02. PyTorch 神经网络分类¶
什么是分类问题?¶
分类问题 涉及预测某事物是某物还是其他物。
例如,你可能想要:
| 问题类型 | 是什么? | 示例 |
|---|---|---|
| 二元分类 | 目标可以是两个选项之一,例如是或否 | 根据健康参数预测某人是否患有心脏病。 |
| 多类分类 | 目标可以是两个以上选项之一 | 判断一张照片是食物、人物还是狗。 |
| 多标签分类 | 目标可以被分配多个选项 | 预测维基百科文章应分配哪些类别(例如数学、科学和哲学)。 |

分类和回归(预测一个数值,在笔记本01中介绍)是机器学习中最常见的两种问题类型。
在本笔记本中,我们将通过几个不同的分类问题来使用 PyTorch 进行实践。
换句话说,就是根据一组输入来预测这组输入属于哪个类别。
我们将要涵盖的内容¶
在本笔记本中,我们将回顾在01. PyTorch 工作流程中介绍的 PyTorch 工作流程。
不同的是,我们不再尝试预测一条直线(预测一个数字,也称为回归问题),而是处理一个分类问题。
具体来说,我们将涵盖以下内容:
| 主题 | 内容 |
|---|---|
| 0. 分类神经网络的架构 | 神经网络几乎可以有任何形状或大小,但它们通常遵循类似的布局。 |
| 1. 准备二元分类数据 | 数据可以是任何东西,但为了入门,我们将创建一个简单的二元分类数据集。 |
| 2. 构建 PyTorch 分类模型 | 在这里,我们将创建一个模型来学习数据中的模式,我们还将选择一个损失函数、优化器,并构建一个特定于分类的训练循环。 |
| 3. 将模型拟合到数据(训练) | 我们已经有了数据和模型,现在让我们让模型(尝试)在(训练)数据中找到模式。 |
| 4. 进行预测和评估模型(推理) | 我们的模型已经在数据中找到了模式,让我们将其发现与实际的(测试)数据进行比较。 |
| 5. 改进模型(从模型角度) | 我们已经训练并评估了一个模型,但它没有正常工作,让我们尝试一些方法来改进它。 |
| 6. 非线性 | 到目前为止,我们的模型只能建模直线,那么非线性(非直线)的线呢? |
| 7. 复制非线性函数 | 我们使用非线性函数来帮助建模非线性数据,但这些函数是什么样子的? |
| 8. 结合多类分类 | 让我们将目前为止为二元分类所做的一切结合起来,解决一个多类分类问题。 |
如何获取帮助?¶
本课程的所有资料都存放在 GitHub 上。
如果你遇到问题,也可以在 讨论页面 上提问。
此外,还有 PyTorch 开发者论坛,这是一个解决所有 PyTorch 相关问题的好地方。
0. 分类神经网络的架构¶
在编写代码之前,我们先来看一下分类神经网络的一般架构。
| 超参数 | 二分类 | 多分类 |
|---|---|---|
输入层形状 (in_features) |
与特征数量相同(例如,心脏病预测中的年龄、性别、身高、体重、吸烟状况共5个特征) | 与二分类相同 |
| 隐藏层 | 问题特定,最少 = 1,最多 = 无限 | 与二分类相同 |
| 每层隐藏层中的神经元数量 | 问题特定,通常为 10 到 512 | 与二分类相同 |
输出层形状 (out_features) |
1(一个类别或另一个类别) | 每个类别 1 个(例如,食物、人物或狗的照片共3个类别) |
| 隐藏层激活函数 | 通常为 ReLU(修正线性单元),但也可以是其他多种激活函数 | 与二分类相同 |
| 输出激活函数 | Sigmoid(在 PyTorch 中为 torch.sigmoid) |
Softmax(在 PyTorch 中为 torch.softmax) |
| 损失函数 | 二元交叉熵(在 PyTorch 中为 torch.nn.BCELoss) |
交叉熵(在 PyTorch 中为 torch.nn.CrossEntropyLoss) |
| 优化器 | SGD(随机梯度下降),Adam(更多选项见 torch.optim) |
与二分类相同 |
当然,这个分类神经网络组件的清单会根据你正在解决的问题而有所不同。
但这些已经足够让你入门了。
我们将在本笔记本中通过这个设置进行实践操作。
from sklearn.datasets import make_circles
# Make 1000 samples
n_samples = 1000
# Create circles
X, y = make_circles(n_samples,
noise=0.03, # a little bit of noise to the dots
random_state=42) # keep random state so we get the same values
好的,现在让我们查看前5个X和y的值。
print(f"First 5 X features:\n{X[:5]}")
print(f"\nFirst 5 y labels:\n{y[:5]}")
First 5 X features: [[ 0.75424625 0.23148074] [-0.75615888 0.15325888] [-0.81539193 0.17328203] [-0.39373073 0.69288277] [ 0.44220765 -0.89672343]] First 5 y labels: [1 1 1 1 0]
看起来每个 y 值对应两个 X 值。
让我们继续遵循数据探索者的座右铭:可视化,可视化,可视化,并将它们放入一个 pandas DataFrame 中。
# Make DataFrame of circle data
import pandas as pd
circles = pd.DataFrame({"X1": X[:, 0],
"X2": X[:, 1],
"label": y
})
circles.head(10)
| X1 | X2 | label | |
|---|---|---|---|
| 0 | 0.754246 | 0.231481 | 1 |
| 1 | -0.756159 | 0.153259 | 1 |
| 2 | -0.815392 | 0.173282 | 1 |
| 3 | -0.393731 | 0.692883 | 1 |
| 4 | 0.442208 | -0.896723 | 0 |
| 5 | -0.479646 | 0.676435 | 1 |
| 6 | -0.013648 | 0.803349 | 1 |
| 7 | 0.771513 | 0.147760 | 1 |
| 8 | -0.169322 | -0.793456 | 1 |
| 9 | -0.121486 | 1.021509 | 0 |
看起来每对 X 特征(X1 和 X2)都有一个标签(y)值,要么是 0,要么是 1。
这告诉我们,我们的问题是二分类,因为只有两个选项(0 或 1)。
每个类有多少个值呢?
# Check different labels
circles.label.value_counts()
1 500 0 500 Name: label, dtype: int64
每组500个,数量均衡。
让我们把它们绘制出来。
# Visualize with a plot
import matplotlib.pyplot as plt
plt.scatter(x=X[:, 0],
y=X[:, 1],
c=y,
cmap=plt.cm.RdYlBu);

好的,看起来我们有一个问题需要解决。
让我们探讨如何构建一个用于将点分类为红色(0)或蓝色(1)的PyTorch神经网络。
注意: 这个数据集通常被认为是机器学习中的玩具问题(一个用于尝试和测试的问题)。
但它代表了分类的关键要点,你有一些以数值形式表示的数据,你希望构建一个能够对其进行分类的模型,在我们的例子中,将其分为红色或蓝色的点。
1.1 输入和输出形状¶
深度学习中最常见的错误之一是形状错误。
如果张量及其操作的形状不匹配,会导致模型出现错误。
在本课程中,我们将多次遇到这些问题。
没有绝对的方法可以确保它们不会发生,它们总会发生。
你可以做的是不断熟悉你正在处理的数据的形状。
我喜欢将其称为输入和输出形状。
问问自己:
“我的输入和输出的形状是什么?”
让我们来找出答案。
# Check the shapes of our features and labels
X.shape, y.shape
((1000, 2), (1000,))
看起来我们在每个数据集的第一维度上匹配了。
这里有 1000 个 X 和 1000 个 y。
但 X 的第二维度是什么?
查看单个样本(特征和标签)的值和形状通常会有所帮助。
这样做将帮助你了解你的模型预期的输入和输出形状。
# View the first example of features and labels
X_sample = X[0]
y_sample = y[0]
print(f"Values for one sample of X: {X_sample} and the same for y: {y_sample}")
print(f"Shapes for one sample of X: {X_sample.shape} and the same for y: {y_sample.shape}")
Values for one sample of X: [0.75424625 0.23148074] and the same for y: 1 Shapes for one sample of X: (2,) and the same for y: ()
这告诉我们,X的第二个维度表示它有两个特征(向量),而y有一个特征(标量)。
我们有两个输入,对应一个输出。
1.2 将数据转换为张量并创建训练集和测试集¶
我们已经研究了数据的输入和输出形状,现在让我们准备数据以便在 PyTorch 中使用并进行建模。
具体来说,我们需要:
- 将数据转换为张量(目前我们的数据是 NumPy 数组,而 PyTorch 更倾向于使用 PyTorch 张量)。
- 将数据分为训练集和测试集(我们将在训练集上训练模型,以学习
X和y之间的模式,然后在测试数据集上评估这些学习到的模式)。
# Turn data into tensors
# Otherwise this causes issues with computations later on
import torch
X = torch.from_numpy(X).type(torch.float)
y = torch.from_numpy(y).type(torch.float)
# View the first five samples
X[:5], y[:5]
(tensor([[ 0.7542, 0.2315],
[-0.7562, 0.1533],
[-0.8154, 0.1733],
[-0.3937, 0.6929],
[ 0.4422, -0.8967]]),
tensor([1., 1., 1., 1., 0.]))
