 二元分类、多类分类、目标检测和分割的计算机视觉问题示例。
二元分类、多类分类、目标检测和分割的计算机视觉问题示例。计算机视觉的应用领域¶
如果你使用智能手机,那么你已经接触过计算机视觉技术了。
相机和照片应用通过计算机视觉技术来增强和分类图像。
现代汽车利用计算机视觉技术来避免与其他车辆碰撞并保持在车道内行驶。
制造商使用计算机视觉技术来识别各种产品中的缺陷。
监控摄像头通过计算机视觉技术来检测潜在的入侵者。
本质上,任何可以用视觉方式描述的事物都有可能成为计算机视觉技术的应用场景。
我们将涵盖的内容¶
我们将会把在前几节中学习到的 PyTorch 工作流程应用于计算机视觉领域。
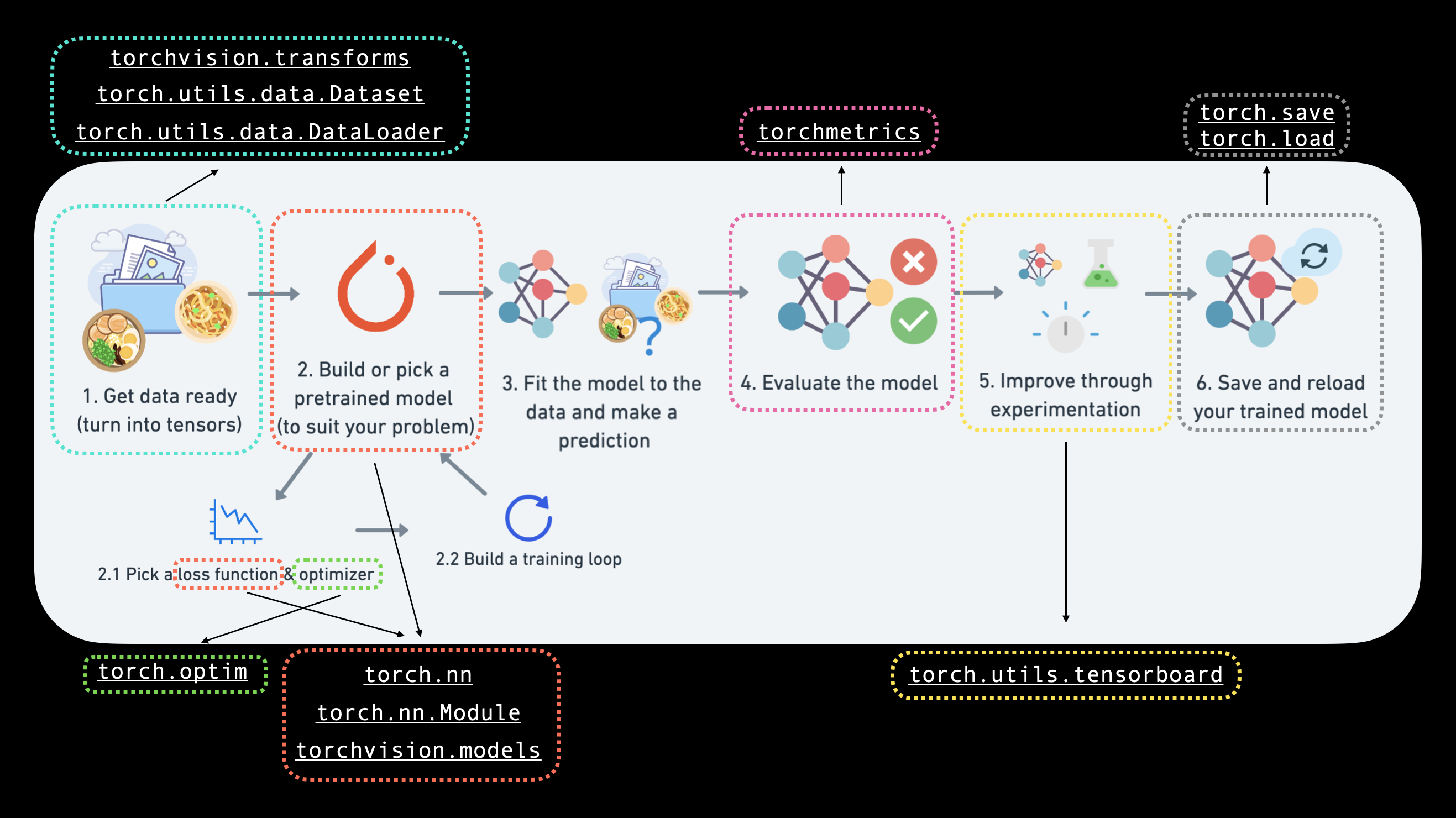
具体来说,我们将涵盖以下内容:
| 主题 | 内容 |
|---|---|
| 0. PyTorch 中的计算机视觉库 | PyTorch 内置了许多有用的计算机视觉库,让我们来看看它们。 |
| 1. 加载数据 | 为了练习计算机视觉,我们将从 FashionMNIST 中获取一些不同服装的图像。 |
| 2. 准备数据 | 我们已经有了一些图像,让我们用 PyTorch DataLoader 加载它们,以便在训练循环中使用。 |
| 3. 模型 0:构建基准模型 | 在这里,我们将创建一个多类别分类模型来学习数据中的模式,我们还将选择损失函数、优化器并构建训练循环。 |
| 4. 预测和评估模型 0 | 让我们用基准模型进行一些预测并评估它们。 |
| 5. 设置设备无关代码以供未来模型使用 | 编写设备无关代码是最佳实践,让我们来设置它。 |
| 6. 模型 1:增加非线性 | 实验是机器学习的重要部分,让我们尝试通过增加非线性层来改进基准模型。 |
| 7. 模型 2:卷积神经网络 (CNN) | 现在是时候专注于计算机视觉,并引入强大的卷积神经网络架构了。 |
| 8. 比较我们的模型 | 我们已经构建了三个不同的模型,让我们来比较它们。 |
| 9. 评估我们的最佳模型 | 让我们对随机图像进行一些预测并评估我们的最佳模型。 |
| 10. 制作混淆矩阵 | 混淆矩阵是评估分类模型的好方法,让我们看看如何制作一个。 |
| 11. 保存和加载表现最佳的模型 | 因为我们可能以后会用到我们的模型,让我们保存它并确保它能正确加载回来。 |
在哪里可以获得帮助?¶
本课程的所有资料都存放在 GitHub 上。
如果你遇到问题,也可以在课程的 GitHub Discussions 页面 提问。
当然,还有 PyTorch 文档 和 PyTorch 开发者论坛,这是所有 PyTorch 相关问题的非常有帮助的地方。
0. PyTorch 中的计算机视觉库¶
在开始编写代码之前,我们先来了解一下你应该知道的一些 PyTorch 计算机视觉库。
| PyTorch 模块 | 功能描述 |
|---|---|
torchvision |
包含常用于计算机视觉问题的数据集、模型架构和图像变换。 |
torchvision.datasets |
这里你可以找到许多用于图像分类、目标检测、图像标注、视频分类等问题的示例计算机视觉数据集。它还包含一系列用于创建自定义数据集的基类。 |
torchvision.models |
这个模块包含在 PyTorch 中实现的性能良好且常用的计算机视觉模型架构,你可以将这些模型用于自己的问题。 |
torchvision.transforms |
通常在模型使用之前,图像需要进行变换(转换为数字/处理/增强),常见的图像变换方法在这里可以找到。 |
torch.utils.data.Dataset |
PyTorch 数据集的基类。 |
torch.utils.data.DataLoader |
在 torch.utils.data.Dataset 创建的数据集上创建一个 Python 可迭代对象。 |
注意:
torch.utils.data.Dataset和torch.utils.data.DataLoader类不仅适用于 PyTorch 中的计算机视觉,它们还能处理许多不同类型的数据。
现在我们已经介绍了一些最重要的 PyTorch 计算机视觉库,接下来我们导入相关的依赖项。
# Import PyTorch
import torch
from torch import nn
# Import torchvision
import torchvision
from torchvision import datasets
from torchvision.transforms import ToTensor
# Import matplotlib for visualization
import matplotlib.pyplot as plt
# Check versions
# Note: your PyTorch version shouldn't be lower than 1.10.0 and torchvision version shouldn't be lower than 0.11
print(f"PyTorch version: {torch.__version__}\ntorchvision version: {torchvision.__version__}")
PyTorch version: 2.0.1+cu118 torchvision version: 0.15.2+cu118
1. 获取数据集¶
要开始处理计算机视觉问题,首先我们需要获取一个计算机视觉数据集。
我们将从 FashionMNIST 开始。
MNIST 代表修改后的美国国家标准与技术研究院(Modified National Institute of Standards and Technology)。
原始的 MNIST 数据集包含成千上万的手写数字(从0到9)的示例,曾被用于构建计算机视觉模型,以识别邮局中的数字。
FashionMNIST 由 Zalando 研究团队制作,是一个类似的设置。
只不过它包含10种不同类型的服装的灰度图像。

torchvision.datasets 包含许多示例数据集,你可以用来练习编写计算机视觉代码。FashionMNIST 就是其中之一。由于它有10个不同的图像类别(不同类型的服装),所以这是一个多类别分类问题。
稍后,我们将构建一个计算机视觉神经网络来识别这些图像中的不同服装风格。
PyTorch 在 torchvision.datasets 中存储了许多常见的计算机视觉数据集。
包括在 torchvision.datasets.FashionMNIST() 中的 FashionMNIST。
要下载它,我们提供以下参数:
root: str- 你想将数据下载到哪个文件夹?train: Bool- 你想要训练集还是测试集?download: Bool- 是否应该下载数据?transform: torchvision.transforms- 你希望对数据进行哪些变换?target_transform- 如果你愿意,也可以对目标(标签)进行变换。
torchvision 中的许多其他数据集也有这些参数选项。
# Setup training data
train_data = datasets.FashionMNIST(
root="data", # where to download data to?
train=True, # get training data
download=True, # download data if it doesn't exist on disk
transform=ToTensor(), # images come as PIL format, we want to turn into Torch tensors
target_transform=None # you can transform labels as well
)
# Setup testing data
test_data = datasets.FashionMNIST(
root="data",
train=False, # get test data
download=True,
transform=ToTensor()
)
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz to data/FashionMNIST/raw/train-images-idx3-ubyte.gz
100%|██████████| 26421880/26421880 [00:01<00:00, 16189161.14it/s]
Extracting data/FashionMNIST/raw/train-images-idx3-ubyte.gz to data/FashionMNIST/raw Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz to data/FashionMNIST/raw/train-labels-idx1-ubyte.gz
100%|██████████| 29515/29515 [00:00<00:00, 269809.67it/s]
Extracting data/FashionMNIST/raw/train-labels-idx1-ubyte.gz to data/FashionMNIST/raw Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz to data/FashionMNIST/raw/t10k-images-idx3-ubyte.gz
100%|██████████| 4422102/4422102 [00:00<00:00, 4950701.58it/s]
Extracting data/FashionMNIST/raw/t10k-images-idx3-ubyte.gz to data/FashionMNIST/raw Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz to data/FashionMNIST/raw/t10k-labels-idx1-ubyte.gz
100%|██████████| 5148/5148 [00:00<00:00, 4744512.63it/s]
Extracting data/FashionMNIST/raw/t10k-labels-idx1-ubyte.gz to data/FashionMNIST/raw
让我们来看看训练数据的第一个样本。
# See first training sample
image, label = train_data[0]
image, label
(tensor([[[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0039, 0.0000, 0.0000, 0.0510,
0.2863, 0.0000, 0.0000, 0.0039, 0.0157, 0.0000, 0.0000, 0.0000,
0.0000, 0.0039, 0.0039, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0118, 0.0000, 0.1412, 0.5333,
0.4980, 0.2431, 0.2118, 0.0000, 0.0000, 0.0000, 0.0039, 0.0118,
0.0157, 0.0000, 0.0000, 0.0118],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0235, 0.0000, 0.4000, 0.8000,
0.6902, 0.5255, 0.5647, 0.4824, 0.0902, 0.0000, 0.0000, 0.0000,
0.0000, 0.0471, 0.0392, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.6078, 0.9255,
0.8118, 0.6980, 0.4196, 0.6118, 0.6314, 0.4275, 0.2510, 0.0902,
0.3020, 0.5098, 0.2824, 0.0588],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0039, 0.0000, 0.2706, 0.8118, 0.8745,
0.8549, 0.8471, 0.8471, 0.6392, 0.4980, 0.4745, 0.4784, 0.5725,
0.5529, 0.3451, 0.6745, 0.2588],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0039, 0.0039, 0.0039, 0.0000, 0.7843, 0.9098, 0.9098,
0.9137, 0.8980, 0.8745, 0.8745, 0.8431, 0.8353, 0.6431, 0.4980,
0.4824, 0.7686, 0.8980, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.7176, 0.8824, 0.8471,
0.8745, 0.8941, 0.9216, 0.8902, 0.8784, 0.8706, 0.8784, 0.8667,
0.8745, 0.9608, 0.6784, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.7569, 0.8941, 0.8549,
0.8353, 0.7765, 0.7059, 0.8314, 0.8235, 0.8275, 0.8353, 0.8745,
0.8627, 0.9529, 0.7922, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0039, 0.0118, 0.0000, 0.0471, 0.8588, 0.8627, 0.8314,
0.8549, 0.7529, 0.6627, 0.8902, 0.8157, 0.8549, 0.8784, 0.8314,
0.8863, 0.7725, 0.8196, 0.2039],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0235, 0.0000, 0.3882, 0.9569, 0.8706, 0.8627,
0.8549, 0.7961, 0.7765, 0.8667, 0.8431, 0.8353, 0.8706, 0.8627,
0.9608, 0.4667, 0.6549, 0.2196],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0157, 0.0000, 0.0000, 0.2157, 0.9255, 0.8941, 0.9020,
0.8941, 0.9412, 0.9098, 0.8353, 0.8549, 0.8745, 0.9176, 0.8510,
0.8510, 0.8196, 0.3608, 0.0000],
[0.0000, 0.0000, 0.0039, 0.0157, 0.0235, 0.0275, 0.0078, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.9294, 0.8863, 0.8510, 0.8745,
0.8706, 0.8588, 0.8706, 0.8667, 0.8471, 0.8745, 0.8980, 0.8431,
0.8549, 1.0000, 0.3020, 0.0000],
[0.0000, 0.0118, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.2431, 0.5686, 0.8000, 0.8941, 0.8118, 0.8353, 0.8667,
0.8549, 0.8157, 0.8275, 0.8549, 0.8784, 0.8745, 0.8588, 0.8431,
0.8784, 0.9569, 0.6235, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0706, 0.1725, 0.3216, 0.4196,
0.7412, 0.8941, 0.8627, 0.8706, 0.8510, 0.8863, 0.7843, 0.8039,
0.8275, 0.9020, 0.8784, 0.9176, 0.6902, 0.7373, 0.9804, 0.9725,
0.9137, 0.9333, 0.8431, 0.0000],
[0.0000, 0.2235, 0.7333, 0.8157, 0.8784, 0.8667, 0.8784, 0.8157,
0.8000, 0.8392, 0.8157, 0.8196, 0.7843, 0.6235, 0.9608, 0.7569,
0.8078, 0.8745, 1.0000, 1.0000, 0.8667, 0.9176, 0.8667, 0.8275,
0.8627, 0.9098, 0.9647, 0.0000],
[0.0118, 0.7922, 0.8941, 0.8784, 0.8667, 0.8275, 0.8275, 0.8392,
0.8039, 0.8039, 0.8039, 0.8627, 0.9412, 0.3137, 0.5882, 1.0000,
0.8980, 0.8667, 0.7373, 0.6039, 0.7490, 0.8235, 0.8000, 0.8196,
0.8706, 0.8941, 0.8824, 0.0000],
[0.3843, 0.9137, 0.7765, 0.8235, 0.8706, 0.8980, 0.8980, 0.9176,
0.9765, 0.8627, 0.7608, 0.8431, 0.8510, 0.9451, 0.2549, 0.2863,
0.4157, 0.4588, 0.6588, 0.8588, 0.8667, 0.8431, 0.8510, 0.8745,
0.8745, 0.8784, 0.8980, 0.1137],
[0.2941, 0.8000, 0.8314, 0.8000, 0.7569, 0.8039, 0.8275, 0.8824,
0.8471, 0.7255, 0.7725, 0.8078, 0.7765, 0.8353, 0.9412, 0.7647,
0.8902, 0.9608, 0.9373, 0.8745, 0.8549, 0.8314, 0.8196, 0.8706,
0.8627, 0.8667, 0.9020, 0.2627],
[0.1882, 0.7961, 0.7176, 0.7608, 0.8353, 0.7725, 0.7255, 0.7451,
0.7608, 0.7529, 0.7922, 0.8392, 0.8588, 0.8667, 0.8627, 0.9255,
0.8824, 0.8471, 0.7804, 0.8078, 0.7294, 0.7098, 0.6941, 0.6745,
0.7098, 0.8039, 0.8078, 0.4510],
[0.0000, 0.4784, 0.8588, 0.7569, 0.7020, 0.6706, 0.7176, 0.7686,
0.8000, 0.8235, 0.8353, 0.8118, 0.8275, 0.8235, 0.7843, 0.7686,
0.7608, 0.7490, 0.7647, 0.7490, 0.7765, 0.7529, 0.6902, 0.6118,
0.6549, 0.6941, 0.8235, 0.3608],
[0.0000, 0.0000, 0.2902, 0.7412, 0.8314, 0.7490, 0.6863, 0.6745,
0.6863, 0.7098, 0.7255, 0.7373, 0.7412, 0.7373, 0.7569, 0.7765,
0.8000, 0.8196, 0.8235, 0.8235, 0.8275, 0.7373, 0.7373, 0.7608,
0.7529, 0.8471, 0.6667, 0.0000],
[0.0078, 0.0000, 0.0000, 0.0000, 0.2588, 0.7843, 0.8706, 0.9294,
0.9373, 0.9490, 0.9647, 0.9529, 0.9569, 0.8667, 0.8627, 0.7569,
0.7490, 0.7020, 0.7137, 0.7137, 0.7098, 0.6902, 0.6510, 0.6588,
0.3882, 0.2275, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.1569,
0.2392, 0.1725, 0.2824, 0.1608, 0.1373, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000]]]),
9)
