会被删除。
# Download custom image
import requests
# Setup custom image path
custom_image_path = data_path / "04-pizza-dad.jpeg"
# Download the image if it doesn't already exist
if not custom_image_path.is_file():
with open(custom_image_path, "wb") as f:
# When downloading from GitHub, need to use the "raw" file link
request = requests.get("https://raw.githubusercontent.com/mrdbourke/pytorch-deep-learning/main/images/04-pizza-dad.jpeg")
print(f"Downloading {custom_image_path}...")
f.write(request.content)
else:
print(f"{custom_image_path} already exists, skipping download.")
data/04-pizza-dad.jpeg already exists, skipping download.
11.1 使用 PyTorch 加载自定义图像¶
太棒了!
看起来我们已经下载并准备好了一张自定义图像,路径为 data/04-pizza-dad.jpeg。
是时候加载它了。
PyTorch 的 torchvision 提供了多种输入和输出(简称“IO”或“io”)方法,用于读取和写入图像和视频,具体可在 torchvision.io 中找到。
由于我们需要加载图像,我们将使用 torchvision.io.read_image()。
此方法将读取 JPEG 或 PNG 图像,并将其转换为三维的 RGB 或灰度 torch.Tensor,其值的数据类型为 uint8,范围在 [0, 255] 之间。
让我们试试看。
import torchvision
# Read in custom image
custom_image_uint8 = torchvision.io.read_image(str(custom_image_path))
# Print out image data
print(f"Custom image tensor:\n{custom_image_uint8}\n")
print(f"Custom image shape: {custom_image_uint8.shape}\n")
print(f"Custom image dtype: {custom_image_uint8.dtype}")
Custom image tensor:
tensor([[[154, 173, 181, ..., 21, 18, 14],
[146, 165, 181, ..., 21, 18, 15],
[124, 146, 172, ..., 18, 17, 15],
...,
[ 72, 59, 45, ..., 152, 150, 148],
[ 64, 55, 41, ..., 150, 147, 144],
[ 64, 60, 46, ..., 149, 146, 143]],
[[171, 190, 193, ..., 22, 19, 15],
[163, 182, 193, ..., 22, 19, 16],
[141, 163, 184, ..., 19, 18, 16],
...,
[ 55, 42, 28, ..., 107, 104, 103],
[ 47, 38, 24, ..., 108, 104, 102],
[ 47, 43, 29, ..., 107, 104, 101]],
[[119, 138, 147, ..., 17, 14, 10],
[111, 130, 145, ..., 17, 14, 11],
[ 87, 111, 136, ..., 14, 13, 11],
...,
[ 35, 22, 8, ..., 52, 52, 48],
[ 27, 18, 4, ..., 50, 49, 44],
[ 27, 23, 9, ..., 49, 46, 43]]], dtype=torch.uint8)
Custom image shape: torch.Size([3, 4032, 3024])
Custom image dtype: torch.uint8
很好!看起来我们的图像是以张量格式存在的,但是这种图像格式与我们的模型兼容吗?