现在我们的数据是张量格式,让我们将其拆分为训练集和测试集。
为此,我们将使用 Scikit-Learn 提供的便捷函数 train_test_split()。
我们将使用 test_size=0.2(80% 用于训练,20% 用于测试),并且由于拆分是随机进行的,让我们使用 random_state=42 以确保拆分结果可复现。
# Split data into train and test sets
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size=0.2, # 20% test, 80% train
random_state=42) # make the random split reproducible
len(X_train), len(X_test), len(y_train), len(y_test)
(800, 200, 800, 200)
太好了!看来我们现在有800个训练样本和200个测试样本。
2. 构建模型¶
我们已经准备好了一些数据,现在是时候构建模型了。
我们将它分解为几个部分:
- 设置设备无关的代码(这样我们的模型可以在CPU或GPU上运行,如果GPU可用的话)。
- 通过子类化
nn.Module构建模型。 - 定义损失函数和优化器。
- 创建训练循环(这一部分将在下一节中进行)。
好消息是,我们在笔记本01中已经完成了上述所有步骤。
不过现在我们将调整它们,使其适用于分类数据集。
让我们从导入PyTorch和 torch.nn 以及设置设备无关的代码开始。
# Standard PyTorch imports
import torch
from torch import nn
# Make device agnostic code
device = "cuda" if torch.cuda.is_available() else "cpu"
device
'cuda'
很好,现在 device 已经设置好了,我们可以将它用于我们创建的任何数据或模型,PyTorch 会自动在 CPU(默认)或 GPU(如果有的话)上处理。
接下来,我们来创建一个模型吧。
我们需要一个模型,能够处理我们的 X 数据作为输入,并生成与我们的 y 数据形状相同的输出。
换句话说,给定 X(特征),我们希望模型预测 y(标签)。
这种具有特征和标签的设置被称为监督学习。因为你的数据会告诉模型在给定某个输入时,输出应该是什么。
要创建这样一个模型,它需要处理 X 和 y 的输入和输出形状。
还记得我说的输入和输出形状很重要吗?在这里我们将看到原因。
让我们创建一个模型类,它:
- 继承自
nn.Module(几乎所有 PyTorch 模型都是nn.Module的子类)。 - 在构造函数中创建两个能够处理
X和y输入和输出形状的nn.Linear层。 - 定义一个包含模型前向传播计算的
forward()方法。 - 实例化模型类,并将其发送到目标
device。
# 1. Construct a model class that subclasses nn.Module
class CircleModelV0(nn.Module):
def __init__(self):
super().__init__()
# 2. Create 2 nn.Linear layers capable of handling X and y input and output shapes
self.layer_1 = nn.Linear(in_features=2, out_features=5) # takes in 2 features (X), produces 5 features
self.layer_2 = nn.Linear(in_features=5, out_features=1) # takes in 5 features, produces 1 feature (y)
# 3. Define a forward method containing the forward pass computation
def forward(self, x):
# Return the output of layer_2, a single feature, the same shape as y
return self.layer_2(self.layer_1(x)) # computation goes through layer_1 first then the output of layer_1 goes through layer_2
# 4. Create an instance of the model and send it to target device
model_0 = CircleModelV0().to(device)
model_0
CircleModelV0( (layer_1): Linear(in_features=2, out_features=5, bias=True) (layer_2): Linear(in_features=5, out_features=1, bias=True) )
这是怎么回事?
我们之前已经见过其中的一些步骤了。
唯一的主要变化在于 self.layer_1 和 self.layer_2 之间发生的事情。
self.layer_1 接受 2 个输入特征 in_features=2 并产生 5 个输出特征 out_features=5。
这被称为有 5 个隐藏单元或神经元。
这一层将输入数据从具有 2 个特征转变为 5 个特征。
为什么要这样做?
这使得模型能够从 5 个数字而不是仅仅 2 个数字中学习模式,潜在地 导致更好的输出。
我说“潜在地”是因为有时候这并不奏效。
在神经网络层中可以使用的隐藏单元数量是一个超参数(一个你可以自己设置的值),并没有固定不变的值你必须使用。
一般来说,越多越好,但也有过犹不及的情况。你选择的数量将取决于你的模型类型和所处理的数据集。
由于我们的数据集很小且简单,我们会保持较小规模。
关于隐藏单元的唯一规则是,下一层,在我们的例子中是 self.layer_2,必须接受与前一层 out_features 相同的 in_features。
这就是为什么 self.layer_2 有 in_features=5,它接受 self.layer_1 的 out_features=5 并对它们进行线性计算,将它们转换为 out_features=1(与 y 的形状相同)。
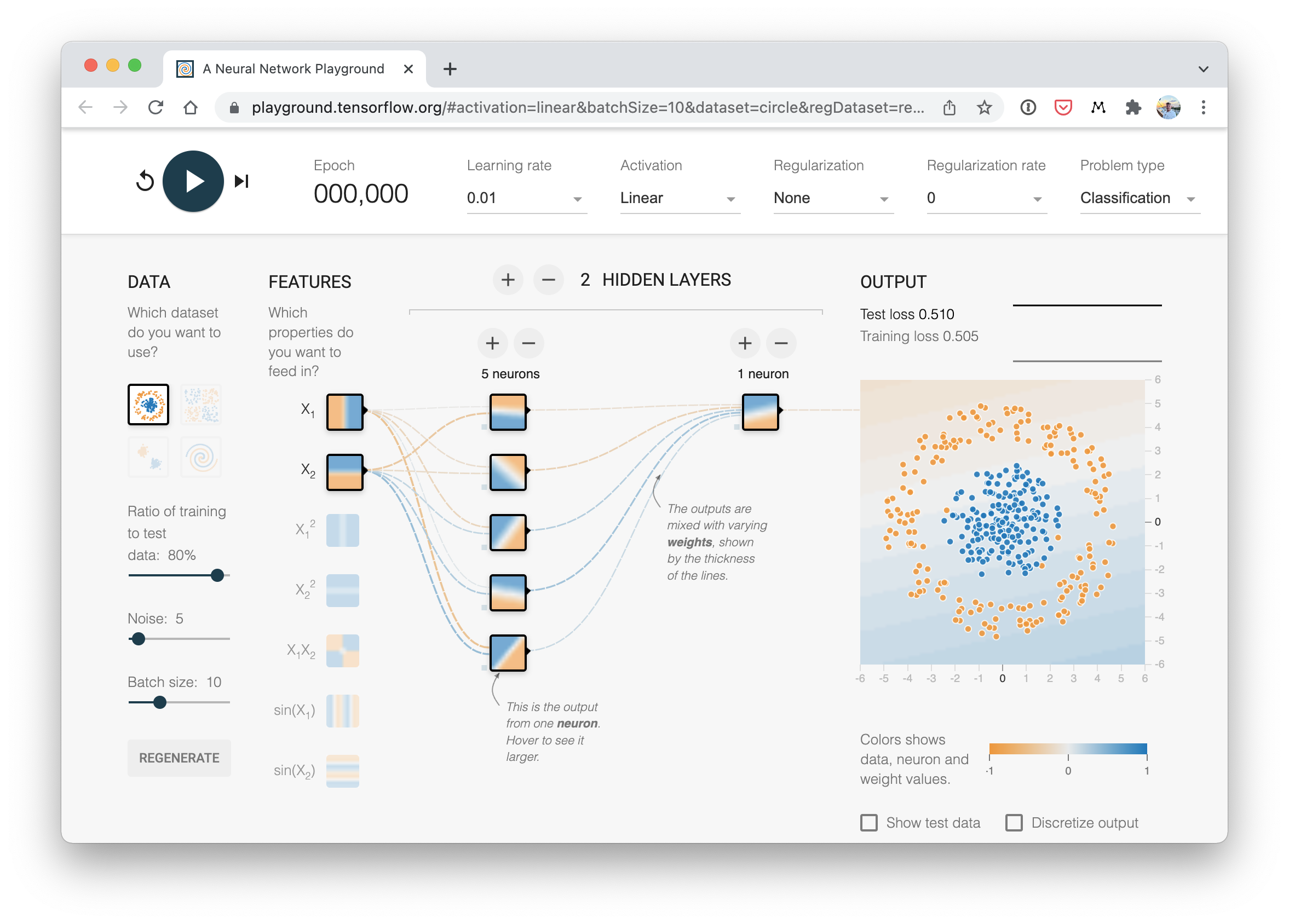 与我们刚刚构建的类似分类神经网络的可视化示例。你可以在 TensorFlow Playground 网站 上尝试创建一个自己的。
与我们刚刚构建的类似分类神经网络的可视化示例。你可以在 TensorFlow Playground 网站 上尝试创建一个自己的。
你也可以使用 nn.Sequential 来实现上述相同的功能。
nn.Sequential 按照层出现的顺序对输入数据进行前向传播计算。
# Replicate CircleModelV0 with nn.Sequential
model_0 = nn.Sequential(
nn.Linear(in_features=2, out_features=5),
nn.Linear(in_features=5, out_features=1)
).to(device)
model_0
Sequential( (0): Linear(in_features=2, out_features=5, bias=True) (1): Linear(in_features=5, out_features=1, bias=True) )
哇,这看起来比继承 nn.Module 简单多了,为什么不总是使用 nn.Sequential 呢?
nn.Sequential 非常适合直接的计算,然而,正如命名空间所示,它总是按顺序执行。
因此,如果你需要执行其他操作(而不是简单的顺序计算),你会希望定义自己的自定义 nn.Module 子类。
现在我们有了一个模型,让我们看看当我们通过一些数据时会发生什么。
# Make predictions with the model
untrained_preds = model_0(X_test.to(device))
print(f"Length of predictions: {len(untrained_preds)}, Shape: {untrained_preds.shape}")
print(f"Length of test samples: {len(y_test)}, Shape: {y_test.shape}")
print(f"\nFirst 10 predictions:\n{untrained_preds[:10]}")
print(f"\nFirst 10 test labels:\n{y_test[:10]}")
Length of predictions: 200, Shape: torch.Size([200, 1])
Length of test samples: 200, Shape: torch.Size([200])
First 10 predictions:
tensor([[-0.4279],
[-0.3417],
[-0.5975],
[-0.3801],
[-0.5078],
[-0.4559],
[-0.2842],
[-0.3107],
[-0.6010],
[-0.3350]], device='cuda:0', grad_fn=<SliceBackward0>)
First 10 test labels:
tensor([1., 0., 1., 0., 1., 1., 0., 0., 1., 0.])