# What's the shape of the image?
image.shape
torch.Size([1, 28, 28])
图像张量的形状为 [1, 28, 28],更具体地说:
[颜色通道=1, 高度=28, 宽度=28]
颜色通道=1 意味着图像是灰度图像。
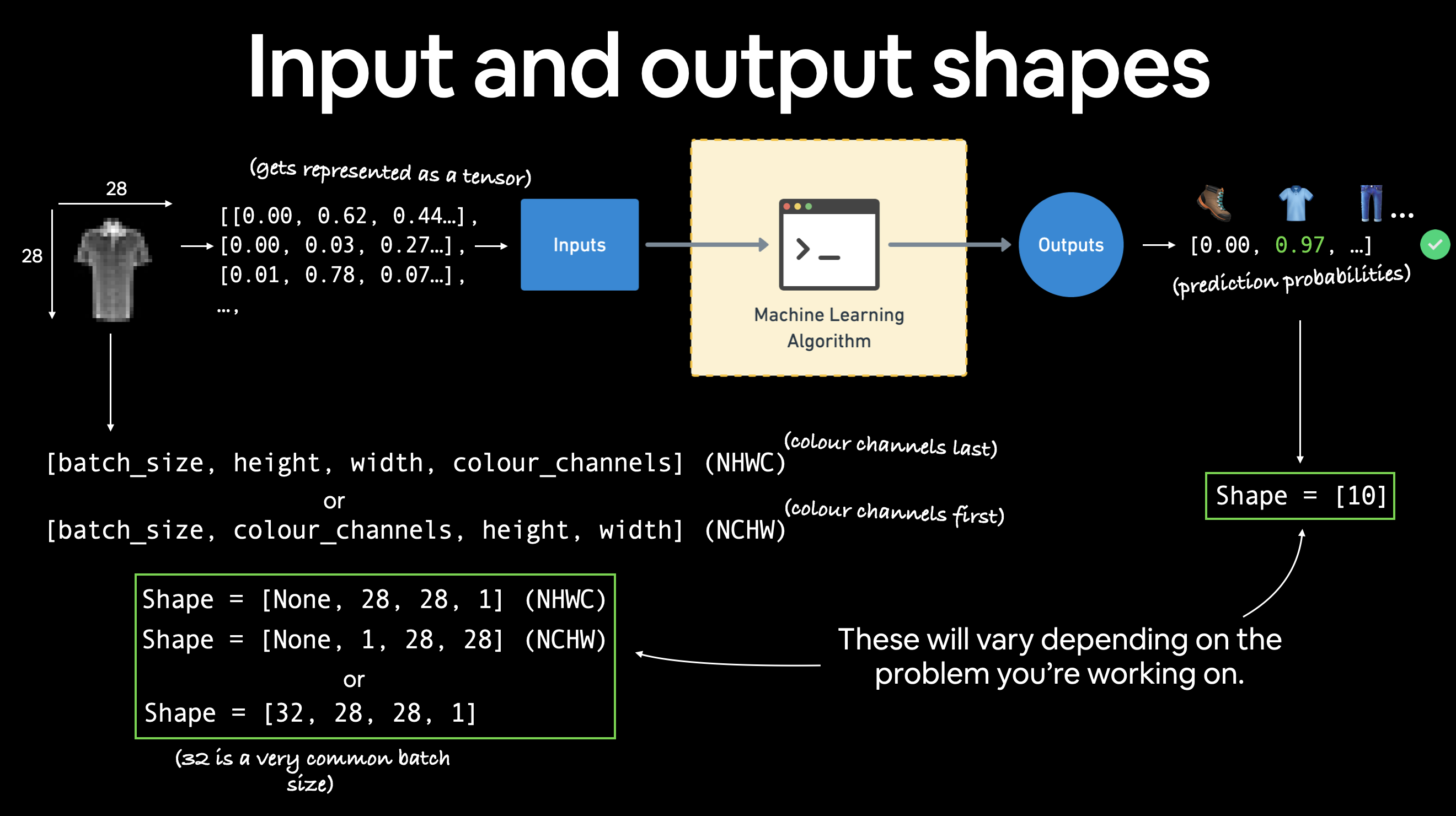 不同的问题会有不同的输入和输出形状。但前提是:将数据编码为数字,构建模型以在这些数字中寻找模式,将这些模式转化为有意义的信息。
不同的问题会有不同的输入和输出形状。但前提是:将数据编码为数字,构建模型以在这些数字中寻找模式,将这些模式转化为有意义的信息。
如果 颜色通道=3,图像将包含红色、绿色和蓝色的像素值(这也被称为RGB 色彩模型)。
我们当前张量的顺序通常被称为 CHW(颜色通道、高度、宽度)。
关于图像应该表示为 CHW(颜色通道在前)还是 HWC(颜色通道在后)存在争议。
注意: 你还会看到
NCHW和NHWC格式,其中N代表图像的数量。例如,如果你有一个batch_size=32,你的张量形状可能是[32, 1, 28, 28]。我们稍后会讨论批次大小。
PyTorch 通常接受 NCHW(通道在前)作为许多操作的默认格式。
然而,PyTorch 也解释说 NHWC(通道在后)性能更好,并且被认为是最佳实践。
目前,由于我们的数据集和模型相对较小,这不会产生太大影响。
但请记住,当你处理更大的图像数据集并使用卷积神经网络时(我们稍后会看到这些),这一点很重要。
让我们来看看我们数据的更多形状。
# How many samples are there?
len(train_data.data), len(train_data.targets), len(test_data.data), len(test_data.targets)
(60000, 60000, 10000, 10000)
所以我们有60,000个训练样本和10,000个测试样本。
有哪些类别呢?
我们可以通过.classes属性来找到这些类别。
# See classes
class_names = train_data.classes
class_names
['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
太棒了!看起来我们有10种不同的衣物类别。
因为我们处理的是10个不同的类别,这意味着我们的问题是多类别分类。
让我们来直观地看看。
1.2 可视化我们的数据¶
import matplotlib.pyplot as plt
image, label = train_data[0]
print(f"Image shape: {image.shape}")
plt.imshow(image.squeeze()) # image shape is [1, 28, 28] (colour channels, height, width)
plt.title(label);
Image shape: torch.Size([1, 28, 28])

我们可以使用 plt.imshow() 的 cmap 参数将图像转换为灰度图像。
plt.imshow(image.squeeze(), cmap="gray")
plt.title(class_names[label]);

漂亮,好吧,就像一个像素化的灰度脚踝靴所能达到的那样美。
我们再来看几个。
# Plot more images
torch.manual_seed(42)
fig = plt.figure(figsize=(9, 9))
rows, cols = 4, 4
for i in range(1, rows * cols + 1):
random_idx = torch.randint(0, len(train_data), size=[1]).item()
img, label = train_data[random_idx]
fig.add_subplot(rows, cols, i)
plt.imshow(img.squeeze(), cmap="gray")
plt.title(class_names[label])
plt.axis(False);

嗯,这个数据集看起来不太美观。
但我们即将学习的如何为此数据集构建模型的原则,将适用于广泛的计算机视觉问题。
本质上,就是利用像素值构建模型,从中寻找模式,以便应用于未来的像素值。
而且,即使是这个小型数据集(是的,即使在深度学习中,60,000张图像也被认为是相当小的),你能编写程序对每一张图像进行分类吗?
你大概可以做到。
但我认为用PyTorch编写模型会更快。
问题: 你认为上述数据仅用直线(线性)就能建模吗?还是你认为也需要非直线(非线性)的线条?
2. 准备 DataLoader¶
现在我们已经准备好了一个数据集。
下一步是用 torch.utils.data.DataLoader 或简称 DataLoader 来准备它。
DataLoader 的作用正如其名。
它帮助将数据加载到模型中。
无论是训练还是推理。
它将一个大的 Dataset 转换成一个较小的数据块的 Python 可迭代对象。
这些较小的数据块被称为 批次 或 小批次,可以通过 batch_size 参数来设置。
为什么要这样做?
因为这样在计算上更高效。
在理想情况下,你可以一次性对所有数据进行前向传播和反向传播。
但一旦你开始使用非常大的数据集,除非你有无限的计算能力,否则将它们分成批次会更容易。
这也给模型提供了更多改进的机会。
通过 小批次(数据的一小部分),每个 epoch 中会进行更频繁的梯度下降(每个小批次一次,而不是每个 epoch 一次)。
什么是好的批次大小?
32 是一个不错的起点 对于许多问题来说。
但由于这是一个你可以设置的值(一个 超参数),你可以尝试各种不同的值,尽管通常使用 2 的幂次(例如 32, 64, 128, 256, 512)。
 使用批次大小为 32 并开启 shuffle 的 FashionMNIST 批处理示例。其他数据集的批处理过程类似,但会根据批次大小而有所不同。
使用批次大小为 32 并开启 shuffle 的 FashionMNIST 批处理示例。其他数据集的批处理过程类似,但会根据批次大小而有所不同。
让我们为训练集和测试集创建 DataLoader。
from torch.utils.data import DataLoader
# Setup the batch size hyperparameter
BATCH_SIZE = 32
# Turn datasets into iterables (batches)
train_dataloader = DataLoader(train_data, # dataset to turn into iterable
batch_size=BATCH_SIZE, # how many samples per batch?
shuffle=True # shuffle data every epoch?
)
test_dataloader = DataLoader(test_data,
batch_size=BATCH_SIZE,
shuffle=False # don't necessarily have to shuffle the testing data
)
# Let's check out what we've created
print(f"Dataloaders: {train_dataloader, test_dataloader}")
print(f"Length of train dataloader: {len(train_dataloader)} batches of {BATCH_SIZE}")
print(f"Length of test dataloader: {len(test_dataloader)} batches of {BATCH_SIZE}")
Dataloaders: (<torch.utils.data.dataloader.DataLoader object at 0x7fc991463cd0>, <torch.utils.data.dataloader.DataLoader object at 0x7fc991475120>) Length of train dataloader: 1875 batches of 32 Length of test dataloader: 313 batches of 32
# Check out what's inside the training dataloader
train_features_batch, train_labels_batch = next(iter(train_dataloader))
train_features_batch.shape, train_labels_batch.shape
(torch.Size([32, 1, 28, 28]), torch.Size([32]))
我们可以通过检查单个样本看到数据保持不变。
# Show a sample
torch.manual_seed(42)
random_idx = torch.randint(0, len(train_features_batch), size=[1]).item()
img, label = train_features_batch[random_idx], train_labels_batch[random_idx]
plt.imshow(img.squeeze(), cmap="gray")
plt.title(class_names[label])
plt.axis("Off");
print(f"Image size: {img.shape}")
print(f"Label: {label}, label size: {label.shape}")
Image size: torch.Size([1, 28, 28]) Label: 6, label size: torch.Size([])

3. 模型0:构建基准模型¶
数据已加载并准备好!
现在是时候通过子类化 nn.Module 来构建一个基准模型了。
基准模型是你能想象到的最简单的模型之一。
你将基准模型作为起点,并尝试通过后续更复杂的模型来改进它。
我们的基准模型将包含两个 nn.Linear() 层。
我们在之前的章节中已经这样做过,但这次会有一点不同。
因为我们正在处理图像数据,我们将使用一个不同的层来开始。
那就是 nn.Flatten() 层。
nn.Flatten() 将张量的维度压缩成一个单一的向量。
当你看到它时,这更容易理解。
# Create a flatten layer
flatten_model = nn.Flatten() # all nn modules function as a model (can do a forward pass)
# Get a single sample
x = train_features_batch[0]
# Flatten the sample
output = flatten_model(x) # perform forward pass
# Print out what happened
print(f"Shape before flattening: {x.shape} -> [color_channels, height, width]")
print(f"Shape after flattening: {output.shape} -> [color_channels, height*width]")
# Try uncommenting below and see what happens
#print(x)
#print(output)
Shape before flattening: torch.Size([1, 28, 28]) -> [color_channels, height, width] Shape after flattening: torch.Size([1, 784]) -> [color_channels, height*width]
nn.Flatten() 层将我们的形状从 [颜色通道, 高度, 宽度] 转换为 [颜色通道, 高度*宽度]。
为什么要这样做?