我们的 custom_image 张量的数据类型是 torch.uint8,其值在 [0, 255] 之间。
但我们的模型接受的数据类型是 torch.float32,并且值在 [0, 1] 之间。
因此,在我们使用自定义图像之前,我们需要将其转换为模型训练数据相同的格式。
如果我们不这样做,模型将会报错。
# Try to make a prediction on image in uint8 format (this will error)
model_1.eval()
with torch.inference_mode():
model_1(custom_image_uint8.to(device))
--------------------------------------------------------------------------- RuntimeError Traceback (most recent call last) Input In [61], in <cell line: 3>() 2 model_1.eval() 3 with torch.inference_mode(): ----> 4 model_1(custom_image_uint8.to(device)) File ~/code/pytorch/env/lib/python3.8/site-packages/torch/nn/modules/module.py:1130, in Module._call_impl(self, *input, **kwargs) 1126 # If we don't have any hooks, we want to skip the rest of the logic in 1127 # this function, and just call forward. 1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks 1129 or _global_forward_hooks or _global_forward_pre_hooks): -> 1130 return forward_call(*input, **kwargs) 1131 # Do not call functions when jit is used 1132 full_backward_hooks, non_full_backward_hooks = [], [] Input In [41], in TinyVGG.forward(self, x) 39 def forward(self, x: torch.Tensor): ---> 40 x = self.conv_block_1(x) 41 # print(x.shape) 42 x = self.conv_block_2(x) File ~/code/pytorch/env/lib/python3.8/site-packages/torch/nn/modules/module.py:1130, in Module._call_impl(self, *input, **kwargs) 1126 # If we don't have any hooks, we want to skip the rest of the logic in 1127 # this function, and just call forward. 1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks 1129 or _global_forward_hooks or _global_forward_pre_hooks): -> 1130 return forward_call(*input, **kwargs) 1131 # Do not call functions when jit is used 1132 full_backward_hooks, non_full_backward_hooks = [], [] File ~/code/pytorch/env/lib/python3.8/site-packages/torch/nn/modules/container.py:139, in Sequential.forward(self, input) 137 def forward(self, input): 138 for module in self: --> 139 input = module(input) 140 return input File ~/code/pytorch/env/lib/python3.8/site-packages/torch/nn/modules/module.py:1130, in Module._call_impl(self, *input, **kwargs) 1126 # If we don't have any hooks, we want to skip the rest of the logic in 1127 # this function, and just call forward. 1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks 1129 or _global_forward_hooks or _global_forward_pre_hooks): -> 1130 return forward_call(*input, **kwargs) 1131 # Do not call functions when jit is used 1132 full_backward_hooks, non_full_backward_hooks = [], [] File ~/code/pytorch/env/lib/python3.8/site-packages/torch/nn/modules/conv.py:457, in Conv2d.forward(self, input) 456 def forward(self, input: Tensor) -> Tensor: --> 457 return self._conv_forward(input, self.weight, self.bias) File ~/code/pytorch/env/lib/python3.8/site-packages/torch/nn/modules/conv.py:453, in Conv2d._conv_forward(self, input, weight, bias) 449 if self.padding_mode != 'zeros': 450 return F.conv2d(F.pad(input, self._reversed_padding_repeated_twice, mode=self.padding_mode), 451 weight, bias, self.stride, 452 _pair(0), self.dilation, self.groups) --> 453 return F.conv2d(input, weight, bias, self.stride, 454 self.padding, self.dilation, self.groups) RuntimeError: Input type (torch.cuda.ByteTensor) and weight type (torch.cuda.FloatTensor) should be the same
如果我们尝试对与模型训练时数据类型不同的图像进行预测,会遇到如下错误:
RuntimeError: 输入类型 (torch.cuda.ByteTensor) 和权重类型 (torch.cuda.FloatTensor) 应该相同
我们可以通过将自定义图像转换为与模型训练时相同的数据类型(torch.float32)来解决这个问题。
# Load in custom image and convert the tensor values to float32
custom_image = torchvision.io.read_image(str(custom_image_path)).type(torch.float32)
# Divide the image pixel values by 255 to get them between [0, 1]
custom_image = custom_image / 255.