嗯,看起来预测的数量与测试标签的数量相同,但预测的格式或形状似乎与测试标签不一致。
我们可以采取几个步骤来解决这个问题,稍后我们会看到这些步骤。
2.1 设置损失函数和优化器¶
我们在之前的笔记本01中已经设置了一个损失函数(也称为准则或成本函数)和优化器。
但是不同类型的问题需要不同的损失函数。
例如,对于回归问题(预测一个数值),你可能会使用平均绝对误差(MAE)损失。
而对于二分类问题(如我们的问题),你通常会使用二元交叉熵作为损失函数。
然而,相同的优化器函数通常可以用于不同的问题空间。
例如,随机梯度下降优化器(SGD,torch.optim.SGD())可以用于多种问题,同样适用于Adam优化器(torch.optim.Adam())。
| 损失函数/优化器 | 问题类型 | PyTorch代码 |
|---|---|---|
| 随机梯度下降(SGD)优化器 | 分类、回归、其他多种问题 | torch.optim.SGD() |
| Adam优化器 | 分类、回归、其他多种问题 | torch.optim.Adam() |
| 二元交叉熵损失 | 二分类 | torch.nn.BCELossWithLogits 或 torch.nn.BCELoss |
| 交叉熵损失 | 多类分类 | torch.nn.CrossEntropyLoss |
| 平均绝对误差(MAE)或L1损失 | 回归 | torch.nn.L1Loss |
| 均方误差(MSE)或L2损失 | 回归 | torch.nn.MSELoss |
各种损失函数和优化器的表格,还有更多,但这些是你会看到的一些常见类型。
由于我们正在处理一个二分类问题,让我们使用二元交叉熵损失函数。
注意: 记住,损失函数 是衡量你的模型预测有多错误的指标,损失越高,模型越差。
此外,PyTorch文档通常将损失函数称为“损失准则”或“准则”,这些都是描述同一事物的不同方式。
PyTorch有两种二元交叉熵实现:
torch.nn.BCELoss()- 创建一个损失函数,用于衡量目标(标签)和输入(特征)之间的二元交叉熵。torch.nn.BCEWithLogitsLoss()- 这与上述相同,只是它内置了一个Sigmoid层(nn.Sigmoid)(我们很快就会看到这意味着什么)。
你应该使用哪一个?
torch.nn.BCEWithLogitsLoss()的文档指出,它在数值上比在nn.Sigmoid层之后使用torch.nn.BCELoss()更稳定。
因此,一般来说,第二种实现是一个更好的选择。然而,对于高级使用,你可能希望分离nn.Sigmoid和torch.nn.BCELoss()的组合,但这超出了本笔记本的范围。
了解这一点后,让我们创建一个损失函数和一个优化器。
对于优化器,我们将使用torch.optim.SGD()以学习率0.1来优化模型参数。
注意: 在PyTorch论坛上有一个关于
nn.BCELoss与nn.BCEWithLogitsLoss的使用的讨论。一开始可能会感到困惑,但随着实践的增多,会变得更容易理解。
# Create a loss function
# loss_fn = nn.BCELoss() # BCELoss = no sigmoid built-in
loss_fn = nn.BCEWithLogitsLoss() # BCEWithLogitsLoss = sigmoid built-in
# Create an optimizer
optimizer = torch.optim.SGD(params=model_0.parameters(),
lr=0.1)
现在,让我们也创建一个评估指标。
评估指标可以用来提供关于模型表现如何的另一个视角。
如果说损失函数衡量的是你的模型有多错误,我更愿意将评估指标视为衡量模型有多正确。
当然,你可能会认为这两者做的是同一件事,但评估指标提供了一个不同的视角。
毕竟,在评估你的模型时,从多个角度来看待事物是很好的。
对于分类问题,有几种评估指标可以使用,但让我们从准确率开始。
准确率可以通过将正确预测的总数除以预测的总数来衡量。
例如,一个模型在100次预测中做出99次正确预测,其准确率就是99%。
让我们写一个函数来实现这一点。
# Calculate accuracy (a classification metric)
def accuracy_fn(y_true, y_pred):
correct = torch.eq(y_true, y_pred).sum().item() # torch.eq() calculates where two tensors are equal
acc = (correct / len(y_pred)) * 100
return acc
太棒了!我们现在可以在训练模型时使用这个函数来衡量其性能,同时也可以观察损失值。
3. 训练模型¶
好的,现在我们已经准备好了损失函数和优化器,接下来让我们训练一个模型。
你还记得PyTorch训练循环的步骤吗?
如果记不清了,这里有一个提醒。
训练步骤:
PyTorch训练循环步骤
- 前向传播 - 模型遍历所有训练数据一次,执行其
forward()函数 计算(model(x_train))。 - 计算损失 - 模型的输出(预测值)与真实值进行比较,并评估
它们的误差(
loss = loss_fn(y_pred, y_train))。 - 清零梯度 - 优化器的梯度被设置为零(默认情况下它们会累积),以便
可以为特定的训练步骤重新计算(
optimizer.zero_grad())。 - 对损失进行反向传播 - 计算损失相对于每个需要更新的模型
参数的梯度(每个参数
带有
requires_grad=True)。这就是所谓的反向传播,因此称为“反向” (loss.backward())。 - 更新优化器(梯度下降) - 根据损失梯度更新带有
requires_grad=True的参数,以改进它们(optimizer.step())。
3.1 从原始模型输出到预测标签(logits -> 预测概率 -> 预测标签)¶
在进入训练循环步骤之前,我们先看看在前向传播过程中模型输出了什么(前向传播由 forward() 方法定义)。
为此,我们向模型传递一些数据。
# View the frist 5 outputs of the forward pass on the test data
y_logits = model_0(X_test.to(device))[:5]
y_logits
tensor([[-0.4279],
[-0.3417],
[-0.5975],
[-0.3801],
[-0.5078]], device='cuda:0', grad_fn=<SliceBackward0>)
由于我们的模型尚未经过训练,这些输出基本上是随机的。
但它们是什么?
它们是我们 forward() 方法的输出。
该方法实现了两层 nn.Linear(),内部调用了以下方程:
$$ \mathbf{y} = x \cdot \mathbf{Weights}^T + \mathbf{bias} $$
这个方程的原始输出(未经修改)($\mathbf{y}$),以及我们模型的原始输出,通常被称为logits。
这就是我们的模型在接收输入数据(方程中的 $x$ 或代码中的 X_test)时输出的内容,即 logits。
然而,这些数字很难解释。
我们希望得到一些与真实标签可比较的数字。
为了将模型的原始输出(logits)转换成这种形式,我们可以使用sigmoid 激活函数。
让我们试试看。
# Use sigmoid on model logits
y_pred_probs = torch.sigmoid(y_logits)
y_pred_probs
tensor([[0.3946],
[0.4154],
[0.3549],
[0.4061],
[0.3757]], device='cuda:0', grad_fn=<SigmoidBackward0>)
好的,现在看来输出结果有了一定的规律性(尽管它们仍然是随机的)。
它们现在以预测概率的形式呈现(我通常称之为 y_pred_probs),换句话说,这些数值表示模型认为数据点属于某一类别的程度。
在我们的例子中,由于处理的是二元分类问题,理想的输出结果是 0 或 1。
因此,这些数值可以看作是一个决策边界。
越接近 0,模型越认为样本属于类别 0;越接近 1,模型越认为样本属于类别 1。
更具体地说:
- 如果
y_pred_probs>= 0.5,则y=1(类别 1) - 如果
y_pred_probs< 0.5,则y=0(类别 0)
为了将预测概率转换为预测标签,我们可以对 sigmoid 激活函数的输出结果进行四舍五入。
# Find the predicted labels (round the prediction probabilities)
y_preds = torch.round(y_pred_probs)
# In full
y_pred_labels = torch.round(torch.sigmoid(model_0(X_test.to(device))[:5]))
# Check for equality
print(torch.eq(y_preds.squeeze(), y_pred_labels.squeeze()))
# Get rid of extra dimension
y_preds.squeeze()
tensor([True, True, True, True, True], device='cuda:0')
tensor([0., 0., 0., 0., 0.], device='cuda:0', grad_fn=<SqueezeBackward0>)
太棒了!现在看来,我们的模型预测结果与真实标签(y_test)的形式一致了。
y_test[:5]
tensor([1., 0., 1., 0., 1.])
这意味着我们将能够将模型的预测结果与测试标签进行比较,以了解其表现如何。
回顾一下,我们使用 sigmoid 激活函数将模型的原始输出(logits)转换为预测概率。
然后通过四舍五入将预测概率转换为预测标签。
注意: sigmoid 激活函数通常仅用于二分类的 logits。对于多类别分类,我们将会考虑使用 softmax 激活函数(这将在后续内容中介绍)。
并且,当将模型的原始输出传递给
nn.BCEWithLogitsLoss时,不需要使用 sigmoid 激活函数(“logits”损失中的“logits”是因为它作用于模型的原始 logits 输出),因为该损失函数内置了 sigmoid 函数。
torch.manual_seed(42)
# Set the number of epochs
epochs = 100
# Put data to target device
X_train, y_train = X_train.to(device), y_train.to(device)
X_test, y_test = X_test.to(device), y_test.to(device)
# Build training and evaluation loop
for epoch in range(epochs):
### Training
model_0.train()
# 1. Forward pass (model outputs raw logits)
y_logits = model_0(X_train).squeeze() # squeeze to remove extra `1` dimensions, this won't work unless model and data are on same device
y_pred = torch.round(torch.sigmoid(y_logits)) # turn logits -> pred probs -> pred labls
# 2. Calculate loss/accuracy
# loss = loss_fn(torch.sigmoid(y_logits), # Using nn.BCELoss you need torch.sigmoid()
# y_train)
loss = loss_fn(y_logits, # Using nn.BCEWithLogitsLoss works with raw logits
y_train)
acc = accuracy_fn(y_true=y_train,
y_pred=y_pred)
# 3. Optimizer zero grad
optimizer.zero_grad()
# 4. Loss backwards
loss.backward()
# 5. Optimizer step
optimizer.step()
### Testing
model_0.eval()
with torch.inference_mode():
# 1. Forward pass
test_logits = model_0(X_test).squeeze()
test_pred = torch.round(torch.sigmoid(test_logits))
# 2. Caculate loss/accuracy
test_loss = loss_fn(test_logits,
y_test)
test_acc = accuracy_fn(y_true=y_test,
y_pred=test_pred)
# Print out what's happening every 10 epochs
if epoch % 10 == 0:
print(f"Epoch: {epoch} | Loss: {loss:.5f}, Accuracy: {acc:.2f}% | Test loss: {test_loss:.5f}, Test acc: {test_acc:.2f}%")
Epoch: 0 | Loss: 0.72090, Accuracy: 50.00% | Test loss: 0.72196, Test acc: 50.00% Epoch: 10 | Loss: 0.70291, Accuracy: 50.00% | Test loss: 0.70542, Test acc: 50.00% Epoch: 20 | Loss: 0.69659, Accuracy: 50.00% | Test loss: 0.69942, Test acc: 50.00% Epoch: 30 | Loss: 0.69432, Accuracy: 43.25% | Test loss: 0.69714, Test acc: 41.00% Epoch: 40 | Loss: 0.69349, Accuracy: 47.00% | Test loss: 0.69623, Test acc: 46.50% Epoch: 50 | Loss: 0.69319, Accuracy: 49.00% | Test loss: 0.69583, Test acc: 46.00% Epoch: 60 | Loss: 0.69308, Accuracy: 50.12% | Test loss: 0.69563, Test acc: 46.50% Epoch: 70 | Loss: 0.69303, Accuracy: 50.38% | Test loss: 0.69551, Test acc: 46.00% Epoch: 80 | Loss: 0.69302, Accuracy: 51.00% | Test loss: 0.69543, Test acc: 46.00% Epoch: 90 | Loss: 0.69301, Accuracy: 51.00% | Test loss: 0.69537, Test acc: 46.00%
嗯,关于我们模型的性能,你有什么发现吗?