因为我们现在将像素数据从高度和宽度维度转换成了一个长长的特征向量。
而 nn.Linear() 层喜欢它们的输入是特征向量的形式。
让我们使用 nn.Flatten() 作为第一层来创建我们的第一个模型。
from torch import nn
class FashionMNISTModelV0(nn.Module):
def __init__(self, input_shape: int, hidden_units: int, output_shape: int):
super().__init__()
self.layer_stack = nn.Sequential(
nn.Flatten(), # neural networks like their inputs in vector form
nn.Linear(in_features=input_shape, out_features=hidden_units), # in_features = number of features in a data sample (784 pixels)
nn.Linear(in_features=hidden_units, out_features=output_shape)
)
def forward(self, x):
return self.layer_stack(x)
太棒了!
我们已经有了一个可以使用的基线模型类,现在来实例化一个模型。
我们需要设置以下参数:
input_shape=784- 这是输入模型的特征数量,在我们的例子中,每个像素对应一个特征(目标图像为 28 像素高 x 28 像素宽 = 784 个特征)。hidden_units=10- 隐藏层中的单元/神经元数量,这个数字可以是任意的,但为了保持模型较小,我们先从10开始。output_shape=len(class_names)- 由于我们处理的是一个多类别分类问题,我们需要为数据集中的每个类别设置一个输出神经元。
让我们创建一个模型实例,并暂时将其发送到 CPU(我们很快会进行一个小测试,比较 model_0 在 CPU 和 GPU 上运行的性能)。
torch.manual_seed(42)
# Need to setup model with input parameters
model_0 = FashionMNISTModelV0(input_shape=784, # one for every pixel (28x28)
hidden_units=10, # how many units in the hiden layer
output_shape=len(class_names) # one for every class
)
model_0.to("cpu") # keep model on CPU to begin with
FashionMNISTModelV0(
(layer_stack): Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): Linear(in_features=784, out_features=10, bias=True)
(2): Linear(in_features=10, out_features=10, bias=True)
)
)
3.1 设置损失函数、优化器和评估指标¶
由于我们正在处理一个分类问题,让我们引入我们的 helper_functions.py 脚本,以及我们在笔记本 02 中定义的 accuracy_fn()。
注意: 与其导入和使用我们自己的准确率函数或评估指标,你可以从 TorchMetrics 包 导入各种评估指标。
import requests
from pathlib import Path
# Download helper functions from Learn PyTorch repo (if not already downloaded)
if Path("helper_functions.py").is_file():
print("helper_functions.py already exists, skipping download")
else:
print("Downloading helper_functions.py")
# Note: you need the "raw" GitHub URL for this to work
request = requests.get("https://raw.githubusercontent.com/mrdbourke/pytorch-deep-learning/main/helper_functions.py")
with open("helper_functions.py", "wb") as f:
f.write(request.content)
Downloading helper_functions.py
# Import accuracy metric
from helper_functions import accuracy_fn # Note: could also use torchmetrics.Accuracy(task = 'multiclass', num_classes=len(class_names)).to(device)
# Setup loss function and optimizer
loss_fn = nn.CrossEntropyLoss() # this is also called "criterion"/"cost function" in some places
optimizer = torch.optim.SGD(params=model_0.parameters(), lr=0.1)
3.2 创建一个函数来计时我们的实验¶
损失函数和优化器已经准备就绪!
现在是时候开始训练模型了。
不过,在训练的同时,我们不妨做一些小实验。
我的意思是,让我们创建一个计时函数,来测量我们的模型在CPU和GPU上训练所需的时间。
我们将先在CPU上训练这个模型,然后在GPU上训练下一个模型,看看会发生什么。
我们的计时函数将导入Python的timeit模块中的timeit.default_timer()函数。
from timeit import default_timer as timer
def print_train_time(start: float, end: float, device: torch.device = None):
"""Prints difference between start and end time.
Args:
start (float): Start time of computation (preferred in timeit format).
end (float): End time of computation.
device ([type], optional): Device that compute is running on. Defaults to None.
Returns:
float: time between start and end in seconds (higher is longer).
"""
total_time = end - start
print(f"Train time on {device}: {total_time:.3f} seconds")
return total_time
3.3 创建训练循环并在数据批次上训练模型¶
太棒了!
看起来我们已经准备好所有的拼图碎片了,包括计时器、损失函数、优化器、模型,最重要的是,还有一些数据。
现在让我们创建一个训练循环和一个测试循环来训练和评估我们的模型。
我们将使用与之前的笔记本相同的步骤,但由于我们的数据现在是批次形式,我们将添加另一个循环来遍历我们的数据批次。
我们的数据批次包含在 DataLoader 中,分别是用于训练数据分割的 train_dataloader 和用于测试数据分割的 test_dataloader。
一个批次是 BATCH_SIZE 个样本的 X(特征)和 y(标签),由于我们使用 BATCH_SIZE=32,我们的批次包含 32 个图像样本和目标。
由于我们在批次数据上进行计算,我们的损失和评估指标将按批次计算,而不是整个数据集。
这意味着我们需要将损失和准确性值除以每个数据集的 DataLoader 中的批次数量。
让我们一步步来:
- 遍历 epochs。
- 遍历训练批次,执行训练步骤,计算每个批次的训练损失。
- 遍历测试批次,执行测试步骤,计算每个批次的测试损失。
- 输出正在发生的情况。
- 计时(为了好玩)。
虽然步骤不少,但是...
...如果有疑问,就写代码解决。
# Import tqdm for progress bar
from tqdm.auto import tqdm
# Set the seed and start the timer
torch.manual_seed(42)
train_time_start_on_cpu = timer()
# Set the number of epochs (we'll keep this small for faster training times)
epochs = 3
# Create training and testing loop
for epoch in tqdm(range(epochs)):
print(f"Epoch: {epoch}\n-------")
### Training
train_loss = 0
# Add a loop to loop through training batches
for batch, (X, y) in enumerate(train_dataloader):
model_0.train()
# 1. Forward pass
y_pred = model_0(X)
# 2. Calculate loss (per batch)
loss = loss_fn(y_pred, y)
train_loss += loss # accumulatively add up the loss per epoch
# 3. Optimizer zero grad
optimizer.zero_grad()
# 4. Loss backward
loss.backward()
# 5. Optimizer step
optimizer.step()
# Print out how many samples have been seen
if batch % 400 == 0:
print(f"Looked at {batch * len(X)}/{len(train_dataloader.dataset)} samples")
# Divide total train loss by length of train dataloader (average loss per batch per epoch)
train_loss /= len(train_dataloader)
### Testing
# Setup variables for accumulatively adding up loss and accuracy
test_loss, test_acc = 0, 0
model_0.eval()
with torch.inference_mode():
for X, y in test_dataloader:
# 1. Forward pass
test_pred = model_0(X)
# 2. Calculate loss (accumatively)
test_loss += loss_fn(test_pred, y) # accumulatively add up the loss per epoch
# 3. Calculate accuracy (preds need to be same as y_true)
test_acc += accuracy_fn(y_true=y, y_pred=test_pred.argmax(dim=1))
# Calculations on test metrics need to happen inside torch.inference_mode()
# Divide total test loss by length of test dataloader (per batch)
test_loss /= len(test_dataloader)
# Divide total accuracy by length of test dataloader (per batch)
test_acc /= len(test_dataloader)
## Print out what's happening
print(f"\nTrain loss: {train_loss:.5f} | Test loss: {test_loss:.5f}, Test acc: {test_acc:.2f}%\n")
# Calculate training time
train_time_end_on_cpu = timer()
total_train_time_model_0 = print_train_time(start=train_time_start_on_cpu,
end=train_time_end_on_cpu,
device=str(next(model_0.parameters()).device))
0%| | 0/3 [00:00<?, ?it/s]
Epoch: 0 ------- Looked at 0/60000 samples Looked at 12800/60000 samples Looked at 25600/60000 samples Looked at 38400/60000 samples Looked at 51200/60000 samples Train loss: 0.59039 | Test loss: 0.50954, Test acc: 82.04% Epoch: 1 ------- Looked at 0/60000 samples Looked at 12800/60000 samples Looked at 25600/60000 samples Looked at 38400/60000 samples Looked at 51200/60000 samples Train loss: 0.47633 | Test loss: 0.47989, Test acc: 83.20% Epoch: 2 ------- Looked at 0/60000 samples Looked at 12800/60000 samples Looked at 25600/60000 samples Looked at 38400/60000 samples Looked at 51200/60000 samples Train loss: 0.45503 | Test loss: 0.47664, Test acc: 83.43% Train time on cpu: 32.349 seconds
不错!看来我们的基线模型表现相当好。
即便只是在CPU上训练,也没有花费太多时间,不知道在GPU上会不会更快呢?
我们来写一些代码来评估我们的模型。
4. 进行预测并获取模型0的结果¶
由于我们将构建多个模型,因此编写一些代码以相似的方式评估它们是一个好主意。
具体来说,让我们创建一个函数,该函数接受一个已训练的模型、一个DataLoader、一个损失函数和一个准确率函数。
该函数将使用模型对DataLoader中的数据进行预测,然后我们可以使用损失函数和准确率函数来评估这些预测结果。
torch.manual_seed(42)
def eval_model(model: torch.nn.Module,
data_loader: torch.utils.data.DataLoader,
loss_fn: torch.nn.Module,
accuracy_fn):
"""Returns a dictionary containing the results of model predicting on data_loader.
Args:
model (torch.nn.Module): A PyTorch model capable of making predictions on data_loader.
data_loader (torch.utils.data.DataLoader): The target dataset to predict on.
loss_fn (torch.nn.Module): The loss function of model.
accuracy_fn: An accuracy function to compare the models predictions to the truth labels.
Returns:
(dict): Results of model making predictions on data_loader.
"""
loss, acc = 0, 0
model.eval()
with torch.inference_mode():
for X, y in data_loader:
# Make predictions with the model
y_pred = model(X)
# Accumulate the loss and accuracy values per batch
loss += loss_fn(y_pred, y)
acc += accuracy_fn(y_true=y,
y_pred=y_pred.argmax(dim=1)) # For accuracy, need the prediction labels (logits -> pred_prob -> pred_labels)
# Scale loss and acc to find the average loss/acc per batch
loss /= len(data_loader)
acc /= len(data_loader)
return {"model_name": model.__class__.__name__, # only works when model was created with a class
"model_loss": loss.item(),
"model_acc": acc}
# Calculate model 0 results on test dataset
model_0_results = eval_model(model=model_0, data_loader=test_dataloader,
loss_fn=loss_fn, accuracy_fn=accuracy_fn
)
model_0_results
{'model_name': 'FashionMNISTModelV0',
'model_loss': 0.47663894295692444,
'model_acc': 83.42651757188499}
看起来不错!
我们可以利用这个字典来将基线模型的结果与其他模型进行比较。
5. 设置设备无关代码(以便在有GPU时使用)¶
我们已经了解到在CPU上训练一个包含60,000个样本的PyTorch模型需要多长时间。
注意: 模型训练时间取决于所使用的硬件。通常,更多的处理器意味着更快的训练速度,而较小的模型和较小的数据集通常会比大型模型和大型数据集训练得更快。
现在,让我们为我们的模型和数据设置一些设备无关代码,以便在GPU可用时在GPU上运行。
如果你在Google Colab上运行这个笔记本,并且还没有开启GPU,现在是时候通过Runtime -> Change runtime type -> Hardware accelerator -> GPU来开启一个GPU了。如果你这样做,你的运行时可能会重置,并且你需要通过Runtime -> Run before来重新运行上面的所有单元格。
# Setup device agnostic code
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
device
'cuda'
太棒了!
让我们再来构建一个模型。
6. 模型1:通过非线性构建更好的模型¶
我们在笔记本02中学习了非线性的力量。
观察我们一直在处理的数据,你认为它需要非线性函数吗?
记住,线性意味着直线,而非线性意味着非直线。
让我们来验证一下。
我们将通过重新创建一个与之前类似的模型来实现这一点,只不过这次我们会在每个线性层之间加入非线性函数(nn.ReLU())。
# Create a model with non-linear and linear layers
class FashionMNISTModelV1(nn.Module):
def __init__(self, input_shape: int, hidden_units: int, output_shape: int):
super().__init__()
self.layer_stack = nn.Sequential(
nn.Flatten(), # flatten inputs into single vector
nn.Linear(in_features=input_shape, out_features=hidden_units),
nn.ReLU(),
nn.Linear(in_features=hidden_units, out_features=output_shape),
nn.ReLU()
)
def forward(self, x: torch.Tensor):
return self.layer_stack(x)
看起来不错。
现在让我们用之前使用的相同设置来实例化它。
我们需要 input_shape=784(等于我们图像数据的特征数量),hidden_units=10(从小开始,与我们的基线模型相同)和 output_shape=len(class_names)(每个类别一个输出单元)。
注意: 请注意我们如何保持了模型的大部分设置相同,除了一个变化:添加非线性层。这是进行一系列机器学习实验的标准做法,改变一个地方并观察结果,然后再次重复。
torch.manual_seed(42)
model_1 = FashionMNISTModelV1(input_shape=784, # number of input features
hidden_units=10,
output_shape=len(class_names) # number of output classes desired
).to(device) # send model to GPU if it's available
next(model_1.parameters()).device # check model device
device(type='cuda', index=0)
6.1 设置损失函数、优化器和评估指标¶
与往常一样,我们将设置一个损失函数、一个优化器和一个评估指标(我们可以使用多个评估指标,但目前我们只使用准确性)。
from helper_functions import accuracy_fn
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(params=model_1.parameters(),
lr=0.1)
6.2 将训练和测试循环函数化¶
到目前为止,我们已经多次编写训练和测试循环。
这次我们再次编写它们,但这次我们把它们放在函数中,这样它们就可以被反复调用。
而且因为我们现在使用的是设备无关的代码,我们会确保在特征(X)和目标(y)张量上调用 .to(device)。
对于训练循环,我们将创建一个名为 train_step() 的函数,它接受一个模型、一个 DataLoader、一个损失函数和一个优化器。
测试循环将类似,但它将被命名为 test_step(),并且它将接受一个模型、一个 DataLoader、一个损失函数和一个评估函数。
注意: 由于这些是函数,你可以根据需要自定义它们。我们这里制作的是特定分类用例的基本训练和测试函数。
def train_step(model: torch.nn.Module,
data_loader: torch.utils.data.DataLoader,
loss_fn: torch.nn.Module,
optimizer: torch.optim.Optimizer,
accuracy_fn,
device: torch.device = device):
train_loss, train_acc = 0, 0
model.to(device)
for batch, (X, y) in enumerate(data_loader):
# Send data to GPU
X, y = X.to(device), y.to(device)
# 1. Forward pass
y_pred = model(X)
# 2. Calculate loss
loss = loss_fn(y_pred, y)
train_loss += loss
train_acc += accuracy_fn(y_true=y,
y_pred=y_pred.argmax(dim=1)) # Go from logits -> pred labels
# 3. Optimizer zero grad
optimizer.zero_grad()
# 4. Loss backward
loss.backward()
# 5. Optimizer step
optimizer.step()
# Calculate loss and accuracy per epoch and print out what's happening
train_loss /= len(data_loader)
train_acc /= len(data_loader)
print(f"Train loss: {train_loss:.5f} | Train accuracy: {train_acc:.2f}%")
def test_step(data_loader: torch.utils.data.DataLoader,
model: torch.nn.Module,
loss_fn: torch.nn.Module,
accuracy_fn,
device: torch.device = device):
test_loss, test_acc = 0, 0
model.to(device)
model.eval() # put model in eval mode
# Turn on inference context manager
with torch.inference_mode():
for X, y in data_loader:
# Send data to GPU
X, y = X.to(device), y.to(device)
# 1. Forward pass
test_pred = model(X)
# 2. Calculate loss and accuracy
test_loss += loss_fn(test_pred, y)
test_acc += accuracy_fn(y_true=y,
y_pred=test_pred.argmax(dim=1) # Go from logits -> pred labels
)
# Adjust metrics and print out
test_loss /= len(data_loader)
test_acc /= len(data_loader)
print(f"Test loss: {test_loss:.5f} | Test accuracy: {test_acc:.2f}%\n")
哇呼!