# Print out image data
print(f"Custom image tensor:\n{custom_image}\n")
print(f"Custom image shape: {custom_image.shape}\n")
print(f"Custom image dtype: {custom_image.dtype}")
Custom image tensor:
tensor([[[0.6039, 0.6784, 0.7098, ..., 0.0824, 0.0706, 0.0549],
[0.5725, 0.6471, 0.7098, ..., 0.0824, 0.0706, 0.0588],
[0.4863, 0.5725, 0.6745, ..., 0.0706, 0.0667, 0.0588],
...,
[0.2824, 0.2314, 0.1765, ..., 0.5961, 0.5882, 0.5804],
[0.2510, 0.2157, 0.1608, ..., 0.5882, 0.5765, 0.5647],
[0.2510, 0.2353, 0.1804, ..., 0.5843, 0.5725, 0.5608]],
[[0.6706, 0.7451, 0.7569, ..., 0.0863, 0.0745, 0.0588],
[0.6392, 0.7137, 0.7569, ..., 0.0863, 0.0745, 0.0627],
[0.5529, 0.6392, 0.7216, ..., 0.0745, 0.0706, 0.0627],
...,
[0.2157, 0.1647, 0.1098, ..., 0.4196, 0.4078, 0.4039],
[0.1843, 0.1490, 0.0941, ..., 0.4235, 0.4078, 0.4000],
[0.1843, 0.1686, 0.1137, ..., 0.4196, 0.4078, 0.3961]],
[[0.4667, 0.5412, 0.5765, ..., 0.0667, 0.0549, 0.0392],
[0.4353, 0.5098, 0.5686, ..., 0.0667, 0.0549, 0.0431],
[0.3412, 0.4353, 0.5333, ..., 0.0549, 0.0510, 0.0431],
...,
[0.1373, 0.0863, 0.0314, ..., 0.2039, 0.2039, 0.1882],
[0.1059, 0.0706, 0.0157, ..., 0.1961, 0.1922, 0.1725],
[0.1059, 0.0902, 0.0353, ..., 0.1922, 0.1804, 0.1686]]])
Custom image shape: torch.Size([3, 4032, 3024])
Custom image dtype: torch.float32
11.2 使用训练好的PyTorch模型预测自定义图像¶
太好了,看起来我们的图像数据现在和模型训练时的格式一致了。
除了一个事情...
那就是形状。
我们的模型是在形状为[3, 64, 64]的图像上训练的,而我们的自定义图像当前的形状是[3, 4032, 3024]。
我们如何确保自定义图像的形状与模型训练时的图像形状相同呢?
有没有什么torchvision.transforms可以帮助我们?
在我们回答这个问题之前,让我们用matplotlib绘制图像,确保它看起来没问题。记住,我们需要将维度从CHW转换为HWC以适应matplotlib的要求。
# Plot custom image
plt.imshow(custom_image.permute(1, 2, 0)) # need to permute image dimensions from CHW -> HWC otherwise matplotlib will error
plt.title(f"Image shape: {custom_image.shape}")
plt.axis(False);

两个大拇指!
那么,我们如何让我们的图像与模型训练时使用的图像大小一致呢?
一种方法是使用 torchvision.transforms.Resize()。
让我们构建一个变换管道来实现这一点。
# Create transform pipleine to resize image
custom_image_transform = transforms.Compose([
transforms.Resize((64, 64)),
])
# Transform target image
custom_image_transformed = custom_image_transform(custom_image)
# Print out original shape and new shape
print(f"Original shape: {custom_image.shape}")
print(f"New shape: {custom_image_transformed.shape}")
Original shape: torch.Size([3, 4032, 3024]) New shape: torch.Size([3, 64, 64])
哇哦!