看起来模型顺利完成了训练和测试步骤,但结果似乎没有太大的变化。
在每个数据分割上,准确率勉强超过50%。
而且由于我们处理的是一个平衡的二分类问题,这意味着我们的模型表现和随机猜测差不多(在500个类别0和类别1的样本中,一个模型每次都预测类别1,准确率也只能达到50%)。
4. 进行预测并评估模型¶
从指标来看,我们的模型似乎是在随机猜测。
我们该如何进一步调查这个问题呢?
我有一个想法。
数据探索者的座右铭!
“可视化,可视化,可视化!”
让我们绘制一个图表,展示我们模型的预测结果、它试图预测的数据以及它为区分类别0和类别1所创建的决策边界。
为此,我们将编写一些代码,从Learn PyTorch for Deep Learning仓库下载并导入helper_functions.py脚本。
该脚本包含一个名为plot_decision_boundary()的有用函数,该函数创建一个NumPy网格,以可视化模型在不同点上预测特定类别的情况。
我们还将导入在笔记本01中编写的plot_predictions()函数,以备后用。
import requests
from pathlib import Path
# Download helper functions from Learn PyTorch repo (if not already downloaded)
if Path("helper_functions.py").is_file():
print("helper_functions.py already exists, skipping download")
else:
print("Downloading helper_functions.py")
request = requests.get("https://raw.githubusercontent.com/mrdbourke/pytorch-deep-learning/main/helper_functions.py")
with open("helper_functions.py", "wb") as f:
f.write(request.content)
from helper_functions import plot_predictions, plot_decision_boundary
helper_functions.py already exists, skipping download
/home/daniel/.local/lib/python3.8/site-packages/torchvision/io/image.py:13: UserWarning: Failed to load image Python extension: /home/daniel/.local/lib/python3.8/site-packages/torchvision/image.so: undefined symbol: _ZN3c106detail19maybe_wrap_dim_slowIlEET_S2_S2_b
warn(f"Failed to load image Python extension: {e}")
# Plot decision boundaries for training and test sets
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.title("Train")
plot_decision_boundary(model_0, X_train, y_train)
plt.subplot(1, 2, 2)
plt.title("Test")
plot_decision_boundary(model_0, X_test, y_test)

哦,看来我们找到了模型性能问题的根源。
它目前正试图用一条直线来区分红色和蓝色的点...
这就解释了为什么准确率只有50%。因为我们的数据是圆形的,画一条直线最多只能将其一分为二。
用机器学习的术语来说,我们的模型欠拟合,这意味着它没有从数据中学习到预测性的模式。
我们该如何改进呢?
5. 改进模型(从模型角度)¶
让我们尝试解决模型欠拟合的问题。
具体从模型(而非数据)的角度,有几种方法可以尝试改进。
| 模型改进技术* | 作用 |
|---|---|
| 增加更多层 | 每层可能提高模型的学习能力,每层能够学习数据中某种新的模式,更多层通常被称为使神经网络更深。 |
| 增加更多隐藏单元 | 类似于上述,每层更多的隐藏单元意味着模型可能提高学习能力,更多隐藏单元通常被称为使神经网络更宽。 |
| 延长训练时间(更多周期) | 如果模型有更多机会观察数据,它可能会学到更多。 |
| 改变激活函数 | 某些数据无法仅用直线拟合(如我们所见),使用非线性激活函数可以帮助解决这个问题(提示,提示)。 |
| 改变学习率 | 虽然不那么针对模型,但仍然相关,优化器的学习率决定了模型每一步应改变参数的程度,太大模型会过度校正,太小则学不到足够的内容。 |
| 改变损失函数 | 同样,不那么针对模型但仍然重要,不同问题需要不同的损失函数。例如,二元交叉熵损失函数不适用于多类分类问题。 |
| 使用迁移学习 | 采用一个与你问题领域相似的预训练模型,并调整它以适应你的问题。我们在笔记本06中讨论迁移学习。 |
注意: *因为你可以手动调整所有这些参数,它们被称为超参数。
这也是机器学习一半艺术一半科学的地方,对于你的项目,没有真正的方法知道最佳的参数组合是什么,最好的办法是遵循数据科学家的座右铭:“实验,实验,实验”。
让我们看看如果我们向模型添加一个额外的层,延长训练时间(从epochs=100改为epochs=1000),并将隐藏单元的数量从5增加到10会发生什么。
我们将遵循上述相同的步骤,但调整一些超参数。
class CircleModelV1(nn.Module):
def __init__(self):
super().__init__()
self.layer_1 = nn.Linear(in_features=2, out_features=10)
self.layer_2 = nn.Linear(in_features=10, out_features=10) # extra layer
self.layer_3 = nn.Linear(in_features=10, out_features=1)
def forward(self, x): # note: always make sure forward is spelt correctly!
# Creating a model like this is the same as below, though below
# generally benefits from speedups where possible.
# z = self.layer_1(x)
# z = self.layer_2(z)
# z = self.layer_3(z)
# return z
return self.layer_3(self.layer_2(self.layer_1(x)))
model_1 = CircleModelV1().to(device)
model_1
CircleModelV1( (layer_1): Linear(in_features=2, out_features=10, bias=True) (layer_2): Linear(in_features=10, out_features=10, bias=True) (layer_3): Linear(in_features=10, out_features=1, bias=True) )
现在我们已经有了一个模型,我们将重新创建一个损失函数和优化器实例,使用与之前相同的设置。
# loss_fn = nn.BCELoss() # Requires sigmoid on input
loss_fn = nn.BCEWithLogitsLoss() # Does not require sigmoid on input
optimizer = torch.optim.SGD(model_1.parameters(), lr=0.1)
美观的模型、优化器和损失函数都准备好了,让我们来构建训练循环。
这一次我们将训练更长时间(epochs=1000 对比 epochs=100),看看是否能提升我们的模型性能。
torch.manual_seed(42)
epochs = 1000 # Train for longer
# Put data to target device
X_train, y_train = X_train.to(device), y_train.to(device)
X_test, y_test = X_test.to(device), y_test.to(device)
for epoch in range(epochs):
### Training
# 1. Forward pass
y_logits = model_1(X_train).squeeze()
y_pred = torch.round(torch.sigmoid(y_logits)) # logits -> predicition probabilities -> prediction labels
# 2. Calculate loss/accuracy
loss = loss_fn(y_logits, y_train)
acc = accuracy_fn(y_true=y_train,
y_pred=y_pred)
# 3. Optimizer zero grad
optimizer.zero_grad()
# 4. Loss backwards
loss.backward()
# 5. Optimizer step
optimizer.step()
### Testing
model_1.eval()
with torch.inference_mode():
# 1. Forward pass
test_logits = model_1(X_test).squeeze()
test_pred = torch.round(torch.sigmoid(test_logits))
# 2. Caculate loss/accuracy
test_loss = loss_fn(test_logits,
y_test)
test_acc = accuracy_fn(y_true=y_test,
y_pred=test_pred)
# Print out what's happening every 10 epochs
if epoch % 100 == 0:
print(f"Epoch: {epoch} | Loss: {loss:.5f}, Accuracy: {acc:.2f}% | Test loss: {test_loss:.5f}, Test acc: {test_acc:.2f}%")
Epoch: 0 | Loss: 0.69396, Accuracy: 50.88% | Test loss: 0.69261, Test acc: 51.00% Epoch: 100 | Loss: 0.69305, Accuracy: 50.38% | Test loss: 0.69379, Test acc: 48.00% Epoch: 200 | Loss: 0.69299, Accuracy: 51.12% | Test loss: 0.69437, Test acc: 46.00% Epoch: 300 | Loss: 0.69298, Accuracy: 51.62% | Test loss: 0.69458, Test acc: 45.00% Epoch: 400 | Loss: 0.69298, Accuracy: 51.12% | Test loss: 0.69465, Test acc: 46.00% Epoch: 500 | Loss: 0.69298, Accuracy: 51.00% | Test loss: 0.69467, Test acc: 46.00% Epoch: 600 | Loss: 0.69298, Accuracy: 51.00% | Test loss: 0.69468, Test acc: 46.00% Epoch: 700 | Loss: 0.69298, Accuracy: 51.00% | Test loss: 0.69468, Test acc: 46.00% Epoch: 800 | Loss: 0.69298, Accuracy: 51.00% | Test loss: 0.69468, Test acc: 46.00% Epoch: 900 | Loss: 0.69298, Accuracy: 51.00% | Test loss: 0.69468, Test acc: 46.00%
什么?我们的模型训练时间更长,还额外加了一层,但看起来它并没有比随机猜测更好地学习到任何模式。
我们来可视化一下。
# Plot decision boundaries for training and test sets
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.title("Train")
plot_decision_boundary(model_1, X_train, y_train)
plt.subplot(1, 2, 2)
plt.title("Test")
plot_decision_boundary(model_1, X_test, y_test)

5.1 准备数据以验证模型能否拟合直线¶
让我们创建一些线性数据,看看我们的模型是否能够对其进行建模,而不是使用一个根本无法学习的模型。
# Create some data (same as notebook 01)
weight = 0.7
bias = 0.3
start = 0
end = 1
step = 0.01
# Create data
X_regression = torch.arange(start, end, step).unsqueeze(dim=1)
y_regression = weight * X_regression + bias # linear regression formula
# Check the data
print(len(X_regression))
X_regression[:5], y_regression[:5]
100
(tensor([[0.0000],
[0.0100],
[0.0200],
[0.0300],
[0.0400]]),
tensor([[0.3000],
[0.3070],
[0.3140],
[0.3210],