现在我们已经有了用于训练和测试模型的函数,让我们来运行它们。
我们将在每个 epoch 中进行一个循环。
这样,每个 epoch 我们都会进行一次训练和一次测试步骤。
注意: 你可以自定义进行测试步骤的频率。有时人们每五个 epoch 或十个 epoch 进行一次测试,或者像我们这样,每个 epoch 都进行一次。
我们还可以计时,看看代码在 GPU 上运行需要多长时间。
torch.manual_seed(42)
# Measure time
from timeit import default_timer as timer
train_time_start_on_gpu = timer()
epochs = 3
for epoch in tqdm(range(epochs)):
print(f"Epoch: {epoch}\n---------")
train_step(data_loader=train_dataloader,
model=model_1,
loss_fn=loss_fn,
optimizer=optimizer,
accuracy_fn=accuracy_fn
)
test_step(data_loader=test_dataloader,
model=model_1,
loss_fn=loss_fn,
accuracy_fn=accuracy_fn
)
train_time_end_on_gpu = timer()
total_train_time_model_1 = print_train_time(start=train_time_start_on_gpu,
end=train_time_end_on_gpu,
device=device)
0%| | 0/3 [00:00<?, ?it/s]
Epoch: 0 --------- Train loss: 1.09199 | Train accuracy: 61.34% Test loss: 0.95636 | Test accuracy: 65.00% Epoch: 1 --------- Train loss: 0.78101 | Train accuracy: 71.93% Test loss: 0.72227 | Test accuracy: 73.91% Epoch: 2 --------- Train loss: 0.67027 | Train accuracy: 75.94% Test loss: 0.68500 | Test accuracy: 75.02% Train time on cuda: 36.878 seconds
太棒了!
我们的模型已经训练完成,但训练时间比预期要长?
注意: 在 CUDA 和 CPU 上的训练时间很大程度上取决于您使用的 CPU/GPU 的质量。继续阅读以获得更详细的解释。
问题: "我使用了 GPU,但我的模型并没有训练得更快,这可能是什么原因?"
回答: 嗯,一个可能的原因是您的数据集和模型都非常小(就像我们正在使用的数据集和模型一样),使用 GPU 的好处被实际传输数据到 GPU 所需的时间所抵消。
在将数据从 CPU 内存(默认)复制到 GPU 内存之间存在一个小瓶颈。
因此,对于较小的模型和数据集,CPU 实际上可能是最佳的计算地点。
但对于较大的数据集和模型,GPU 提供的计算速度通常远远超过将数据传输到 GPU 的成本。
然而,这很大程度上取决于您使用的硬件。通过实践,您会习惯于找到训练模型的最佳地点。
让我们使用 eval_model() 函数来评估我们训练好的 model_1,看看效果如何。
torch.manual_seed(42)
# Note: This will error due to `eval_model()` not using device agnostic code
model_1_results = eval_model(model=model_1,
data_loader=test_dataloader,
loss_fn=loss_fn,
accuracy_fn=accuracy_fn)
model_1_results
--------------------------------------------------------------------------- RuntimeError Traceback (most recent call last) <ipython-input-27-93fed76e63a5> in <cell line: 4>() 2 3 # Note: This will error due to `eval_model()` not using device agnostic code ----> 4 model_1_results = eval_model(model=model_1, 5 data_loader=test_dataloader, 6 loss_fn=loss_fn, <ipython-input-20-885bc9be9cde> in eval_model(model, data_loader, loss_fn, accuracy_fn) 20 for X, y in data_loader: 21 # Make predictions with the model ---> 22 y_pred = model(X) 23 24 # Accumulate the loss and accuracy values per batch /usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py in _call_impl(self, *args, **kwargs) 1499 or _global_backward_pre_hooks or _global_backward_hooks 1500 or _global_forward_hooks or _global_forward_pre_hooks): -> 1501 return forward_call(*args, **kwargs) 1502 # Do not call functions when jit is used 1503 full_backward_hooks, non_full_backward_hooks = [], [] <ipython-input-22-a46e692b8bdd> in forward(self, x) 12 13 def forward(self, x: torch.Tensor): ---> 14 return self.layer_stack(x) /usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py in _call_impl(self, *args, **kwargs) 1499 or _global_backward_pre_hooks or _global_backward_hooks 1500 or _global_forward_hooks or _global_forward_pre_hooks): -> 1501 return forward_call(*args, **kwargs) 1502 # Do not call functions when jit is used 1503 full_backward_hooks, non_full_backward_hooks = [], [] /usr/local/lib/python3.10/dist-packages/torch/nn/modules/container.py in forward(self, input) 215 def forward(self, input): 216 for module in self: --> 217 input = module(input) 218 return input 219 /usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py in _call_impl(self, *args, **kwargs) 1499 or _global_backward_pre_hooks or _global_backward_hooks 1500 or _global_forward_hooks or _global_forward_pre_hooks): -> 1501 return forward_call(*args, **kwargs) 1502 # Do not call functions when jit is used 1503 full_backward_hooks, non_full_backward_hooks = [], [] /usr/local/lib/python3.10/dist-packages/torch/nn/modules/linear.py in forward(self, input) 112 113 def forward(self, input: Tensor) -> Tensor: --> 114 return F.linear(input, self.weight, self.bias) 115 116 def extra_repr(self) -> str: RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! (when checking argument for argument mat1 in method wrapper_CUDA_addmm)
哎呀!
看来我们的 eval_model() 函数出错了,错误信息如下:
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! (when checking argument for argument mat1 in method wrapper_addmm)
这是因为我们虽然设置了让数据和模型使用设备无关的代码,但没有对评估函数做同样的处理。
我们可以通过向 eval_model() 函数传递一个目标 device 参数来解决这个问题。
然后我们再尝试重新计算结果。
# Move values to device
torch.manual_seed(42)
def eval_model(model: torch.nn.Module,
data_loader: torch.utils.data.DataLoader,
loss_fn: torch.nn.Module,
accuracy_fn,
device: torch.device = device):
"""Evaluates a given model on a given dataset.
Args:
model (torch.nn.Module): A PyTorch model capable of making predictions on data_loader.
data_loader (torch.utils.data.DataLoader): The target dataset to predict on.
loss_fn (torch.nn.Module): The loss function of model.
accuracy_fn: An accuracy function to compare the models predictions to the truth labels.
device (str, optional): Target device to compute on. Defaults to device.
Returns:
(dict): Results of model making predictions on data_loader.
"""
loss, acc = 0, 0
model.eval()
with torch.inference_mode():
for X, y in data_loader:
# Send data to the target device
X, y = X.to(device), y.to(device)
y_pred = model(X)
loss += loss_fn(y_pred, y)
acc += accuracy_fn(y_true=y, y_pred=y_pred.argmax(dim=1))
# Scale loss and acc
loss /= len(data_loader)
acc /= len(data_loader)
return {"model_name": model.__class__.__name__, # only works when model was created with a class
"model_loss": loss.item(),
"model_acc": acc}
# Calculate model 1 results with device-agnostic code
model_1_results = eval_model(model=model_1, data_loader=test_dataloader,
loss_fn=loss_fn, accuracy_fn=accuracy_fn,
device=device
)
model_1_results
{'model_name': 'FashionMNISTModelV1',
'model_loss': 0.6850008964538574,
'model_acc': 75.01996805111821}
# Check baseline results
model_0_results
{'model_name': 'FashionMNISTModelV0',
'model_loss': 0.47663894295692444,
'model_acc': 83.42651757188499}
哇,在这种情况下,看起来在我们的模型中加入非线性因素反而使其表现不如基准线。
这是机器学习中需要注意的一点,有时候你认为应该有效的方法却并不奏效。
而有时候,你认为可能不奏效的方法却能发挥作用。
机器学习既是科学,也是艺术。
从目前的情况来看,我们的模型似乎在训练数据上过拟合了。
过拟合意味着我们的模型很好地学习了训练数据,但这些模式并没有泛化到测试数据上。
解决过拟合的两个主要方法包括:
- 使用一个更小或不同的模型(某些模型对特定类型的数据拟合得更好)。
- 使用更大的数据集(数据越多,模型学习到可泛化模式的机会就越大)。
还有其他方法,但我将这作为一个挑战留给你去探索。
试着在网上搜索“防止机器学习中过拟合的方法”,看看能找到什么。
与此同时,让我们来看看第一种方法:使用不同的模型。
7. 模型2:构建卷积神经网络(CNN)¶
好了,是时候提升一个档次了。
现在是时候创建一个卷积神经网络(CNN 或 ConvNet)。
CNN 以其识别视觉数据中模式的能力而闻名。
既然我们处理的是视觉数据,让我们看看使用 CNN 模型是否能改进我们的基线模型。
我们将使用的 CNN 模型称为 TinyVGG,来自CNN Explainer网站。
它遵循典型的卷积神经网络结构:
输入层 -> [卷积层 -> 激活层 -> 池化层] -> 输出层
其中,[卷积层 -> 激活层 -> 池化层]的内容可以根据需要进行扩展和重复多次。
我应该使用什么模型?¶
问题: 等等,你说CNN适合图像处理,还有其他类型的模型我应该了解吗?
很好的问题。
这个表格是一个很好的通用指南,告诉你应该使用哪种模型(尽管也有例外)。
| 问题类型 | 一般使用的模型 | 代码示例 |
|---|---|---|
| 结构化数据(Excel表格,行和列数据) | 梯度提升模型,随机森林,XGBoost | sklearn.ensemble, XGBoost库 |
| 非结构化数据(图像,音频,语言) | 卷积神经网络,Transformer | torchvision.models, HuggingFace Transformers |
注意: 上面的表格仅供参考,你最终使用的模型将高度依赖于你正在解决的问题以及你所面临的约束(数据量,延迟要求)。
关于模型的讨论就到这里,现在让我们构建一个CNN模型,复制CNN Explainer网站上的模型。
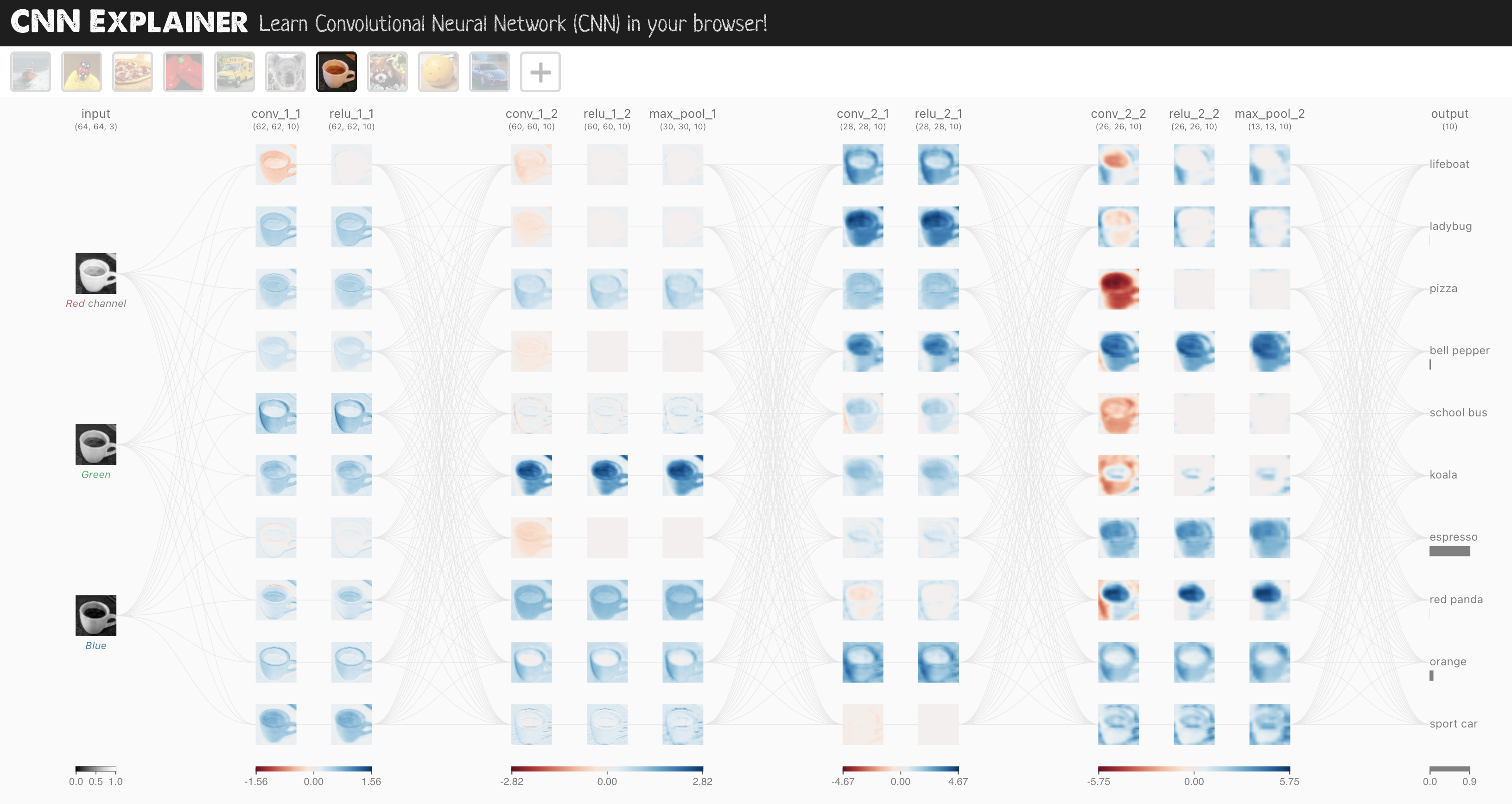
为此,我们将利用torch.nn中的nn.Conv2d()和nn.MaxPool2d()层。
# Create a convolutional neural network
class FashionMNISTModelV2(nn.Module):
"""
Model architecture copying TinyVGG from:
https://poloclub.github.io/cnn-explainer/
"""
def __init__(self, input_shape: int, hidden_units: int, output_shape: int):
super().__init__()
self.block_1 = nn.Sequential(
nn.Conv2d(in_channels=input_shape,
out_channels=hidden_units,
kernel_size=3, # how big is the square that's going over the image?