让我们终于在自己的自定义图像上进行预测吧。
model_1.eval()
with torch.inference_mode():
custom_image_pred = model_1(custom_image_transformed)
--------------------------------------------------------------------------- RuntimeError Traceback (most recent call last) Input In [65], in <cell line: 2>() 1 model_1.eval() 2 with torch.inference_mode(): ----> 3 custom_image_pred = model_1(custom_image_transformed) File ~/code/pytorch/env/lib/python3.8/site-packages/torch/nn/modules/module.py:1130, in Module._call_impl(self, *input, **kwargs) 1126 # If we don't have any hooks, we want to skip the rest of the logic in 1127 # this function, and just call forward. 1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks 1129 or _global_forward_hooks or _global_forward_pre_hooks): -> 1130 return forward_call(*input, **kwargs) 1131 # Do not call functions when jit is used 1132 full_backward_hooks, non_full_backward_hooks = [], [] Input In [41], in TinyVGG.forward(self, x) 39 def forward(self, x: torch.Tensor): ---> 40 x = self.conv_block_1(x) 41 # print(x.shape) 42 x = self.conv_block_2(x) File ~/code/pytorch/env/lib/python3.8/site-packages/torch/nn/modules/module.py:1130, in Module._call_impl(self, *input, **kwargs) 1126 # If we don't have any hooks, we want to skip the rest of the logic in 1127 # this function, and just call forward. 1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks 1129 or _global_forward_hooks or _global_forward_pre_hooks): -> 1130 return forward_call(*input, **kwargs) 1131 # Do not call functions when jit is used 1132 full_backward_hooks, non_full_backward_hooks = [], [] File ~/code/pytorch/env/lib/python3.8/site-packages/torch/nn/modules/container.py:139, in Sequential.forward(self, input) 137 def forward(self, input): 138 for module in self: --> 139 input = module(input) 140 return input File ~/code/pytorch/env/lib/python3.8/site-packages/torch/nn/modules/module.py:1130, in Module._call_impl(self, *input, **kwargs) 1126 # If we don't have any hooks, we want to skip the rest of the logic in 1127 # this function, and just call forward. 1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks 1129 or _global_forward_hooks or _global_forward_pre_hooks): -> 1130 return forward_call(*input, **kwargs) 1131 # Do not call functions when jit is used 1132 full_backward_hooks, non_full_backward_hooks = [], [] File ~/code/pytorch/env/lib/python3.8/site-packages/torch/nn/modules/conv.py:457, in Conv2d.forward(self, input) 456 def forward(self, input: Tensor) -> Tensor: --> 457 return self._conv_forward(input, self.weight, self.bias) File ~/code/pytorch/env/lib/python3.8/site-packages/torch/nn/modules/conv.py:453, in Conv2d._conv_forward(self, input, weight, bias) 449 if self.padding_mode != 'zeros': 450 return F.conv2d(F.pad(input, self._reversed_padding_repeated_twice, mode=self.padding_mode), 451 weight, bias, self.stride, 452 _pair(0), self.dilation, self.groups) --> 453 return F.conv2d(input, weight, bias, self.stride, 454 self.padding, self.dilation, self.groups) RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cpu and cuda:0! (when checking argument for argument weight in method wrapper___slow_conv2d_forward)
哦天哪...
尽管我们已经做好了准备,但我们的自定义图像和模型分别位于不同的设备上。
于是我们遇到了这样的错误:
RuntimeError: 预期所有张量都在同一设备上,但发现了至少两个设备,cpu 和 cuda:0!(在检查方法 wrapper___slow_conv2d_forward 的参数 weight 时)
让我们通过将 custom_image_transformed 放置在目标设备上来解决这个问题。
model_1.eval()
with torch.inference_mode():
custom_image_pred = model_1(custom_image_transformed.to(device))
--------------------------------------------------------------------------- RuntimeError Traceback (most recent call last) Input In [66], in <cell line: 2>() 1 model_1.eval() 2 with torch.inference_mode(): ----> 3 custom_image_pred = model_1(custom_image_transformed.to(device)) File ~/code/pytorch/env/lib/python3.8/site-packages/torch/nn/modules/module.py:1130, in Module._call_impl(self, *input, **kwargs) 1126 # If we don't have any hooks, we want to skip the rest of the logic in 1127 # this function, and just call forward. 1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks 1129 or _global_forward_hooks or _global_forward_pre_hooks): -> 1130 return forward_call(*input, **kwargs) 1131 # Do not call functions when jit is used 1132 full_backward_hooks, non_full_backward_hooks = [], [] Input In [41], in TinyVGG.forward(self, x) 42 x = self.conv_block_2(x) 43 # print(x.shape) ---> 44 x = self.classifier(x) 45 # print(x.shape) 46 return x File ~/code/pytorch/env/lib/python3.8/site-packages/torch/nn/modules/module.py:1130, in Module._call_impl(self, *input, **kwargs) 1126 # If we don't have any hooks, we want to skip the rest of the logic in 1127 # this function, and just call forward. 1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks 1129 or _global_forward_hooks or _global_forward_pre_hooks): -> 1130 return forward_call(*input, **kwargs) 1131 # Do not call functions when jit is used 1132 full_backward_hooks, non_full_backward_hooks = [], [] File ~/code/pytorch/env/lib/python3.8/site-packages/torch/nn/modules/container.py:139, in Sequential.forward(self, input) 137 def forward(self, input): 138 for module in self: --> 139 input = module(input) 140 return input File ~/code/pytorch/env/lib/python3.8/site-packages/torch/nn/modules/module.py:1130, in Module._call_impl(self, *input, **kwargs) 1126 # If we don't have any hooks, we want to skip the rest of the logic in 1127 # this function, and just call forward. 1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks 1129 or _global_forward_hooks or _global_forward_pre_hooks): -> 1130 return forward_call(*input, **kwargs) 1131 # Do not call functions when jit is used 1132 full_backward_hooks, non_full_backward_hooks = [], [] File ~/code/pytorch/env/lib/python3.8/site-packages/torch/nn/modules/linear.py:114, in Linear.forward(self, input) 113 def forward(self, input: Tensor) -> Tensor: --> 114 return F.linear(input, self.weight, self.bias) RuntimeError: mat1 and mat2 shapes cannot be multiplied (10x256 and 2560x3)
现在怎么办?