[0.3280]]))
太好了,现在让我们将数据分成训练集和测试集。
# Create train and test splits
train_split = int(0.8 * len(X_regression)) # 80% of data used for training set
X_train_regression, y_train_regression = X_regression[:train_split], y_regression[:train_split]
X_test_regression, y_test_regression = X_regression[train_split:], y_regression[train_split:]
# Check the lengths of each split
print(len(X_train_regression),
len(y_train_regression),
len(X_test_regression),
len(y_test_regression))
80 80 20 20
很好,让我们看看数据的样子。
为此,我们将使用在笔记本01中创建的 plot_predictions() 函数。
它包含在我们之前下载的 Learn PyTorch for Deep Learning 仓库中的 helper_functions.py 脚本 里。
plot_predictions(train_data=X_train_regression,
train_labels=y_train_regression,
test_data=X_test_regression,
test_labels=y_test_regression
);

5.2 调整 model_1 以拟合直线¶
现在我们有了一些数据,让我们重新创建 model_1,但使用适合回归数据的损失函数。
# Same architecture as model_1 (but using nn.Sequential)
model_2 = nn.Sequential(
nn.Linear(in_features=1, out_features=10),
nn.Linear(in_features=10, out_features=10),
nn.Linear(in_features=10, out_features=1)
).to(device)
model_2
Sequential( (0): Linear(in_features=1, out_features=10, bias=True) (1): Linear(in_features=10, out_features=10, bias=True) (2): Linear(in_features=10, out_features=1, bias=True) )
我们将设置损失函数为 nn.L1Loss()(与平均绝对误差相同),并将优化器设置为 torch.optim.SGD()。
# Loss and optimizer
loss_fn = nn.L1Loss()
optimizer = torch.optim.SGD(model_2.parameters(), lr=0.1)
现在让我们使用常规的训练循环步骤来训练模型,设置 epochs=1000(就像 model_1 一样)。
注意: 我们一直在编写类似的训练循环代码。我故意这样做,是为了让大家不断练习。不过,你们有没有想过如何将这些代码功能化呢?这样将来可以节省不少编码工作。可能可以有一个用于训练的函数和一个用于测试的函数。
# Train the model
torch.manual_seed(42)
# Set the number of epochs
epochs = 1000
# Put data to target device
X_train_regression, y_train_regression = X_train_regression.to(device), y_train_regression.to(device)
X_test_regression, y_test_regression = X_test_regression.to(device), y_test_regression.to(device)
for epoch in range(epochs):
### Training
# 1. Forward pass
y_pred = model_2(X_train_regression)
# 2. Calculate loss (no accuracy since it's a regression problem, not classification)
loss = loss_fn(y_pred, y_train_regression)
# 3. Optimizer zero grad
optimizer.zero_grad()
# 4. Loss backwards
loss.backward()
# 5. Optimizer step
optimizer.step()
### Testing
model_2.eval()
with torch.inference_mode():
# 1. Forward pass
test_pred = model_2(X_test_regression)
# 2. Calculate the loss
test_loss = loss_fn(test_pred, y_test_regression)
# Print out what's happening
if epoch % 100 == 0:
print(f"Epoch: {epoch} | Train loss: {loss:.5f}, Test loss: {test_loss:.5f}")
Epoch: 0 | Train loss: 0.75986, Test loss: 0.54143 Epoch: 100 | Train loss: 0.09309, Test loss: 0.02901 Epoch: 200 | Train loss: 0.07376, Test loss: 0.02850 Epoch: 300 | Train loss: 0.06745, Test loss: 0.00615 Epoch: 400 | Train loss: 0.06107, Test loss: 0.02004 Epoch: 500 | Train loss: 0.05698, Test loss: 0.01061 Epoch: 600 | Train loss: 0.04857, Test loss: 0.01326 Epoch: 700 | Train loss: 0.06109, Test loss: 0.02127 Epoch: 800 | Train loss: 0.05599, Test loss: 0.01426 Epoch: 900 | Train loss: 0.05571, Test loss: 0.00603
好的,与分类数据上的model_1不同,看起来model_2的损失实际上在下降。
让我们绘制它的预测结果,看看是否确实如此。
并且记住,由于我们的模型和数据使用的是目标device,而这个设备可能是GPU,然而,我们的绘图函数使用的是matplotlib,而matplotlib无法处理位于GPU上的数据。
为了处理这个问题,我们将在将数据传递给plot_predictions()时,使用.cpu()将所有数据发送到CPU。
# Turn on evaluation mode
model_2.eval()
# Make predictions (inference)
with torch.inference_mode():
y_preds = model_2(X_test_regression)
# Plot data and predictions with data on the CPU (matplotlib can't handle data on the GPU)
# (try removing .cpu() from one of the below and see what happens)
plot_predictions(train_data=X_train_regression.cpu(),
train_labels=y_train_regression.cpu(),
test_data=X_test_regression.cpu(),
test_labels=y_test_regression.cpu(),
predictions=y_preds.cpu());

看起来我们的模型在直线问题上能够远超随机猜测的表现。
这是个好现象。
这意味着我们的模型至少具备一定的学习能力。
注意: 在构建深度学习模型时,一个有用的故障排除步骤是从尽可能小的模型开始,以确认模型是否有效,然后再进行扩展。
这可能意味着从一个简单的神经网络(层数不多,隐藏神经元不多)和一个小数据集(比如我们创建的这个)开始,然后在增加数据量或模型大小/设计之前,先过拟合(使模型表现过于优秀)这个小示例,以减少过拟合。
那么,问题可能出在哪里呢?
让我们一探究竟。
6.1 重构非线性数据(红色和蓝色圆圈)¶
首先,让我们重新创建数据,以全新的状态开始。我们将采用与之前相同的设置。
# Make and plot data
import matplotlib.pyplot as plt
from sklearn.datasets import make_circles
n_samples = 1000
X, y = make_circles(n_samples=1000,
noise=0.03,
random_state=42,
)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.RdBu);

好的!现在让我们将数据集按照80%用于训练和20%用于测试进行分割。
from sklearn.model_selection import train_test_split
# Assuming X contains the features and y contains the labels
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Convert to tensors and split into train and test sets
import torch
from sklearn.model_selection import train_test_split
# Turn data into tensors
X = torch.from_numpy(X).type(torch.float)
y = torch.from_numpy(y).type(torch.float)
# Split into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size=0.2,
random_state=42
)
X_train[:5], y_train[:5]
(tensor([[ 0.6579, -0.4651],
[ 0.6319, -0.7347],
[-1.0086, -0.1240],
[-0.9666, -0.2256],
[-0.1666, 0.7994]]),
tensor([1., 0., 0., 0., 1.]))
6.2 构建具有非线性特性的模型¶
现在到了有趣的部分。
你认为用无限的直线(线性)和非直线(非线性)线条能画出什么样的图案?
我敢打赌,你可以变得非常有创意。
到目前为止,我们的神经网络只使用了线性(直线)函数。
但我们一直在处理的数据是非线性的(圆形)。
你认为当我们引入让模型使用非线性激活函数的能力时会发生什么?
让我们来看看。
PyTorch 提供了许多现成的非线性激活函数,它们做类似但不同的事情。
其中最常见且表现最好的是 ReLU)(修正线性单元,torch.nn.ReLU())。
与其谈论它,不如让我们在神经网络的前向传播中隐藏层之间加入 ReLU 激活函数,看看会发生什么。
# Build model with non-linear activation function
from torch import nn
class CircleModelV2(nn.Module):
def __init__(self):
super().__init__()
self.layer_1 = nn.Linear(in_features=2, out_features=10)
self.layer_2 = nn.Linear(in_features=10, out_features=10)
self.layer_3 = nn.Linear(in_features=10, out_features=1)
self.relu = nn.ReLU() # <- add in ReLU activation function
# Can also put sigmoid in the model
# This would mean you don't need to use it on the predictions
# self.sigmoid = nn.Sigmoid()
def forward(self, x):
# Intersperse the ReLU activation function between layers
return self.layer_3(self.relu(self.layer_2(self.relu(self.layer_1(x)))))
model_3 = CircleModelV2().to(device)
print(model_3)
CircleModelV2( (layer_1): Linear(in_features=2, out_features=10, bias=True) (layer_2): Linear(in_features=10, out_features=10, bias=True) (layer_3): Linear(in_features=10, out_features=1, bias=True) (relu): ReLU() )
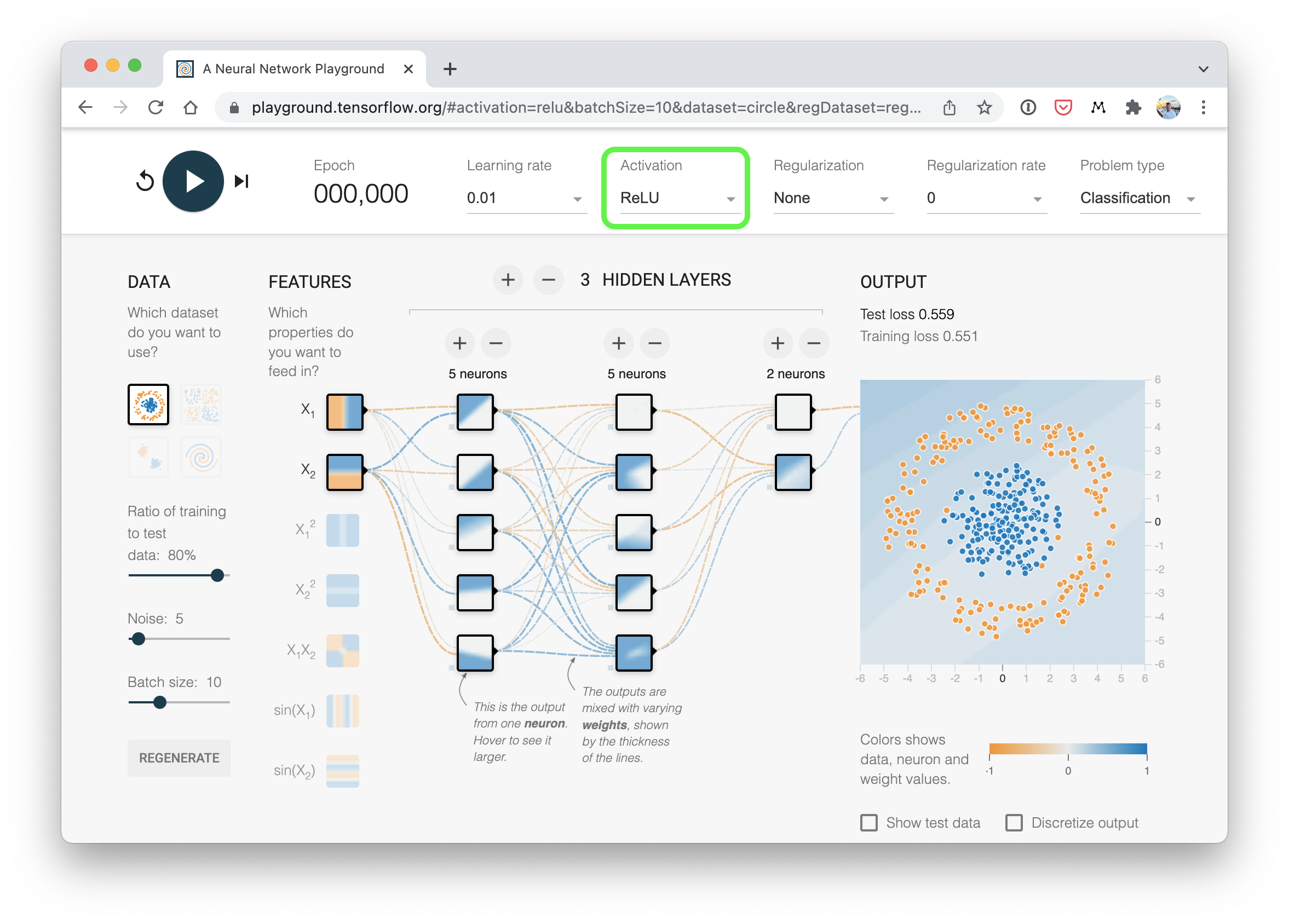 一个与我们刚刚构建的分类神经网络(使用ReLU激活)类似的可视化示例。尝试在TensorFlow Playground网站上创建一个你自己的。
一个与我们刚刚构建的分类神经网络(使用ReLU激活)类似的可视化示例。尝试在TensorFlow Playground网站上创建一个你自己的。
问题: 在构建神经网络时,非线性激活函数应该放在哪里?