stride=1, # default
padding=1),# options = "valid" (no padding) or "same" (output has same shape as input) or int for specific number
nn.ReLU(),
nn.Conv2d(in_channels=hidden_units,
out_channels=hidden_units,
kernel_size=3,
stride=1,
padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,
stride=2) # default stride value is same as kernel_size
)
self.block_2 = nn.Sequential(
nn.Conv2d(hidden_units, hidden_units, 3, padding=1),
nn.ReLU(),
nn.Conv2d(hidden_units, hidden_units, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.classifier = nn.Sequential(
nn.Flatten(),
# Where did this in_features shape come from?
# It's because each layer of our network compresses and changes the shape of our inputs data.
nn.Linear(in_features=hidden_units*7*7,
out_features=output_shape)
)
def forward(self, x: torch.Tensor):
x = self.block_1(x)
# print(x.shape)
x = self.block_2(x)
# print(x.shape)
x = self.classifier(x)
# print(x.shape)
return x
torch.manual_seed(42)
model_2 = FashionMNISTModelV2(input_shape=1,
hidden_units=10,
output_shape=len(class_names)).to(device)
model_2
FashionMNISTModelV2(
(block_1): Sequential(
(0): Conv2d(1, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(10, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(block_2): Sequential(
(0): Conv2d(10, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(10, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): Linear(in_features=490, out_features=10, bias=True)
)
)
太棒了!
这是我们迄今为止最大的模型!
我们所做的是机器学习中的常见做法。
找到一个模型架构,并用代码复现它。
7.1 逐步解析 nn.Conv2d()¶
我们可以从上面的模型开始使用并观察其表现,但首先让我们逐步了解我们新增的两个层:
nn.Conv2d(),也称为卷积层。nn.MaxPool2d(),也称为最大池化层。
问题:
nn.Conv2d()中的 "2d" 代表什么?"2d" 代表二维数据。也就是说,我们的图像有两个维度:高度和宽度。尽管颜色通道也有维度,但每个颜色通道同样具有高度和宽度这两个维度。
对于其他维度的数据(例如文本的一维数据或三维物体的三维数据),还有
nn.Conv1d()和nn.Conv3d()。
为了测试这些层,让我们创建一些类似于 CNN Explainer 中使用的示例数据。
torch.manual_seed(42)
# Create sample batch of random numbers with same size as image batch
images = torch.randn(size=(32, 3, 64, 64)) # [batch_size, color_channels, height, width]
test_image = images[0] # get a single image for testing
print(f"Image batch shape: {images.shape} -> [batch_size, color_channels, height, width]")
print(f"Single image shape: {test_image.shape} -> [color_channels, height, width]")
print(f"Single image pixel values:\n{test_image}")
Image batch shape: torch.Size([32, 3, 64, 64]) -> [batch_size, color_channels, height, width]
Single image shape: torch.Size([3, 64, 64]) -> [color_channels, height, width]
Single image pixel values:
tensor([[[ 1.9269, 1.4873, 0.9007, ..., 1.8446, -1.1845, 1.3835],
[ 1.4451, 0.8564, 2.2181, ..., 0.3399, 0.7200, 0.4114],
[ 1.9312, 1.0119, -1.4364, ..., -0.5558, 0.7043, 0.7099],
...,
[-0.5610, -0.4830, 0.4770, ..., -0.2713, -0.9537, -0.6737],
[ 0.3076, -0.1277, 0.0366, ..., -2.0060, 0.2824, -0.8111],
[-1.5486, 0.0485, -0.7712, ..., -0.1403, 0.9416, -0.0118]],
[[-0.5197, 1.8524, 1.8365, ..., 0.8935, -1.5114, -0.8515],
[ 2.0818, 1.0677, -1.4277, ..., 1.6612, -2.6223, -0.4319],
[-0.1010, -0.4388, -1.9775, ..., 0.2106, 0.2536, -0.7318],
...,
[ 0.2779, 0.7342, -0.3736, ..., -0.4601, 0.1815, 0.1850],
[ 0.7205, -0.2833, 0.0937, ..., -0.1002, -2.3609, 2.2465],
[-1.3242, -0.1973, 0.2920, ..., 0.5409, 0.6940, 1.8563]],
[[-0.7978, 1.0261, 1.1465, ..., 1.2134, 0.9354, -0.0780],
[-1.4647, -1.9571, 0.1017, ..., -1.9986, -0.7409, 0.7011],
[-1.3938, 0.8466, -1.7191, ..., -1.1867, 0.1320, 0.3407],
...,
[ 0.8206, -0.3745, 1.2499, ..., -0.0676, 0.0385, 0.6335],
[-0.5589, -0.3393, 0.2347, ..., 2.1181, 2.4569, 1.3083],
[-0.4092, 1.5199, 0.2401, ..., -0.2558, 0.7870, 0.9924]]])
让我们创建一个带有各种参数的 nn.Conv2d() 示例:
in_channels(int) - 输入图像的通道数。out_channels(int) - 卷积产生的通道数。kernel_size(int 或 tuple) - 卷积核/滤波器的大小。stride(int 或 tuple, 可选) - 卷积核每次移动的步长。默认值:1。padding(int, tuple, str) - 添加到输入四周的填充。默认值:0。
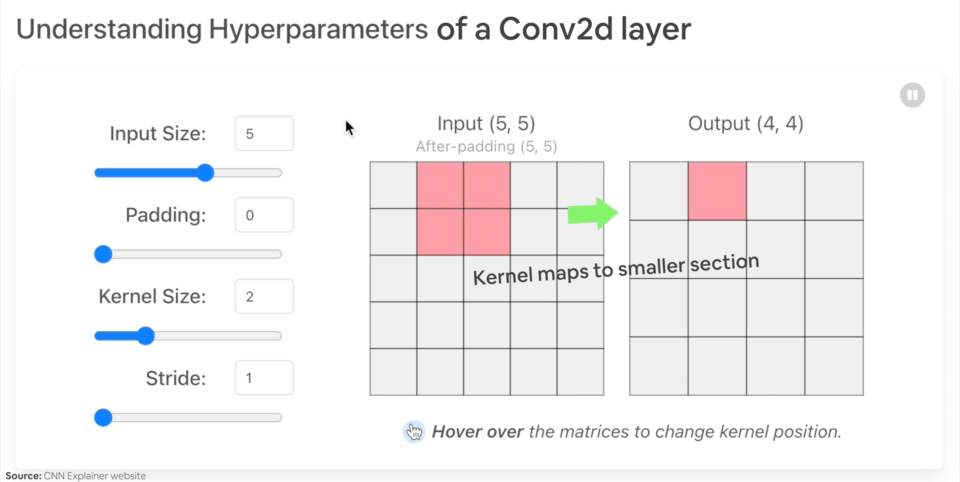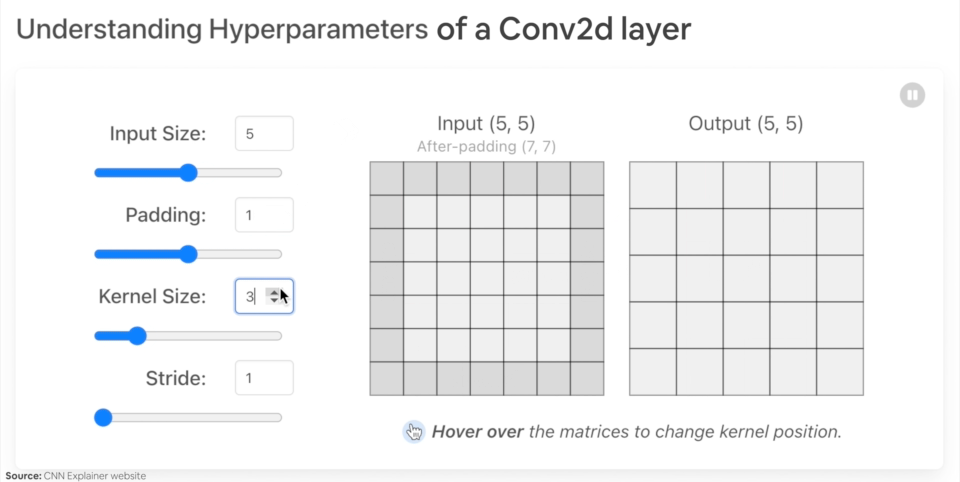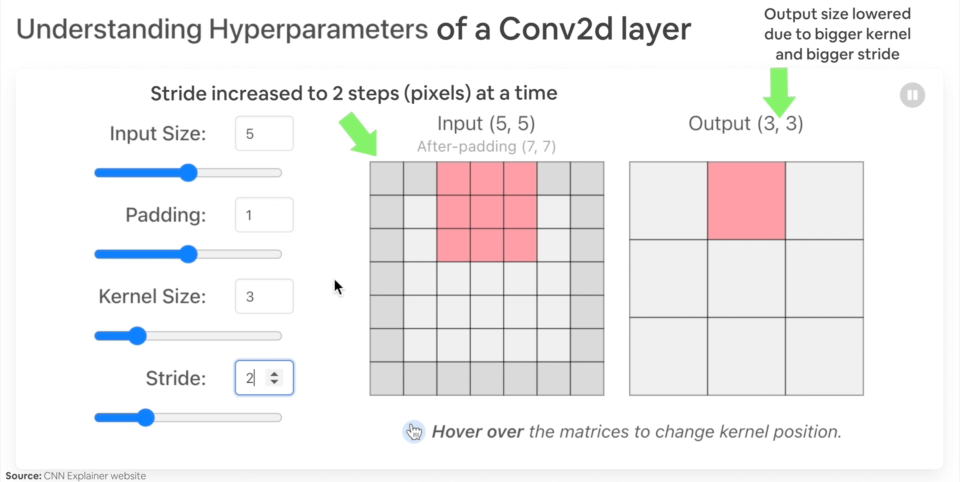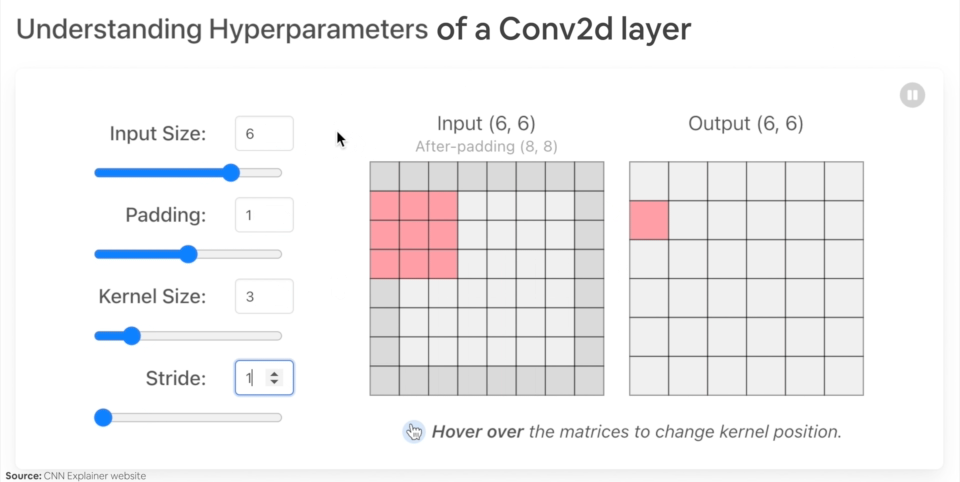
改变 nn.Conv2d() 层超参数的示例。
torch.manual_seed(42)
# Create a convolutional layer with same dimensions as TinyVGG
# (try changing any of the parameters and see what happens)
conv_layer = nn.Conv2d(in_channels=3,
out_channels=10,
kernel_size=3,
stride=1,
padding=0) # also try using "valid" or "same" here
# Pass the data through the convolutional layer
conv_layer(test_image) # Note: If running PyTorch <1.11.0, this will error because of shape issues (nn.Conv.2d() expects a 4d tensor as input)
tensor([[[ 1.5396, 0.0516, 0.6454, ..., -0.3673, 0.8711, 0.4256],
[ 0.3662, 1.0114, -0.5997, ..., 0.8983, 0.2809, -0.2741],
[ 1.2664, -1.4054, 0.3727, ..., -0.3409, 1.2191, -0.0463],
...,
[-0.1541, 0.5132, -0.3624, ..., -0.2360, -0.4609, -0.0035],
[ 0.2981, -0.2432, 1.5012, ..., -0.6289, -0.7283, -0.5767],
[-0.0386, -0.0781, -0.0388, ..., 0.2842, 0.4228, -0.1802]],
[[-0.2840, -0.0319, -0.4455, ..., -0.7956, 1.5599, -1.2449],
[ 0.2753, -0.1262, -0.6541, ..., -0.2211, 0.1999, -0.8856],
[-0.5404, -1.5489, 0.0249, ..., -0.5932, -1.0913, -0.3849],
...,
[ 0.3870, -0.4064, -0.8236, ..., 0.1734, -0.4330, -0.4951],
[-0.1984, -0.6386, 1.0263, ..., -0.9401, -0.0585, -0.7833],
[-0.6306, -0.2052, -0.3694, ..., -1.3248, 0.2456, -0.7134]],
[[ 0.4414, 0.5100, 0.4846, ..., -0.8484, 0.2638, 1.1258],
[ 0.8117, 0.3191, -0.0157, ..., 1.2686, 0.2319, 0.5003],
[ 0.3212, 0.0485, -0.2581, ..., 0.2258, 0.2587, -0.8804],
...,
[-0.1144, -0.1869, 0.0160, ..., -0.8346, 0.0974, 0.8421],
[ 0.2941, 0.4417, 0.5866, ..., -0.1224, 0.4814, -0.4799],
[ 0.6059, -0.0415, -0.2028, ..., 0.1170, 0.2521, -0.4372]],
...,
[[-0.2560, -0.0477, 0.6380, ..., 0.6436, 0.7553, -0.7055],
[ 1.5595, -0.2209, -0.9486, ..., -0.4876, 0.7754, 0.0750],
[-0.0797, 0.2471, 1.1300, ..., 0.1505, 0.2354, 0.9576],
...,
[ 1.1065, 0.6839, 1.2183, ..., 0.3015, -0.1910, -0.1902],
[-0.3486, -0.7173, -0.3582, ..., 0.4917, 0.7219, 0.1513],
[ 0.0119, 0.1017, 0.7839, ..., -0.3752, -0.8127, -0.1257]],
[[ 0.3841, 1.1322, 0.1620, ..., 0.7010, 0.0109, 0.6058],
[ 0.1664, 0.1873, 1.5924, ..., 0.3733, 0.9096, -0.5399],
[ 0.4094, -0.0861, -0.7935, ..., -0.1285, -0.9932, -0.3013],
...,
[ 0.2688, -0.5630, -1.1902, ..., 0.4493, 0.5404, -0.0103],
[ 0.0535, 0.4411, 0.5313, ..., 0.0148, -1.0056, 0.3759],
[ 0.3031, -0.1590, -0.1316, ..., -0.5384, -0.4271, -0.4876]],
[[-1.1865, -0.7280, -1.2331, ..., -0.9013, -0.0542, -1.5949],
[-0.6345, -0.5920, 0.5326, ..., -1.0395, -0.7963, -0.0647],
[-0.1132, 0.5166, 0.2569, ..., 0.5595, -1.6881, 0.9485],
...,
[-0.0254, -0.2669, 0.1927, ..., -0.2917, 0.1088, -0.4807],
[-0.2609, -0.2328, 0.1404, ..., -0.1325, -0.8436, -0.7524],
[-1.1399, -0.1751, -0.8705, ..., 0.1589, 0.3377, 0.3493]]],
grad_fn=<SqueezeBackward1>)
如果我们尝试传递单张图片,会遇到形状不匹配的错误:
RuntimeError: Expected 4-dimensional input for 4-dimensional weight [10, 3, 3, 3], but got 3-dimensional input of size [3, 64, 64] instead注意: 如果你使用的是 PyTorch 1.11.0 及以上版本,则不会出现此错误。
这是因为我们的 nn.Conv2d() 层期望输入一个形状为 (N, C, H, W) 或 [batch_size, color_channels, height, width] 的 4 维张量。
目前我们的单张图片 test_image 只有 [color_channels, height, width] 或 [3, 64, 64] 的形状。
我们可以通过使用 test_image.unsqueeze(dim=0) 为 N 添加一个额外的维度来解决这个问题。
# Add extra dimension to test image
test_image.unsqueeze(dim=0).shape
torch.Size([1, 3, 64, 64])
# Pass test image with extra dimension through conv_layer
conv_layer(test_image.unsqueeze(dim=0)).shape
torch.Size([1, 10, 62, 62])
嗯,注意到我们的形状(与CNN Explainer上TinyVGG的第一层形状相同)发生了变化,我们得到了不同的通道大小以及不同的像素大小。
如果我们改变conv_layer的值会怎样呢?