看起来我们遇到了一个形状错误。
为什么会这样呢?
我们已经将自定义图像转换为与模型训练时使用的图像大小相同了...
哦,等等...
我们忽略了一个维度。
批次大小。
我们的模型期望图像张量在开头有一个批次大小维度(NCHW,其中N是批次大小)。
只不过我们当前的自定义图像只有CHW。
我们可以使用torch.unsqueeze(dim=0)来为图像添加一个额外的维度,并最终进行预测。
本质上,我们将告诉模型对单个图像(一个批次大小为1的图像)进行预测。
model_1.eval()
with torch.inference_mode():
# Add an extra dimension to image
custom_image_transformed_with_batch_size = custom_image_transformed.unsqueeze(dim=0)
# Print out different shapes
print(f"Custom image transformed shape: {custom_image_transformed.shape}")
print(f"Unsqueezed custom image shape: {custom_image_transformed_with_batch_size.shape}")
# Make a prediction on image with an extra dimension
custom_image_pred = model_1(custom_image_transformed.unsqueeze(dim=0).to(device))
Custom image transformed shape: torch.Size([3, 64, 64]) Unsqueezed custom image shape: torch.Size([1, 3, 64, 64])
太好了!!!
看起来成功了!
注意: 我们刚刚经历的是三种经典且最常见的深度学习和 PyTorch 问题:
- 数据类型错误 - 我们的模型期望
torch.float32,而我们的原始自定义图像为uint8。- 设备错误 - 我们的模型位于目标设备(在我们的例子中是 GPU)上,而我们的目标数据尚未移动到目标设备。
- 形状错误 - 我们的模型期望输入图像的形状为
[N, C, H, W]或[batch_size, color_channels, height, width],而我们的自定义图像张量的形状为[color_channels, height, width]。请记住,这些错误不仅仅出现在自定义图像预测中。
它们几乎会出现在你处理的每一种数据类型(文本、音频、结构化数据)和问题中。
现在让我们看看模型的预测结果。
custom_image_pred
tensor([[ 0.1172, 0.0160, -0.1425]], device='cuda:0')
好的,这些仍然是 logit 形式(模型的原始输出称为 logits)。
让我们将它们从 logits 转换为预测概率,再转换为预测标签。
# Print out prediction logits
print(f"Prediction logits: {custom_image_pred}")
# Convert logits -> prediction probabilities (using torch.softmax() for multi-class classification)
custom_image_pred_probs = torch.softmax(custom_image_pred, dim=1)
print(f"Prediction probabilities: {custom_image_pred_probs}")
# Convert prediction probabilities -> prediction labels
custom_image_pred_label = torch.argmax(custom_image_pred_probs, dim=1)
print(f"Prediction label: {custom_image_pred_label}")
Prediction logits: tensor([[ 0.1172, 0.0160, -0.1425]], device='cuda:0') Prediction probabilities: tensor([[0.3738, 0.3378, 0.2883]], device='cuda:0') Prediction label: tensor([0], device='cuda:0')
好的!