一个经验法则是将它们放在隐藏层之间以及输出层之后,然而,并没有一成不变的规定。随着你对神经网络和深度学习的了解加深,你会发现有很多不同的组合方式。在此期间,最好的办法就是不断实验、实验、再实验。
现在我们已经有了一个准备就绪的模型,接下来让我们创建一个二分类损失函数以及一个优化器。
# Setup loss and optimizer
loss_fn = nn.BCEWithLogitsLoss()
optimizer = torch.optim.SGD(model_3.parameters(), lr=0.1)
太棒了!
6.3 使用非线性训练模型¶
你已经熟悉流程了,模型、损失函数、优化器准备就绪,接下来创建训练和测试循环。
# Fit the model
torch.manual_seed(42)
epochs = 1000
# Put all data on target device
X_train, y_train = X_train.to(device), y_train.to(device)
X_test, y_test = X_test.to(device), y_test.to(device)
for epoch in range(epochs):
# 1. Forward pass
y_logits = model_3(X_train).squeeze()
y_pred = torch.round(torch.sigmoid(y_logits)) # logits -> prediction probabilities -> prediction labels
# 2. Calculate loss and accuracy
loss = loss_fn(y_logits, y_train) # BCEWithLogitsLoss calculates loss using logits
acc = accuracy_fn(y_true=y_train,
y_pred=y_pred)
# 3. Optimizer zero grad
optimizer.zero_grad()
# 4. Loss backward
loss.backward()
# 5. Optimizer step
optimizer.step()
### Testing
model_3.eval()
with torch.inference_mode():
# 1. Forward pass
test_logits = model_3(X_test).squeeze()
test_pred = torch.round(torch.sigmoid(test_logits)) # logits -> prediction probabilities -> prediction labels
# 2. Calcuate loss and accuracy
test_loss = loss_fn(test_logits, y_test)
test_acc = accuracy_fn(y_true=y_test,
y_pred=test_pred)
# Print out what's happening
if epoch % 100 == 0:
print(f"Epoch: {epoch} | Loss: {loss:.5f}, Accuracy: {acc:.2f}% | Test Loss: {test_loss:.5f}, Test Accuracy: {test_acc:.2f}%")
Epoch: 0 | Loss: 0.69295, Accuracy: 50.00% | Test Loss: 0.69319, Test Accuracy: 50.00% Epoch: 100 | Loss: 0.69115, Accuracy: 52.88% | Test Loss: 0.69102, Test Accuracy: 52.50% Epoch: 200 | Loss: 0.68977, Accuracy: 53.37% | Test Loss: 0.68940, Test Accuracy: 55.00% Epoch: 300 | Loss: 0.68795, Accuracy: 53.00% | Test Loss: 0.68723, Test Accuracy: 56.00% Epoch: 400 | Loss: 0.68517, Accuracy: 52.75% | Test Loss: 0.68411, Test Accuracy: 56.50% Epoch: 500 | Loss: 0.68102, Accuracy: 52.75% | Test Loss: 0.67941, Test Accuracy: 56.50% Epoch: 600 | Loss: 0.67515, Accuracy: 54.50% | Test Loss: 0.67285, Test Accuracy: 56.00% Epoch: 700 | Loss: 0.66659, Accuracy: 58.38% | Test Loss: 0.66322, Test Accuracy: 59.00% Epoch: 800 | Loss: 0.65160, Accuracy: 64.00% | Test Loss: 0.64757, Test Accuracy: 67.50% Epoch: 900 | Loss: 0.62362, Accuracy: 74.00% | Test Loss: 0.62145, Test Accuracy: 79.00%
呵呵!看起来好多了!
6.4 评估使用非线性激活函数训练的模型¶
还记得我们的圆形数据是如何呈现非线性特征的吗?现在,让我们看看在使用非线性激活函数训练模型后,模型的预测结果会是什么样子。
# Make predictions
model_3.eval()
with torch.inference_mode():
y_preds = torch.round(torch.sigmoid(model_3(X_test))).squeeze()
y_preds[:10], y[:10] # want preds in same format as truth labels
(tensor([1., 0., 1., 0., 0., 1., 0., 0., 1., 0.], device='cuda:0'), tensor([1., 1., 1., 1., 0., 1., 1., 1., 1., 0.]))
# Plot decision boundaries for training and test sets
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.title("Train")
plot_decision_boundary(model_1, X_train, y_train) # model_1 = no non-linearity
plt.subplot(1, 2, 2)
plt.title("Test")
plot_decision_boundary(model_3, X_test, y_test) # model_3 = has non-linearity

很好!虽然还不是完美,但比之前好多了。
你或许可以尝试一些技巧来提高模型的测试准确率?(提示:回到第5节寻找提升模型的建议)
7. 复制非线性激活函数¶
我们之前了解到,在模型中加入非线性激活函数有助于其拟合非线性数据。
注意: 你在实际工作中遇到的大部分数据都是非线性的(或者是线性与非线性的组合)。目前我们一直在处理二维图上的点。但想象一下,如果你有想要分类的植物图像,植物的形状千差万别。或者你想总结维基百科上的文本,文字的组合方式多种多样(线性和非线性模式)。
但非线性激活函数看起来是什么样的呢?
我们不妨尝试复制一些,并了解它们的功能。
首先,让我们创建一小部分数据。
# Create a toy tensor (similar to the data going into our model(s))
A = torch.arange(-10, 10, 1, dtype=torch.float32)
A
tensor([-10., -9., -8., -7., -6., -5., -4., -3., -2., -1., 0., 1.,
2., 3., 4., 5., 6., 7., 8., 9.])
很好,现在我们来绘制它。
# Visualize the toy tensor
plt.plot(A);

一条直线,不错。
现在让我们看看 ReLU 激活函数是如何影响它的。
我们将自己重新创建 ReLU 函数,而不是使用 PyTorch 的 ReLU(torch.nn.ReLU)。
ReLU 函数将所有负值变为 0,并保持正值不变。
# Create ReLU function by hand
def relu(x):
return torch.maximum(torch.tensor(0), x) # inputs must be tensors
# Pass toy tensor through ReLU function
relu(A)
tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 2., 3., 4., 5., 6., 7.,
8., 9.])
看来我们的ReLU函数起作用了,所有负值都变成了零。
我们来绘制一下这些数据。
# Plot ReLU activated toy tensor
plt.plot(relu(A));

不错!这看起来和维基百科上关于ReLU)的ReLU函数形状完全一样。
我们试试一直在用的sigmoid函数如何?
Sigmoid函数的公式如下:
$$ out_i = \frac{1}{1+e^{-input_i}} $$
或者用$x$作为输入:
$$ S(x) = \frac{1}{1+e^{-x_i}} $$
其中$S$代表sigmoid,$e$代表指数函数(torch.exp()),$i$代表张量中的一个特定元素。
让我们用PyTorch构建一个函数来复现sigmoid函数。
# Create a custom sigmoid function
def sigmoid(x):
return 1 / (1 + torch.exp(-x))
# Test custom sigmoid on toy tensor
sigmoid(A)
tensor([4.5398e-05, 1.2339e-04, 3.3535e-04, 9.1105e-04, 2.4726e-03, 6.6929e-03,
1.7986e-02, 4.7426e-02, 1.1920e-01, 2.6894e-01, 5.0000e-01, 7.3106e-01,
8.8080e-01, 9.5257e-01, 9.8201e-01, 9.9331e-01, 9.9753e-01, 9.9909e-01,
9.9966e-01, 9.9988e-01])
哇,这些值看起来很像我们之前见过的预测概率,让我们看看它们可视化后是什么样子。
# Plot sigmoid activated toy tensor
plt.plot(sigmoid(A));

看起来不错!我们从一条直线变成了曲线。
现在,PyTorch 中还有许多其他非线性激活函数,我们还没有尝试过。
但这两个是最常见的。
关键在于,你可以用无限多的线性(直线)和非线性(非直线)线条画出什么样的图案?
几乎什么都可以对吧?