torch.manual_seed(42)
# Create a new conv_layer with different values (try setting these to whatever you like)
conv_layer_2 = nn.Conv2d(in_channels=3, # same number of color channels as our input image
out_channels=10,
kernel_size=(5, 5), # kernel is usually a square so a tuple also works
stride=2,
padding=0)
# Pass single image through new conv_layer_2 (this calls nn.Conv2d()'s forward() method on the input)
conv_layer_2(test_image.unsqueeze(dim=0)).shape
torch.Size([1, 10, 30, 30])
哇,我们又得到了一个新的形状变化。
现在我们的图像形状是 [1, 10, 30, 30](如果你使用不同的值,形状会有所不同),或者可以表示为 [batch_size=1, color_channels=10, height=30, width=30]。
这是怎么回事呢?
在幕后,我们的 nn.Conv2d() 正在压缩存储在图像中的信息。
它通过在输入(我们的测试图像)上执行与其内部参数相关的操作来实现这一点。
这一目标与我们之前构建的所有其他神经网络类似。
数据输入后,各层尝试更新其内部参数(模式),以借助优化器的帮助降低损失函数。
唯一的区别在于不同层如何计算其参数更新,或者用 PyTorch 的术语来说,层中 forward() 方法所执行的操作。
如果我们查看 conv_layer_2.state_dict(),我们会发现与之前类似的权重和偏置设置。
# Check out the conv_layer_2 internal parameters
print(conv_layer_2.state_dict())
OrderedDict([('weight', tensor([[[[ 0.0883, 0.0958, -0.0271, 0.1061, -0.0253],
[ 0.0233, -0.0562, 0.0678, 0.1018, -0.0847],
[ 0.1004, 0.0216, 0.0853, 0.0156, 0.0557],
[-0.0163, 0.0890, 0.0171, -0.0539, 0.0294],
[-0.0532, -0.0135, -0.0469, 0.0766, -0.0911]],
[[-0.0532, -0.0326, -0.0694, 0.0109, -0.1140],
[ 0.1043, -0.0981, 0.0891, 0.0192, -0.0375],
[ 0.0714, 0.0180, 0.0933, 0.0126, -0.0364],
[ 0.0310, -0.0313, 0.0486, 0.1031, 0.0667],
[-0.0505, 0.0667, 0.0207, 0.0586, -0.0704]],
[[-0.1143, -0.0446, -0.0886, 0.0947, 0.0333],
[ 0.0478, 0.0365, -0.0020, 0.0904, -0.0820],
[ 0.0073, -0.0788, 0.0356, -0.0398, 0.0354],
[-0.0241, 0.0958, -0.0684, -0.0689, -0.0689],
[ 0.1039, 0.0385, 0.1111, -0.0953, -0.1145]]],
[[[-0.0903, -0.0777, 0.0468, 0.0413, 0.0959],
[-0.0596, -0.0787, 0.0613, -0.0467, 0.0701],
[-0.0274, 0.0661, -0.0897, -0.0583, 0.0352],
[ 0.0244, -0.0294, 0.0688, 0.0785, -0.0837],
[-0.0616, 0.1057, -0.0390, -0.0409, -0.1117]],
[[-0.0661, 0.0288, -0.0152, -0.0838, 0.0027],
[-0.0789, -0.0980, -0.0636, -0.1011, -0.0735],
[ 0.1154, 0.0218, 0.0356, -0.1077, -0.0758],
[-0.0384, 0.0181, -0.1016, -0.0498, -0.0691],
[ 0.0003, -0.0430, -0.0080, -0.0782, -0.0793]],
[[-0.0674, -0.0395, -0.0911, 0.0968, -0.0229],
[ 0.0994, 0.0360, -0.0978, 0.0799, -0.0318],
[-0.0443, -0.0958, -0.1148, 0.0330, -0.0252],
[ 0.0450, -0.0948, 0.0857, -0.0848, -0.0199],
[ 0.0241, 0.0596, 0.0932, 0.1052, -0.0916]]],
[[[ 0.0291, -0.0497, -0.0127, -0.0864, 0.1052],
[-0.0847, 0.0617, 0.0406, 0.0375, -0.0624],
[ 0.1050, 0.0254, 0.0149, -0.1018, 0.0485],
[-0.0173, -0.0529, 0.0992, 0.0257, -0.0639],
[-0.0584, -0.0055, 0.0645, -0.0295, -0.0659]],
[[-0.0395, -0.0863, 0.0412, 0.0894, -0.1087],
[ 0.0268, 0.0597, 0.0209, -0.0411, 0.0603],
[ 0.0607, 0.0432, -0.0203, -0.0306, 0.0124],
[-0.0204, -0.0344, 0.0738, 0.0992, -0.0114],
[-0.0259, 0.0017, -0.0069, 0.0278, 0.0324]],
[[-0.1049, -0.0426, 0.0972, 0.0450, -0.0057],
[-0.0696, -0.0706, -0.1034, -0.0376, 0.0390],
[ 0.0736, 0.0533, -0.1021, -0.0694, -0.0182],
[ 0.1117, 0.0167, -0.0299, 0.0478, -0.0440],
[-0.0747, 0.0843, -0.0525, -0.0231, -0.1149]]],
[[[ 0.0773, 0.0875, 0.0421, -0.0805, -0.1140],
[-0.0938, 0.0861, 0.0554, 0.0972, 0.0605],
[ 0.0292, -0.0011, -0.0878, -0.0989, -0.1080],
[ 0.0473, -0.0567, -0.0232, -0.0665, -0.0210],
[-0.0813, -0.0754, 0.0383, -0.0343, 0.0713]],
[[-0.0370, -0.0847, -0.0204, -0.0560, -0.0353],
[-0.1099, 0.0646, -0.0804, 0.0580, 0.0524],
[ 0.0825, -0.0886, 0.0830, -0.0546, 0.0428],
[ 0.1084, -0.0163, -0.0009, -0.0266, -0.0964],
[ 0.0554, -0.1146, 0.0717, 0.0864, 0.1092]],
[[-0.0272, -0.0949, 0.0260, 0.0638, -0.1149],
[-0.0262, -0.0692, -0.0101, -0.0568, -0.0472],
[-0.0367, -0.1097, 0.0947, 0.0968, -0.0181],
[-0.0131, -0.0471, -0.1043, -0.1124, 0.0429],
[-0.0634, -0.0742, -0.0090, -0.0385, -0.0374]]],
[[[ 0.0037, -0.0245, -0.0398, -0.0553, -0.0940],
[ 0.0968, -0.0462, 0.0306, -0.0401, 0.0094],
[ 0.1077, 0.0532, -0.1001, 0.0458, 0.1096],
[ 0.0304, 0.0774, 0.1138, -0.0177, 0.0240],
[-0.0803, -0.0238, 0.0855, 0.0592, -0.0731]],
[[-0.0926, -0.0789, -0.1140, -0.0891, -0.0286],
[ 0.0779, 0.0193, -0.0878, -0.0926, 0.0574],
[-0.0859, -0.0142, 0.0554, -0.0534, -0.0126],
[-0.0101, -0.0273, -0.0585, -0.1029, -0.0933],
[-0.0618, 0.1115, -0.0558, -0.0775, 0.0280]],
[[ 0.0318, 0.0633, 0.0878, 0.0643, -0.1145],
[ 0.0102, 0.0699, -0.0107, -0.0680, 0.1101],
[-0.0432, -0.0657, -0.1041, 0.0052, 0.0512],
[ 0.0256, 0.0228, -0.0876, -0.1078, 0.0020],
[ 0.1053, 0.0666, -0.0672, -0.0150, -0.0851]]],
[[[-0.0557, 0.0209, 0.0629, 0.0957, -0.1060],
[ 0.0772, -0.0814, 0.0432, 0.0977, 0.0016],
[ 0.1051, -0.0984, -0.0441, 0.0673, -0.0252],
[-0.0236, -0.0481, 0.0796, 0.0566, 0.0370],
[-0.0649, -0.0937, 0.0125, 0.0342, -0.0533]],
[[-0.0323, 0.0780, 0.0092, 0.0052, -0.0284],
[-0.1046, -0.1086, -0.0552, -0.0587, 0.0360],
[-0.0336, -0.0452, 0.1101, 0.0402, 0.0823],
[-0.0559, -0.0472, 0.0424, -0.0769, -0.0755],
[-0.0056, -0.0422, -0.0866, 0.0685, 0.0929]],
[[ 0.0187, -0.0201, -0.1070, -0.0421, 0.0294],
[ 0.0544, -0.0146, -0.0457, 0.0643, -0.0920],
[ 0.0730, -0.0448, 0.0018, -0.0228, 0.0140],
[-0.0349, 0.0840, -0.0030, 0.0901, 0.1110],
[-0.0563, -0.0842, 0.0926, 0.0905, -0.0882]]],
[[[-0.0089, -0.1139, -0.0945, 0.0223, 0.0307],
[ 0.0245, -0.0314, 0.1065, 0.0165, -0.0681],
[-0.0065, 0.0277, 0.0404, -0.0816, 0.0433],
[-0.0590, -0.0959, -0.0631, 0.1114, 0.0987],
[ 0.1034, 0.0678, 0.0872, -0.0155, -0.0635]],
[[ 0.0577, -0.0598, -0.0779, -0.0369, 0.0242],
[ 0.0594, -0.0448, -0.0680, 0.0156, -0.0681],
[-0.0752, 0.0602, -0.0194, 0.1055, 0.1123],
[ 0.0345, 0.0397, 0.0266, 0.0018, -0.0084],
[ 0.0016, 0.0431, 0.1074, -0.0299, -0.0488]],
[[-0.0280, -0.0558, 0.0196, 0.0862, 0.0903],
[ 0.0530, -0.0850, -0.0620, -0.0254, -0.0213],
[ 0.0095, -0.1060, 0.0359, -0.0881, -0.0731],
[-0.0960, 0.1006, -0.1093, 0.0871, -0.0039],
[-0.0134, 0.0722, -0.0107, 0.0724, 0.0835]]],
[[[-0.1003, 0.0444, 0.0218, 0.0248, 0.0169],
[ 0.0316, -0.0555, -0.0148, 0.1097, 0.0776],
[-0.0043, -0.1086, 0.0051, -0.0786, 0.0939],
[-0.0701, -0.0083, -0.0256, 0.0205, 0.1087],
[ 0.0110, 0.0669, 0.0896, 0.0932, -0.0399]],
[[-0.0258, 0.0556, -0.0315, 0.0541, -0.0252],
[-0.0783, 0.0470, 0.0177, 0.0515, 0.1147],
[ 0.0788, 0.1095, 0.0062, -0.0993, -0.0810],
[-0.0717, -0.1018, -0.0579, -0.1063, -0.1065],
[-0.0690, -0.1138, -0.0709, 0.0440, 0.0963]],
[[-0.0343, -0.0336, 0.0617, -0.0570, -0.0546],
[ 0.0711, -0.1006, 0.0141, 0.1020, 0.0198],
[ 0.0314, -0.0672, -0.0016, 0.0063, 0.0283],
[ 0.0449, 0.1003, -0.0881, 0.0035, -0.0577],
[-0.0913, -0.0092, -0.1016, 0.0806, 0.0134]]],
[[[-0.0622, 0.0603, -0.1093, -0.0447, -0.0225],
[-0.0981, -0.0734, -0.0188, 0.0876, 0.1115],
[ 0.0735, -0.0689, -0.0755, 0.1008, 0.0408],
[ 0.0031, 0.0156, -0.0928, -0.0386, 0.1112],
[-0.0285, -0.0058, -0.0959, -0.0646, -0.0024]],
[[-0.0717, -0.0143, 0.0470, -0.1130, 0.0343],
[-0.0763, -0.0564, 0.0443, 0.0918, -0.0316],
[-0.0474, -0.1044, -0.0595, -0.1011, -0.0264],
[ 0.0236, -0.1082, 0.1008, 0.0724, -0.1130],
[-0.0552, 0.0377, -0.0237, -0.0126, -0.0521]],
[[ 0.0927, -0.0645, 0.0958, 0.0075, 0.0232],
[ 0.0901, -0.0190, -0.0657, -0.0187, 0.0937],
[-0.0857, 0.0262, -0.1135, 0.0605, 0.0427],
[ 0.0049, 0.0496, 0.0001, 0.0639, -0.0914],
[-0.0170, 0.0512, 0.1150, 0.0588, -0.0840]]],
[[[ 0.0888, -0.0257, -0.0247, -0.1050, -0.0182],
[ 0.0817, 0.0161, -0.0673, 0.0355, -0.0370],
[ 0.1054, -0.1002, -0.0365, -0.1115, -0.0455],
[ 0.0364, 0.1112, 0.0194, 0.1132, 0.0226],