看起来不错。
但当然,我们的预测标签仍然是索引/张量形式。
我们可以通过在 class_names 列表中进行索引来将其转换为字符串类名预测。
# Find the predicted label
custom_image_pred_class = class_names[custom_image_pred_label.cpu()] # put pred label to CPU, otherwise will error
custom_image_pred_class
'pizza'
哇。
看起来模型在预测上是正确的,尽管根据我们的评估指标,它的表现一直不佳。
注意: 目前形式的模型无论给出什么图像,都会预测“披萨”、“牛排”或“寿司”。如果你想让模型预测不同的类别,你需要对其进行相应的训练。
但如果我们检查 custom_image_pred_probs,我们会注意到模型对每个类别的权重几乎相同(数值相似)。
# The values of the prediction probabilities are quite similar
custom_image_pred_probs
tensor([[0.3738, 0.3378, 0.2883]], device='cuda:0')
预测概率如此接近可能意味着以下几点:
- 模型试图同时预测所有三个类别(可能存在一张同时包含披萨、牛排和寿司的图片)。
- 模型并不清楚它想要预测什么,因此只是给每个类别分配了相似的值。
在我们的案例中,情况是第2点,因为我们的模型训练不佳,基本上是在猜测预测结果。
11.3 整合自定义图像预测:构建一个函数¶
每次想要对自定义图像进行预测时,重复上述所有步骤很快就会变得繁琐。
因此,让我们将这些步骤整合到一个函数中,以便我们可以轻松地反复使用。
具体来说,让我们创建一个函数,该函数:
- 接收目标图像路径并将其转换为模型所需的正确数据类型(
torch.float32)。 - 确保目标图像像素值在
[0, 1]范围内。 - 根据需要转换目标图像。
- 确保模型位于目标设备上。
- 使用训练好的模型对目标图像进行预测(确保图像大小正确且与模型位于同一设备上)。
- 将模型的输出对数转换为预测概率。
- 将预测概率转换为预测标签。
- 绘制目标图像以及模型预测和预测概率。
虽然步骤不少,但我们能做到!
def pred_and_plot_image(model: torch.nn.Module,
image_path: str,
class_names: List[str] = None,
transform=None,
device: torch.device = device):
"""Makes a prediction on a target image and plots the image with its prediction."""
# 1. Load in image and convert the tensor values to float32
target_image = torchvision.io.read_image(str(image_path)).type(torch.float32)
# 2. Divide the image pixel values by 255 to get them between [0, 1]
target_image = target_image / 255.
# 3. Transform if necessary
if transform:
target_image = transform(target_image)
# 4. Make sure the model is on the target device
model.to(device)
# 5. Turn on model evaluation mode and inference mode
model.eval()
with torch.inference_mode():
# Add an extra dimension to the image
target_image = target_image.unsqueeze(dim=0)
# Make a prediction on image with an extra dimension and send it to the target device
target_image_pred = model(target_image.to(device))
# 6. Convert logits -> prediction probabilities (using torch.softmax() for multi-class classification)
target_image_pred_probs = torch.softmax(target_image_pred, dim=1)
# 7. Convert prediction probabilities -> prediction labels
target_image_pred_label = torch.argmax(target_image_pred_probs, dim=1)
# 8. Plot the image alongside the prediction and prediction probability
plt.imshow(target_image.squeeze().permute(1, 2, 0)) # make sure it's the right size for matplotlib
if class_names:
title = f"Pred: {class_names[target_image_pred_label.cpu()]} | Prob: {target_image_pred_probs.max().cpu():.3f}"
else:
title = f"Pred: {target_image_pred_label} | Prob: {target_image_pred_probs.max().cpu():.3f}"
plt.title(title)
plt.axis(False);
这个函数看起来真不错,我们来测试一下。
# Pred on our custom image
pred_and_plot_image(model=model_1,
image_path=custom_image_path,
class_names=class_names,
transform=custom_image_transform,
device=device)

再次双击666!