这正是我们在结合线性和非线性函数时模型所做的事情。
我们不是告诉模型该做什么,而是给它工具,让它自己找出如何最好地发现数据中的模式。
而这些工具就是线性和非线性函数。
8. 通过构建多类 PyTorch 模型将所有内容整合起来¶
我们已经涵盖了不少内容。
但现在让我们通过一个多类分类问题将所有内容整合起来。
回顾一下,二元分类问题涉及将事物分类为两个选项之一(例如,将照片分类为猫照片或狗照片),而多类分类问题涉及将事物从两个以上的选项列表中进行分类(例如,将照片分类为猫、狗或鸡)。
 二元分类与多类分类的示例。二元分类涉及两个类别(一个事物或另一个事物),而多类分类可以处理两个以上的任意数量的类别,例如,流行的 ImageNet-1k 数据集 被用作计算机视觉基准,包含 1000 个类别。
二元分类与多类分类的示例。二元分类涉及两个类别(一个事物或另一个事物),而多类分类可以处理两个以上的任意数量的类别,例如,流行的 ImageNet-1k 数据集 被用作计算机视觉基准,包含 1000 个类别。
8.1 创建多类别分类数据¶
要开始一个多类别分类问题,让我们先创建一些多类别数据。
为此,我们可以利用 Scikit-Learn 的 make_blobs() 方法。
这个方法可以创建我们想要的任意数量的类别(通过 centers 参数)。
具体来说,我们将执行以下步骤:
- 使用
make_blobs()创建一些多类别数据。 - 将数据转换为张量(
make_blobs()默认使用 NumPy 数组)。 - 使用
train_test_split()将数据分割为训练集和测试集。 - 可视化数据。
# Import dependencies
import torch
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
# Set the hyperparameters for data creation
NUM_CLASSES = 4
NUM_FEATURES = 2
RANDOM_SEED = 42
# 1. Create multi-class data
X_blob, y_blob = make_blobs(n_samples=1000,
n_features=NUM_FEATURES, # X features
centers=NUM_CLASSES, # y labels
cluster_std=1.5, # give the clusters a little shake up (try changing this to 1.0, the default)
random_state=RANDOM_SEED
)
# 2. Turn data into tensors
X_blob = torch.from_numpy(X_blob).type(torch.float)
y_blob = torch.from_numpy(y_blob).type(torch.LongTensor)
print(X_blob[:5], y_blob[:5])
# 3. Split into train and test sets
X_blob_train, X_blob_test, y_blob_train, y_blob_test = train_test_split(X_blob,
y_blob,
test_size=0.2,
random_state=RANDOM_SEED
)
# 4. Plot data
plt.figure(figsize=(10, 7))
plt.scatter(X_blob[:, 0], X_blob[:, 1], c=y_blob, cmap=plt.cm.RdYlBu);
tensor([[-8.4134, 6.9352],
[-5.7665, -6.4312],
[-6.0421, -6.7661],
[ 3.9508, 0.6984],
[ 4.2505, -0.2815]]) tensor([3, 2, 2, 1, 1])

太棒了!看起来我们已经准备好一些多类别数据了。
让我们构建一个模型来分离这些彩色斑点。
问题: 这个数据集需要非线性吗?还是可以用一系列直线来分离它?
8.2 在PyTorch中构建多类别分类模型¶
到目前为止,我们已经创建了几个PyTorch模型。
你可能也开始意识到神经网络的灵活性。
我们何不构建一个类似于model_3的模型,但它仍然能够处理多类别数据呢?
为此,让我们创建一个nn.Module的子类,该子类接收三个超参数:
input_features- 进入模型的X特征的数量。output_features- 我们希望的输出特征数量(这将与NUM_CLASSES或你的多类别分类问题中的类别数量相等)。hidden_units- 我们希望每个隐藏层使用的隐藏神经元数量。
既然我们要把这些组合起来,让我们设置一些设备无关的代码(我们在同一个笔记本中不必再次这样做,这只是个提醒)。
然后,我们将使用上述超参数创建模型类。
# Create device agnostic code
device = "cuda" if torch.cuda.is_available() else "cpu"
device
'cuda'
from torch import nn
# Build model
class BlobModel(nn.Module):
def __init__(self, input_features, output_features, hidden_units=8):
"""Initializes all required hyperparameters for a multi-class classification model.
Args:
input_features (int): Number of input features to the model.
out_features (int): Number of output features of the model
(how many classes there are).
hidden_units (int): Number of hidden units between layers, default 8.
"""
super().__init__()
self.linear_layer_stack = nn.Sequential(
nn.Linear(in_features=input_features, out_features=hidden_units),
# nn.ReLU(), # <- does our dataset require non-linear layers? (try uncommenting and see if the results change)
nn.Linear(in_features=hidden_units, out_features=hidden_units),
# nn.ReLU(), # <- does our dataset require non-linear layers? (try uncommenting and see if the results change)
nn.Linear(in_features=hidden_units, out_features=output_features), # how many classes are there?
)
def forward(self, x):
return self.linear_layer_stack(x)
# Create an instance of BlobModel and send it to the target device
model_4 = BlobModel(input_features=NUM_FEATURES,
output_features=NUM_CLASSES,
hidden_units=8).to(device)
model_4
BlobModel(
(linear_layer_stack): Sequential(
(0): Linear(in_features=2, out_features=8, bias=True)
(1): Linear(in_features=8, out_features=8, bias=True)
(2): Linear(in_features=8, out_features=4, bias=True)
)
)
太棒了!我们的多类别模型已经准备就绪,接下来让我们为它创建损失函数和优化器。
8.3 为多类别PyTorch模型创建损失函数和优化器¶
由于我们处理的是一个多类别分类问题,我们将使用 nn.CrossEntropyLoss() 方法作为我们的损失函数。
同时,我们将继续使用学习率为0.1的SGD来优化我们的 model_4 参数。
# Create loss and optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model_4.parameters(),
lr=0.1) # exercise: try changing the learning rate here and seeing what happens to the model's performance
8.4 获取多类别PyTorch模型的预测概率¶
好的,我们已经准备好了损失函数和优化器,并且准备训练我们的模型。但在开始训练之前,让我们先用模型进行一次前向传播,看看它是否正常工作。
# Perform a single forward pass on the data (we'll need to put it to the target device for it to work)
model_4(X_blob_train.to(device))[:5]
tensor([[-1.2711, -0.6494, -1.4740, -0.7044],
[ 0.2210, -1.5439, 0.0420, 1.1531],
[ 2.8698, 0.9143, 3.3169, 1.4027],
[ 1.9576, 0.3125, 2.2244, 1.1324],
[ 0.5458, -1.2381, 0.4441, 1.1804]], device='cuda:0',
grad_fn=<SliceBackward0>)
这里会输出什么?
看起来我们为每个样本的每个特征都得到了一个值。
让我们检查一下形状来确认。
# How many elements in a single prediction sample?
model_4(X_blob_train.to(device))[0].shape, NUM_CLASSES
(torch.Size([4]), 4)
太好了,我们的模型正在为每个类别预测一个值。
你还记得我们模型的原始输出叫什么吗?
提示:它和“青蛙分裂”押韵(在制作这些材料的过程中没有动物受到伤害)。
如果你猜的是logits,那就对了。
所以现在我们的模型正在输出logits,但如果我们想确定它为样本给出的具体标签呢?
就像我们在二分类问题中所做的那样,我们如何从 logits -> 预测概率 -> 预测标签 呢?
这就是softmax激活函数发挥作用的地方。
softmax函数计算每个预测类别相对于所有其他可能类别的实际预测类别的概率。
如果这还不清楚,让我们通过代码来看一看。
# Make prediction logits with model
y_logits = model_4(X_blob_test.to(device))
# Perform softmax calculation on logits across dimension 1 to get prediction probabilities
y_pred_probs = torch.softmax(y_logits, dim=1)
print(y_logits[:5])
print(y_pred_probs[:5])
tensor([[-1.2549, -0.8112, -1.4795, -0.5696],
[ 1.7168, -1.2270, 1.7367, 2.1010],
[ 2.2400, 0.7714, 2.6020, 1.0107],
[-0.7993, -0.3723, -0.9138, -0.5388],
[-0.4332, -1.6117, -0.6891, 0.6852]], device='cuda:0',
grad_fn=<SliceBackward0>)
tensor([[0.1872, 0.2918, 0.1495, 0.3715],
[0.2824, 0.0149, 0.2881, 0.4147],
[0.3380, 0.0778, 0.4854, 0.0989],
[0.2118, 0.3246, 0.1889, 0.2748],
[0.1945, 0.0598, 0.1506, 0.5951]], device='cuda:0',
grad_fn=<SliceBackward0>)
嗯,这里发生了什么?
尽管看起来softmax函数的输出仍然是一堆杂乱的数字(确实如此,因为我们的模型尚未经过训练,目前是基于随机模式进行预测),但每个样本之间有一个非常特定的差异。
在将logits通过softmax函数处理后,每个单独的样本现在加起来等于1(或非常接近1)。
我们来验证一下。
# Sum the first sample output of the softmax activation function
torch.sum(y_pred_probs[0])
tensor(1., device='cuda:0', grad_fn=<SumBackward0>)