[ 0.0667, 0.0926, 0.0965, -0.0646, 0.1062]],
[[ 0.0699, -0.0540, -0.0551, -0.0969, 0.0290],
[-0.0936, 0.0488, 0.0365, -0.1003, 0.0315],
[-0.0094, 0.0527, 0.0663, -0.1148, 0.1059],
[ 0.0968, 0.0459, -0.1055, -0.0412, -0.0335],
[-0.0297, 0.0651, 0.0420, 0.0915, -0.0432]],
[[ 0.0389, 0.0411, -0.0961, -0.1120, -0.0599],
[ 0.0790, -0.1087, -0.1005, 0.0647, 0.0623],
[ 0.0950, -0.0872, -0.0845, 0.0592, 0.1004],
[ 0.0691, 0.0181, 0.0381, 0.1096, -0.0745],
[-0.0524, 0.0808, -0.0790, -0.0637, 0.0843]]]])), ('bias', tensor([ 0.0364, 0.0373, -0.0489, -0.0016, 0.1057, -0.0693, 0.0009, 0.0549,
-0.0797, 0.1121]))])
看那!一堆随机的数字,对应着权重和偏置张量。
这些张量的形状是由我们在设置 nn.Conv2d() 时传入的输入参数决定的。
一起来检查一下吧。
# Get shapes of weight and bias tensors within conv_layer_2
print(f"conv_layer_2 weight shape: \n{conv_layer_2.weight.shape} -> [out_channels=10, in_channels=3, kernel_size=5, kernel_size=5]")
print(f"\nconv_layer_2 bias shape: \n{conv_layer_2.bias.shape} -> [out_channels=10]")
conv_layer_2 weight shape: torch.Size([10, 3, 5, 5]) -> [out_channels=10, in_channels=3, kernel_size=5, kernel_size=5] conv_layer_2 bias shape: torch.Size([10]) -> [out_channels=10]
问题: 我们应该如何设置
nn.Conv2d()层的参数?这是一个好问题。但与机器学习中的许多其他事物类似,这些参数的值并非固定不变(并且请记住,因为这些值是我们自己可以设置的,所以它们被称为“超参数”)。
找出最佳方法是通过尝试不同的值,看看它们如何影响模型的性能。
或者更好的是,找到一个与你面临的问题类似的有效示例(就像我们在 TinyVGG 中所做的那样)并进行复制。
我们在这里使用的是一种与之前看到的不同的层。
但前提仍然相同:从随机数开始,并更新它们以更好地表示数据。
7.2 逐步解析 nn.MaxPool2d()¶
接下来,让我们看看当数据通过 nn.MaxPool2d() 时会发生什么。
# Print out original image shape without and with unsqueezed dimension
print(f"Test image original shape: {test_image.shape}")
print(f"Test image with unsqueezed dimension: {test_image.unsqueeze(dim=0).shape}")
# Create a sample nn.MaxPoo2d() layer
max_pool_layer = nn.MaxPool2d(kernel_size=2)
# Pass data through just the conv_layer
test_image_through_conv = conv_layer(test_image.unsqueeze(dim=0))
print(f"Shape after going through conv_layer(): {test_image_through_conv.shape}")
# Pass data through the max pool layer
test_image_through_conv_and_max_pool = max_pool_layer(test_image_through_conv)
print(f"Shape after going through conv_layer() and max_pool_layer(): {test_image_through_conv_and_max_pool.shape}")
Test image original shape: torch.Size([3, 64, 64]) Test image with unsqueezed dimension: torch.Size([1, 3, 64, 64]) Shape after going through conv_layer(): torch.Size([1, 10, 62, 62]) Shape after going through conv_layer() and max_pool_layer(): torch.Size([1, 10, 31, 31])
注意观察在 nn.MaxPool2d() 层内外发生的变化。
nn.MaxPool2d() 层的 kernel_size 会影响输出形状的大小。
在我们的例子中,形状从 62x62 的图像减半为 31x31 的图像。
让我们用一个更小的张量来看看这个过程。
torch.manual_seed(42)
# Create a random tensor with a similiar number of dimensions to our images
random_tensor = torch.randn(size=(1, 1, 2, 2))
print(f"Random tensor:\n{random_tensor}")
print(f"Random tensor shape: {random_tensor.shape}")
# Create a max pool layer
max_pool_layer = nn.MaxPool2d(kernel_size=2) # see what happens when you change the kernel_size value
# Pass the random tensor through the max pool layer
max_pool_tensor = max_pool_layer(random_tensor)
print(f"\nMax pool tensor:\n{max_pool_tensor} <- this is the maximum value from random_tensor")
print(f"Max pool tensor shape: {max_pool_tensor.shape}")
Random tensor:
tensor([[[[0.3367, 0.1288],
[0.2345, 0.2303]]]])
Random tensor shape: torch.Size([1, 1, 2, 2])
Max pool tensor:
tensor([[[[0.3367]]]]) <- this is the maximum value from random_tensor
Max pool tensor shape: torch.Size([1, 1, 1, 1])
注意random_tensor和max_pool_tensor之间的最后两个维度,它们从[2, 2]变成了[1, 1]。
本质上,它们被减半了。
而对于nn.MaxPool2d()的不同kernel_size值,这种变化也会有所不同。
还要注意,max_pool_tensor中剩下的值是random_tensor中的最大值。
这里发生了什么?
这是神经网络拼图中另一个重要部分。
本质上,神经网络中的每一层都在尝试将高维空间的数据压缩到低维空间。
换句话说,就是从大量的数字(原始数据)中学习这些数字中的模式,这些模式既具有预测性,同时又比原始值更小。
从人工智能的角度来看,你可以认为神经网络的整个目标就是压缩信息。
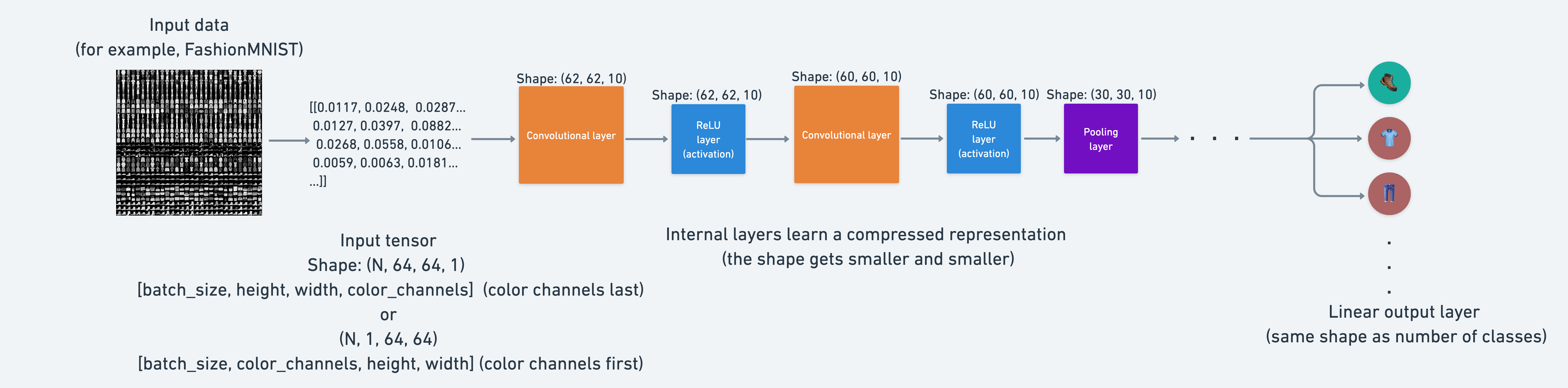
这意味着,从神经网络的角度来看,智能就是压缩。
这就是使用nn.MaxPool2d()层的想法:从张量的一部分中取最大值,而忽略其余部分。
本质上,降低张量的维度,同时仍然保留(希望)大部分信息。
对于nn.Conv2d()层也是如此。
只不过不是只取最大值,nn.Conv2d()层对数据执行卷积操作(在CNN Explainer网页上可以看到这个操作)。
练习: 你认为
nn.AvgPool2d()层是做什么的?尝试像我们上面那样创建一个随机张量并传递给它。检查输入和输出的形状以及输入和输出的值。
额外课程: 查找“最常见的卷积神经网络”,你发现了哪些架构?其中有没有包含在
torchvision.models库中的?你认为你可以用这些做什么?
7.3 为 model_2 设置损失函数和优化器¶
我们已经充分了解了第一个卷积神经网络的各个层。
但请记住,如果某些内容仍然不清晰,可以尝试从小处着手。
选择模型中的一个单独层,传递一些数据给它,看看会发生什么。
现在,是时候继续前进并开始训练了!
让我们设置一个损失函数和一个优化器。
我们将使用之前的函数,nn.CrossEntropyLoss() 作为损失函数(因为我们处理的是多类别分类数据)。
并且使用 torch.optim.SGD() 作为优化器,以学习率 0.1 来优化 model_2.parameters()。
# Setup loss and optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(params=model_2.parameters(),
lr=0.1)
7.4 使用训练和测试函数训练和测试 model_2¶
损失函数和优化器已准备就绪!
是时候进行训练和测试了。
我们将使用之前创建的 train_step() 和 test_step() 函数。
我们还将记录时间,以便与其他模型进行比较。
torch.manual_seed(42)
# Measure time
from timeit import default_timer as timer
train_time_start_model_2 = timer()
# Train and test model
epochs = 3
for epoch in tqdm(range(epochs)):
print(f"Epoch: {epoch}\n---------")
train_step(data_loader=train_dataloader,
model=model_2,
loss_fn=loss_fn,
optimizer=optimizer,
accuracy_fn=accuracy_fn,
device=device
)
test_step(data_loader=test_dataloader,
model=model_2,
loss_fn=loss_fn,
accuracy_fn=accuracy_fn,
device=device
)
train_time_end_model_2 = timer()
total_train_time_model_2 = print_train_time(start=train_time_start_model_2,
end=train_time_end_model_2,
device=device)
0%| | 0/3 [00:00<?, ?it/s]
Epoch: 0 --------- Train loss: 0.59302 | Train accuracy: 78.41% Test loss: 0.39771 | Test accuracy: 86.01% Epoch: 1 --------- Train loss: 0.36149 | Train accuracy: 87.00% Test loss: 0.35713 | Test accuracy: 87.00% Epoch: 2 --------- Train loss: 0.32354 | Train accuracy: 88.28% Test loss: 0.32857 | Test accuracy: 88.38% Train time on cuda: 44.250 seconds
哇!看起来卷积层和最大池化层帮助性能有所提升。
让我们用 eval_model() 函数来评估 model_2 的结果。
# Get model_2 results
model_2_results = eval_model(
model=model_2,
data_loader=test_dataloader,
loss_fn=loss_fn,
accuracy_fn=accuracy_fn
)
model_2_results
{'model_name': 'FashionMNISTModelV2',
'model_loss': 0.3285697102546692,
'model_acc': 88.37859424920129}
8. 比较模型结果和训练时间¶
我们已经训练了三个不同的模型。
model_0- 我们的基准模型,包含两个nn.Linear()层。model_1- 与基准模型设置相同,但在nn.Linear()层之间加入了nn.ReLU()层。model_2- 我们的第一个 CNN 模型,模仿 CNN Explainer 网站上的 TinyVGG 架构。
这是机器学习中的常规做法。
构建多个模型并进行多次训练实验,以找出性能最佳的模型。
让我们将模型结果字典合并到一个 DataFrame 中,并找出结果。
import pandas as pd
compare_results = pd.DataFrame([model_0_results, model_1_results, model_2_results])
compare_results
| model_name | model_loss | model_acc | |
|---|---|---|---|
| 0 | FashionMNISTModelV0 | 0.476639 | 83.426518 |
| 1 | FashionMNISTModelV1 | 0.685001 | 75.019968 |
| 2 | FashionMNISTModelV2 | 0.328570 | 88.378594 |
太好了!
我们还可以添加训练时间值。
# Add training times to results comparison
compare_results["training_time"] = [total_train_time_model_0,
total_train_time_model_1,
total_train_time_model_2]
compare_results
| model_name | model_loss | model_acc | training_time | |
|---|---|---|---|---|
| 0 | FashionMNISTModelV0 | 0.476639 | 83.426518 | 32.348722 |
| 1 | FashionMNISTModelV1 | 0.685001 | 75.019968 | 36.877976 |
| 2 | FashionMNISTModelV2 | 0.328570 | 88.378594 | 44.249765 |
看起来我们的CNN模型(FashionMNISTModelV2)表现最好(损失最低,准确率最高),但训练时间最长。
而我们的基准模型(FashionMNISTModelV0)表现优于model_1(FashionMNISTModelV1)。
性能-速度权衡¶
在机器学习中需要注意的一点是性能-速度权衡。
通常,从更大、更复杂的模型中可以获得更好的性能(就像我们在model_2中所做的那样)。
然而,这种性能提升往往以牺牲训练速度和推理速度为代价。
注意: 你得到的训练时间将很大程度上取决于你使用的硬件。
通常,CPU核心越多,模型在CPU上的训练速度越快。GPU也是如此。
较新的硬件(按年龄计算)通常由于采用了技术进步,训练模型速度更快。
我们来看看可视化结果如何?