看起来我们的模型仅仅是猜测就猜对了预测结果。
不过,对于其他图像,情况可能就不总是这样了...
这张图片也有些像素化,因为我们使用 custom_image_transform 将其调整为 [64, 64]。
练习: 尝试用你自己拍摄的披萨、牛排或寿司图片进行预测,看看会发生什么。
主要收获¶
在本模块中,我们涵盖了相当多的内容。
让我们用几个要点来总结一下。
- PyTorch 提供了许多内置函数来处理各种数据,从视觉到文本、音频再到推荐系统。
- 如果 PyTorch 的内置数据加载函数不符合你的需求,你可以编写代码通过继承
torch.utils.data.Dataset来创建自己的自定义数据集。 - PyTorch 中的
torch.utils.data.DataLoader帮助将你的Dataset转换为可迭代对象,这些对象在训练和测试模型时可以使用。 - 机器学习中很大一部分工作是处理 过拟合 和 欠拟合 之间的平衡(我们在上面讨论了不同的方法,因此一个好的练习是进一步研究并编写代码尝试不同的技术)。
- 使用训练好的模型对自定义数据进行预测是可能的,只要你将数据格式化为与模型训练时相似的格式。确保你注意三个主要的 PyTorch 和深度学习错误:
- 错误的类型 - 你的模型期望
torch.float32,而你的数据是torch.uint8。 - 错误的数据形状 - 你的模型期望
[batch_size, color_channels, height, width],而你的数据是[color_channels, height, width]。 - 错误的设备 - 你的模型在 GPU 上,而你的数据在 CPU 上。
- 错误的类型 - 你的模型期望
练习¶
所有练习都集中在练习上述章节中的代码。
你应该能够通过参考每个章节或遵循所链接的资源来完成这些练习。
所有练习都应该使用设备无关代码完成。
资源:
- 04章节的练习模板笔记本
- 04章节的示例解决方案笔记本(在做练习之前不要看这个)
- 我们的模型表现不佳(不适合数据)。防止欠拟合的3种方法是什么?写下它们并分别用一句话解释。
- 重新创建我们在第1、2、3和4节中构建的数据加载函数。你应该准备好可用的训练和测试
DataLoader。 - 重新创建我们在第7节中构建的
model_0。 - 为
model_0创建训练和测试函数。 - 尝试对你在练习3中创建的模型进行5、20和50个周期的训练,结果会发生什么变化?
- 使用学习率为0.001的
torch.optim.Adam()作为优化器。
- 使用学习率为0.001的
- 将模型中的隐藏单元数量增加一倍,并训练20个周期,结果会发生什么变化?
- 将你使用的数据量增加一倍,并训练20个周期,结果会发生什么变化?
- 注意: 你可以使用自定义数据创建笔记本来扩展你的Food101数据集。
- 你也可以在GitHub上找到已经格式化的双倍数据(20%而不是10%子集)数据集,你需要像练习2中那样编写下载代码来将其导入到这个笔记本中。
- 对你自己的披萨/牛排/寿司的定制图像进行预测(你甚至可以从互联网上下载一张)并分享你的预测结果。
- 你在练习7中训练的模型是否正确?
- 如果不是,你认为可以做些什么来改进它?
额外课程¶
- 通过PyTorch的数据集和数据加载器教程笔记本来练习你对PyTorch
Dataset和DataLoader的理解。 - 花10分钟阅读PyTorch
torchvision.transforms文档。- 你可以在变换示例教程中看到变换的演示。
- 花10分钟阅读PyTorch的
torchvision.datasets文档。- 有哪些数据集让你印象深刻?
- 你如何尝试在这些数据集上构建模型?
- TorchData目前处于测试阶段(截至2022年4月),它将是未来在PyTorch中加载数据的一种方式,但现在可以开始了解它。
- 为了加速深度学习模型,你可以采取一些技巧来改进计算、内存和开销计算,更多信息请阅读Horace He的文章Making Deep Learning Go Brrrr From First Principles。