# Visualize our model results
compare_results.set_index("model_name")["model_acc"].plot(kind="barh")
plt.xlabel("accuracy (%)")
plt.ylabel("model");

9. 使用最佳模型进行随机预测并评估¶
好的,我们已经将我们的模型相互比较过了,接下来让我们进一步评估表现最佳的模型 model_2。
为此,我们创建一个函数 make_predictions(),在其中我们可以传入模型和一些数据,让模型进行预测。
def make_predictions(model: torch.nn.Module, data: list, device: torch.device = device):
pred_probs = []
model.eval()
with torch.inference_mode():
for sample in data:
# Prepare sample
sample = torch.unsqueeze(sample, dim=0).to(device) # Add an extra dimension and send sample to device
# Forward pass (model outputs raw logit)
pred_logit = model(sample)
# Get prediction probability (logit -> prediction probability)
pred_prob = torch.softmax(pred_logit.squeeze(), dim=0) # note: perform softmax on the "logits" dimension, not "batch" dimension (in this case we have a batch size of 1, so can perform on dim=0)
# Get pred_prob off GPU for further calculations
pred_probs.append(pred_prob.cpu())
# Stack the pred_probs to turn list into a tensor
return torch.stack(pred_probs)
import random
random.seed(42)
test_samples = []
test_labels = []
for sample, label in random.sample(list(test_data), k=9):
test_samples.append(sample)
test_labels.append(label)
# View the first test sample shape and label
print(f"Test sample image shape: {test_samples[0].shape}\nTest sample label: {test_labels[0]} ({class_names[test_labels[0]]})")
Test sample image shape: torch.Size([1, 28, 28]) Test sample label: 5 (Sandal)
# Make predictions on test samples with model 2
pred_probs= make_predictions(model=model_2,
data=test_samples)
# View first two prediction probabilities list
pred_probs[:2]
tensor([[2.4012e-07, 6.5406e-08, 4.8069e-08, 2.1070e-07, 1.4175e-07, 9.9992e-01,
2.1711e-07, 1.6177e-05, 3.7849e-05, 2.7548e-05],
[1.5646e-02, 8.9752e-01, 3.6928e-04, 6.7402e-02, 1.2920e-02, 4.9539e-05,
5.6485e-03, 1.9456e-04, 2.0808e-04, 3.7861e-05]])
现在我们可以使用 make_predictions() 函数来对 test_samples 进行预测。
# Make predictions on test samples with model 2
pred_probs= make_predictions(model=model_2,
data=test_samples)
# View first two prediction probabilities list
pred_probs[:2]
tensor([[2.4012e-07, 6.5406e-08, 4.8069e-08, 2.1070e-07, 1.4175e-07, 9.9992e-01,
2.1711e-07, 1.6177e-05, 3.7849e-05, 2.7548e-05],
[1.5646e-02, 8.9752e-01, 3.6928e-04, 6.7402e-02, 1.2920e-02, 4.9539e-05,
5.6485e-03, 1.9456e-04, 2.0808e-04, 3.7861e-05]])
太棒了!
现在,我们可以通过取 torch.softmax() 激活函数输出的 torch.argmax() 来从预测概率转换到预测标签。
# Turn the prediction probabilities into prediction labels by taking the argmax()
pred_classes = pred_probs.argmax(dim=1)
pred_classes
tensor([5, 1, 7, 4, 3, 0, 4, 7, 1])
# Are our predictions in the same form as our test labels?
test_labels, pred_classes
([5, 1, 7, 4, 3, 0, 4, 7, 1], tensor([5, 1, 7, 4, 3, 0, 4, 7, 1]))
现在我们的预测类别与测试标签格式一致,可以进行比较了。
由于我们处理的是图像数据,让我们坚守数据探索者的座右铭。
“可视化,可视化,可视化!”
# Plot predictions
plt.figure(figsize=(9, 9))
nrows = 3
ncols = 3
for i, sample in enumerate(test_samples):
# Create a subplot
plt.subplot(nrows, ncols, i+1)
# Plot the target image
plt.imshow(sample.squeeze(), cmap="gray")
# Find the prediction label (in text form, e.g. "Sandal")
pred_label = class_names[pred_classes[i]]
# Get the truth label (in text form, e.g. "T-shirt")
truth_label = class_names[test_labels[i]]
# Create the title text of the plot
title_text = f"Pred: {pred_label} | Truth: {truth_label}"
# Check for equality and change title colour accordingly
if pred_label == truth_label:
plt.title(title_text, fontsize=10, c="g") # green text if correct
else:
plt.title(title_text, fontsize=10, c="r") # red text if wrong
plt.axis(False);

哇哦,看起来真不错!
仅仅几十行 PyTorch 代码就能做到这样,已经很不错了!
10. 制作混淆矩阵以进一步评估预测¶
对于分类问题,我们可以使用许多不同的评估指标。
其中最直观的一种是混淆矩阵。
混淆矩阵展示了你的分类模型在预测和真实标签之间的混淆情况。
要制作混淆矩阵,我们将通过以下三个步骤:
- 使用我们训练好的模型
model_2进行预测(混淆矩阵比较预测值和真实标签)。 - 使用
torchmetrics.ConfusionMatrix制作混淆矩阵。 - 使用
mlxtend.plotting.plot_confusion_matrix()绘制混淆矩阵。
首先,让我们使用我们训练好的模型进行预测。
# Import tqdm for progress bar
from tqdm.auto import tqdm
# 1. Make predictions with trained model
y_preds = []
model_2.eval()
with torch.inference_mode():
for X, y in tqdm(test_dataloader, desc="Making predictions"):
# Send data and targets to target device
X, y = X.to(device), y.to(device)
# Do the forward pass
y_logit = model_2(X)
# Turn predictions from logits -> prediction probabilities -> predictions labels
y_pred = torch.softmax(y_logit, dim=1).argmax(dim=1) # note: perform softmax on the "logits" dimension, not "batch" dimension (in this case we have a batch size of 32, so can perform on dim=1)
# Put predictions on CPU for evaluation
y_preds.append(y_pred.cpu())
# Concatenate list of predictions into a tensor
y_pred_tensor = torch.cat(y_preds)
Making predictions: 0%| | 0/313 [00:00<?, ?it/s]
太棒了!
现在我们已经得到了预测结果,让我们继续执行步骤 2 和 3:
2. 使用 torchmetrics.ConfusionMatrix 创建一个混淆矩阵。
3. 使用 mlxtend.plotting.plot_confusion_matrix() 绘制混淆矩阵。
首先,我们需要确保已经安装了 torchmetrics 和 mlxtend(这两个库将帮助我们创建和可视化混淆矩阵)。
注意: 如果你使用的是 Google Colab,默认安装的
mlxtend版本是 0.14.0(截至 2022 年 3 月),然而,为了使用plot_confusion_matrix()函数的参数,我们需要 0.19.0 或更高版本。
# See if torchmetrics exists, if not, install it
try:
import torchmetrics, mlxtend
print(f"mlxtend version: {mlxtend.__version__}")
assert int(mlxtend.__version__.split(".")[1]) >= 19, "mlxtend verison should be 0.19.0 or higher"
except:
!pip install -q torchmetrics -U mlxtend # <- Note: If you're using Google Colab, this may require restarting the runtime
import torchmetrics, mlxtend
print(f"mlxtend version: {mlxtend.__version__}")
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 519.2/519.2 kB 10.8 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.4/1.4 MB 54.9 MB/s eta 0:00:00 mlxtend version: 0.22.0
要绘制混淆矩阵,我们需要确保安装了 0.19.0 或更高版本的 mlxtend。
# Import mlxtend upgraded version
import mlxtend
print(mlxtend.__version__)
assert int(mlxtend.__version__.split(".")[1]) >= 19 # should be version 0.19.0 or higher
0.22.0
torchmetrics 和 mlxtend 已安装,让我们来创建一个混淆矩阵!
首先,我们将创建一个 torchmetrics.ConfusionMatrix 实例,并通过设置 num_classes=len(class_names) 来告诉它我们有多少个类别。
然后,我们将通过传递我们的模型预测(preds=y_pred_tensor)和目标(target=test_data.targets)来创建一个以张量格式表示的混淆矩阵。
最后,我们可以使用 mlxtend.plotting 中的 plot_confusion_matrix() 函数来绘制我们的混淆矩阵。
from torchmetrics import ConfusionMatrix
from mlxtend.plotting import plot_confusion_matrix
# 2. Setup confusion matrix instance and compare predictions to targets
confmat = ConfusionMatrix(num_classes=len(class_names), task='multiclass')
confmat_tensor = confmat(preds=y_pred_tensor,
target=test_data.targets)
# 3. Plot the confusion matrix
fig, ax = plot_confusion_matrix(
conf_mat=confmat_tensor.numpy(), # matplotlib likes working with NumPy
class_names=class_names, # turn the row and column labels into class names
figsize=(10, 7)
);

哇!看起来不错吧?
我们可以看到我们的模型表现得相当好,因为大多数深色方块都沿着从左上角到右下角的对角线分布(理想的模型在这些方块中只有值,其他地方都是0)。
模型在相似类别上最容易混淆,例如,将实际标记为“衬衫”的图像预测为“套头衫”。
同样地,对于实际标记为“T恤/上衣”的类别,模型也会预测为“衬衫”。
这种信息通常比单一的准确度指标更有帮助,因为它告诉我们模型在哪些地方出错了。
它还暗示了模型可能在哪些地方出错的原因。
模型有时将标记为“T恤/上衣”的图像预测为“衬衫”是可以理解的。
我们可以利用这种信息进一步检查我们的模型和数据,看看如何改进。
练习: 使用训练好的
model_2对测试 FashionMNIST 数据集进行预测。然后绘制一些模型预测错误的情况,并显示图像应有的标签。在可视化这些预测后,你认为是模型错误还是数据错误?也就是说,模型能否做得更好,还是数据的标签过于接近(例如,“衬衫”标签与“T恤/上衣”过于接近)?
11. 保存和加载最佳性能模型¶
让我们通过保存和加载我们性能最好的模型来结束这一部分。
回顾笔记本01,我们可以使用以下组合来保存和加载PyTorch模型:
torch.save- 用于保存整个PyTorch模型或模型的state_dict()。torch.load- 用于加载已保存的PyTorch对象。torch.nn.Module.load_state_dict()- 用于将已保存的state_dict()加载到现有模型实例中。
你可以在PyTorch保存和加载模型文档中了解更多关于这三者的信息。
现在,让我们保存model_2的state_dict(),然后将其加载回来并进行评估,以确保保存和加载过程正确无误。
from pathlib import Path
# Create models directory (if it doesn't already exist), see: https://docs.python.org/3/library/pathlib.html#pathlib.Path.mkdir
MODEL_PATH = Path("models")
MODEL_PATH.mkdir(parents=True, # create parent directories if needed
exist_ok=True # if models directory already exists, don't error
)
# Create model save path
MODEL_NAME = "03_pytorch_computer_vision_model_2.pth"
MODEL_SAVE_PATH = MODEL_PATH / MODEL_NAME
# Save the model state dict
print(f"Saving model to: {MODEL_SAVE_PATH}")
torch.save(obj=model_2.state_dict(), # only saving the state_dict() only saves the learned parameters
f=MODEL_SAVE_PATH)
Saving model to: models/03_pytorch_computer_vision_model_2.pth
现在我们已经有了一个保存的模型 state_dict(),可以使用 load_state_dict() 和 torch.load() 的组合将其加载回来。
由于我们使用的是 load_state_dict(),因此需要创建一个新的 FashionMNISTModelV2() 实例,并使用与保存的模型 state_dict() 相同的输入参数。
# Create a new instance of FashionMNISTModelV2 (the same class as our saved state_dict())
# Note: loading model will error if the shapes here aren't the same as the saved version
loaded_model_2 = FashionMNISTModelV2(input_shape=1,
hidden_units=10, # try changing this to 128 and seeing what happens
output_shape=10)
# Load in the saved state_dict()
loaded_model_2.load_state_dict(torch.load(f=MODEL_SAVE_PATH))
# Send model to GPU
loaded_model_2 = loaded_model_2.to(device)
现在我们已经有了一个加载好的模型,我们可以使用 eval_model() 来评估它,确保其参数在保存之前与 model_2 的工作方式相似。
# 示例代码,假设 eval_model 是一个自定义的评估函数
def eval_model(model):
# 评估模型的代码
pass
eval_model(loaded_model)
# Evaluate loaded model
torch.manual_seed(42)
loaded_model_2_results = eval_model(
model=loaded_model_2,
data_loader=test_dataloader,
loss_fn=loss_fn,
accuracy_fn=accuracy_fn
)
loaded_model_2_results
{'model_name': 'FashionMNISTModelV2',
'model_loss': 0.3285697102546692,
'model_acc': 88.37859424920129}
这些结果看起来和 model_2_results 一样吗?
model_2_results
{'model_name': 'FashionMNISTModelV2',
'model_loss': 0.3285697102546692,
'model_acc': 88.37859424920129}
我们可以使用 torch.isclose() 来判断两个张量是否接近,并通过参数 atol(绝对容差)和 rtol(相对容差)传递接近程度的容差水平。
如果我们的模型结果接近,torch.isclose() 的输出应该是 true。
# Check to see if results are close to each other (if they are very far away, there may be an error)
torch.isclose(torch.tensor(model_2_results["model_loss"]),
torch.tensor(loaded_model_2_results["model_loss"]),
atol=1e-08, # absolute tolerance
rtol=0.0001) # relative tolerance
tensor(True)
练习¶
所有练习都专注于实践上述章节中的代码。
你应该能够通过参考每个章节或遵循链接的资源来完成这些练习。
所有练习应使用设备无关代码完成。
资源:
- 第03章的练习模板笔记本
- 第03章的示例解决方案笔记本(在查看此内容之前尝试练习)
- 列出当前工业界正在使用的三个计算机视觉领域。
- 搜索“机器学习中的过拟合是什么”,并写下你找到的句子。
- 搜索“防止机器学习中过拟合的方法”,写下你找到的三种方法及其简要描述。注意: 这些方法有很多,不必担心全部,只需选择三种并从它们开始。
- 花20分钟阅读并点击CNN解释器网站。
- 使用“上传”按钮上传你自己的示例图像,并观察图像通过CNN的每一层时发生的变化。
- 加载
torchvision.datasets.MNIST()训练和测试数据集。 - 可视化MNIST训练数据集中的至少五个不同样本。
- 使用
torch.utils.data.DataLoader将MNIST训练和测试数据集转换为数据加载器,设置batch_size=32。 - 重新创建本笔记本中使用的
model_2(来自CNN解释器网站的相同模型,也称为TinyVGG),使其能够适应MNIST数据集。 - 在你构建的模型上进行训练,分别在CPU和GPU上进行,并比较两者的耗时。
- 使用你训练好的模型进行预测,并可视化至少五个预测结果,比较预测值与目标标签。
- 绘制混淆矩阵,比较模型的预测结果与真实标签。
- 创建形状为
[1, 3, 64, 64]的随机张量,并将其通过nn.Conv2d()层,尝试不同的超参数设置(这些设置可以任意选择),如果kernel_size参数增加或减少,你注意到了什么? - 使用类似于本笔记本中训练的
model_2模型对测试torchvision.datasets.FashionMNIST数据集进行预测。- 然后绘制一些模型预测错误的情况,并展示图像应有的标签。
- 在可视化这些预测后,你认为这是模型错误还是数据错误?
- 也就是说,模型能否做得更好,还是数据的标签过于接近(例如,“衬衫”标签与“T恤/上衣”过于接近)?
额外课程¶
- 观看: MIT的深度计算机视觉介绍讲座。这将为你提供关于卷积神经网络的深刻直觉。
- 花10分钟点击PyTorch视觉库的不同选项,有哪些模块可用?
- 查找“最常见的卷积神经网络”,你发现了哪些架构?其中是否有包含在
torchvision.models库中的?你认为可以用这些做什么? - 对于大量预训练的PyTorch计算机视觉模型以及许多PyTorch计算机视觉功能的扩展,请查看Ross Wightman的PyTorch图像模型库
timm(Torch Image Models)。