这些预测概率本质上是在说明模型认为目标样本 X(输入)与每个类别的对应程度。
由于 y_pred_probs 中每个类别都有一个值,最大值的索引就是模型认为该特定数据样本最可能属于的类别。
我们可以使用 torch.argmax() 来检查哪个索引具有最高值。
# Which class does the model think is *most* likely at the index 0 sample?
print(y_pred_probs[0])
print(torch.argmax(y_pred_probs[0]))
tensor([0.1872, 0.2918, 0.1495, 0.3715], device='cuda:0',
grad_fn=<SelectBackward0>)
tensor(3, device='cuda:0')
可以看到,torch.argmax() 的输出结果是 3,因此对于索引为 0 的样本的特征(X),模型预测最有可能的类别值(y)是 3。
当然,目前这只是随机猜测,所以模型有 25% 的正确概率(因为有四个类别)。但我们可以通过训练模型来提高这些概率。
注意: 综上所述,模型的原始输出被称为 logits。
对于多类别分类问题,要将 logits 转换为 预测概率,可以使用 softmax 激活函数(
torch.softmax)。具有最高 预测概率 的值的索引是模型认为在该样本输入特征下最有可能的类别编号(尽管这是一个预测,但这并不意味着它一定是正确的)。
8.5 为多类PyTorch模型创建训练和测试循环¶
好的,现在我们已经完成了所有的准备工作,让我们编写一个训练和测试循环来改进和评估我们的模型。
我们之前已经做过很多类似的步骤,所以这部分内容主要是练习。
唯一的不同之处在于,我们将调整步骤,将模型输出(logits)转换为预测概率(使用softmax激活函数),然后通过取softmax激活函数输出的argmax来得到预测标签。
让我们对模型进行epochs=100的训练,并每10个epoch进行一次评估。
# Fit the model
torch.manual_seed(42)
# Set number of epochs
epochs = 100
# Put data to target device
X_blob_train, y_blob_train = X_blob_train.to(device), y_blob_train.to(device)
X_blob_test, y_blob_test = X_blob_test.to(device), y_blob_test.to(device)
for epoch in range(epochs):
### Training
model_4.train()
# 1. Forward pass
y_logits = model_4(X_blob_train) # model outputs raw logits
y_pred = torch.softmax(y_logits, dim=1).argmax(dim=1) # go from logits -> prediction probabilities -> prediction labels
# print(y_logits)
# 2. Calculate loss and accuracy
loss = loss_fn(y_logits, y_blob_train)
acc = accuracy_fn(y_true=y_blob_train,
y_pred=y_pred)
# 3. Optimizer zero grad
optimizer.zero_grad()
# 4. Loss backwards
loss.backward()
# 5. Optimizer step
optimizer.step()
### Testing
model_4.eval()
with torch.inference_mode():
# 1. Forward pass
test_logits = model_4(X_blob_test)
test_pred = torch.softmax(test_logits, dim=1).argmax(dim=1)
# 2. Calculate test loss and accuracy
test_loss = loss_fn(test_logits, y_blob_test)
test_acc = accuracy_fn(y_true=y_blob_test,
y_pred=test_pred)
# Print out what's happening
if epoch % 10 == 0:
print(f"Epoch: {epoch} | Loss: {loss:.5f}, Acc: {acc:.2f}% | Test Loss: {test_loss:.5f}, Test Acc: {test_acc:.2f}%")
Epoch: 0 | Loss: 1.04324, Acc: 65.50% | Test Loss: 0.57861, Test Acc: 95.50% Epoch: 10 | Loss: 0.14398, Acc: 99.12% | Test Loss: 0.13037, Test Acc: 99.00% Epoch: 20 | Loss: 0.08062, Acc: 99.12% | Test Loss: 0.07216, Test Acc: 99.50% Epoch: 30 | Loss: 0.05924, Acc: 99.12% | Test Loss: 0.05133, Test Acc: 99.50% Epoch: 40 | Loss: 0.04892, Acc: 99.00% | Test Loss: 0.04098, Test Acc: 99.50% Epoch: 50 | Loss: 0.04295, Acc: 99.00% | Test Loss: 0.03486, Test Acc: 99.50% Epoch: 60 | Loss: 0.03910, Acc: 99.00% | Test Loss: 0.03083, Test Acc: 99.50% Epoch: 70 | Loss: 0.03643, Acc: 99.00% | Test Loss: 0.02799, Test Acc: 99.50% Epoch: 80 | Loss: 0.03448, Acc: 99.00% | Test Loss: 0.02587, Test Acc: 99.50% Epoch: 90 | Loss: 0.03300, Acc: 99.12% | Test Loss: 0.02423, Test Acc: 99.50%
# Make predictions
model_4.eval()
with torch.inference_mode():
y_logits = model_4(X_blob_test)
# View the first 10 predictions
y_logits[:10]
tensor([[ 4.3377, 10.3539, -14.8948, -9.7642],
[ 5.0142, -12.0371, 3.3860, 10.6699],
[ -5.5885, -13.3448, 20.9894, 12.7711],
[ 1.8400, 7.5599, -8.6016, -6.9942],
[ 8.0726, 3.2906, -14.5998, -3.6186],
[ 5.5844, -14.9521, 5.0168, 13.2890],
[ -5.9739, -10.1913, 18.8655, 9.9179],
[ 7.0755, -0.7601, -9.5531, 0.1736],
[ -5.5918, -18.5990, 25.5309, 17.5799],
[ 7.3142, 0.7197, -11.2017, -1.2011]], device='cuda:0')
好的,看起来我们的模型预测结果仍然是logit形式。
虽然要评估它们,它们必须与我们的标签(y_blob_test)形式相同,即整数形式。
让我们将模型的预测logits转换为预测概率(使用torch.softmax()),然后再转换为预测标签(通过取每个样本的argmax())。
注意: 可以直接跳过
torch.softmax()函数,从预测logits -> 预测标签,通过直接在logits上调用torch.argmax()。例如,
y_preds = torch.argmax(y_logits, dim=1),这样可以节省一个计算步骤(不需要torch.softmax()),但结果是没有可用的预测概率。
# Turn predicted logits in prediction probabilities
y_pred_probs = torch.softmax(y_logits, dim=1)
# Turn prediction probabilities into prediction labels
y_preds = y_pred_probs.argmax(dim=1)
# Compare first 10 model preds and test labels
print(f"Predictions: {y_preds[:10]}\nLabels: {y_blob_test[:10]}")
print(f"Test accuracy: {accuracy_fn(y_true=y_blob_test, y_pred=y_preds)}%")
Predictions: tensor([1, 3, 2, 1, 0, 3, 2, 0, 2, 0], device='cuda:0') Labels: tensor([1, 3, 2, 1, 0, 3, 2, 0, 2, 0], device='cuda:0') Test accuracy: 99.5%
太棒了!我们的模型预测结果现在与测试标签的格式一致了。
让我们用 plot_decision_boundary() 来可视化它们。记住,由于我们的数据在 GPU 上,我们需要将其移动到 CPU 上以便使用 matplotlib(plot_decision_boundary() 会自动为我们完成这一操作)。
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.title("Train")
plot_decision_boundary(model_4, X_blob_train, y_blob_train)
plt.subplot(1, 2, 2)
plt.title("Test")
plot_decision_boundary(model_4, X_blob_test, y_blob_test)

9. 更多分类评估指标¶
到目前为止,我们只涵盖了几种评估分类模型的方法(准确性、损失和可视化预测结果)。
这些是你会遇到的一些最常见的方法,是一个很好的起点。
然而,你可能希望使用更多的指标来评估你的分类模型,例如以下几种:
| 指标名称/评估方法 | 定义 | 代码 |
|---|---|---|
| 准确性 | 在100个预测中,你的模型能正确预测多少个?例如,95%的准确性意味着模型能正确预测95/100个预测。 | torchmetrics.Accuracy() 或 sklearn.metrics.accuracy_score() |
| 精确度 | 真阳性样本占所有样本的比例。更高的精确度意味着更少的假阳性(模型预测为1但实际上应该是0)。 | torchmetrics.Precision() 或 sklearn.metrics.precision_score() |
| 召回率 | 真阳性样本占所有真阳性和假阴性样本的比例(模型预测为0但实际上应该是1)。更高的召回率意味着更少的假阴性。 | torchmetrics.Recall() 或 sklearn.metrics.recall_score() |
| F1分数 | 将精确度和召回率结合为一个指标。1是最好的,0是最差的。 | torchmetrics.F1Score() 或 sklearn.metrics.f1_score() |
| 混淆矩阵 | 以表格方式比较预测值和真实值,如果100%正确,矩阵中的所有值将从左上角到右下角(对角线)。 | torchmetrics.ConfusionMatrix 或 sklearn.metrics.plot_confusion_matrix() |
| 分类报告 | 收集了一些主要的分类指标,如精确度、召回率和F1分数。 | sklearn.metrics.classification_report() |
Scikit-Learn(一个流行且世界级的机器学习库)有许多上述指标的实现,如果你在寻找类似PyTorch的版本,可以查看TorchMetrics,特别是TorchMetrics分类部分。
让我们尝试一下torchmetrics.Accuracy指标。
try:
from torchmetrics import Accuracy
except:
!pip install torchmetrics==0.9.3 # this is the version we're using in this notebook (later versions exist here: https://torchmetrics.readthedocs.io/en/stable/generated/CHANGELOG.html#changelog)
from torchmetrics import Accuracy
# Setup metric and make sure it's on the target device
torchmetrics_accuracy = Accuracy(task='multiclass', num_classes=4).to(device)
# Calculate accuracy
torchmetrics_accuracy(y_preds, y_blob_test)
tensor(0.9950, device='cuda:0')
练习¶
所有练习都集中在练习上述章节中的代码。
你应该能够通过参考每个章节或遵循链接的资源来完成这些练习。
所有练习都应该使用设备无关代码完成。
资源:
- 02章节的练习模板笔记本
- 02章节的示例解决方案笔记本(尝试练习之前查看此内容)
- 使用Scikit-Learn的
make_moons()函数创建一个二分类数据集。- 为了保持一致性,数据集应该有1000个样本,并且
random_state=42。 - 将数据转换为PyTorch张量。使用
train_test_split将数据分为训练集和测试集,其中80%为训练集,20%为测试集。
- 为了保持一致性,数据集应该有1000个样本,并且
- 通过子类化
nn.Module构建一个包含非线性激活函数的模型,该模型能够拟合你在第1步中创建的数据。- 可以自由使用任何PyTorch层的组合(线性和非线性)。
- 设置一个适用于二分类的损失函数和优化器,以便在训练模型时使用。
- 创建一个训练和测试循环,将你在第2步中创建的模型拟合到你在第1步中创建的数据上。
- 为了测量模型准确性,可以创建自己的准确性函数或使用TorchMetrics中的准确性函数。
- 训练模型直到其准确性超过96%。
- 训练循环应该每10个周期输出一次模型的训练集和测试集的损失和准确性。
- 使用训练好的模型进行预测,并使用本笔记本中创建的
plot_decision_boundary()函数绘制预测结果。 - 在纯PyTorch中复制Tanh(双曲正切)激活函数。
- 可以参考ML cheatsheet网站的公式。
- 使用CS231n的螺旋数据创建函数创建一个多分类数据集(见下面的代码)。
- 构建一个能够拟合数据的模型(你可能需要线性和非线性层的组合)。
- 构建一个能够处理多分类数据的损失函数和优化器(可选扩展:使用Adam优化器而不是SGD,你可能需要尝试不同的学习率值以使其工作)。
- 为多分类数据创建一个训练和测试循环,并在其上训练一个模型以达到超过95%的测试准确性(你可以使用任何你喜欢的准确性测量函数)。
- 在你的模型预测中绘制螺旋数据集的决策边界,
plot_decision_boundary()函数应该也适用于此数据集。
# 创建螺旋数据集的代码来自CS231n
import numpy as np
N = 100 # 每个类的点数
D = 2 # 维度
K = 3 # 类别数
X = np.zeros((N*K,D)) # 数据矩阵(每行 = 单个样本)
y = np.zeros(N*K, dtype='uint8') # 类别标签
for j in range(K):
ix = range(N*j,N*(j+1))
r = np.linspace(0.0,1,N) # 半径
t = np.linspace(j*4,(j+1)*4,N) + np.random.randn(N)*0.2 # 角度
X[ix] = np.c_[r*np.sin(t), r*np.cos(t)]
y[ix] = j
# 让我们可视化数据
plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.Spectral)
plt.show()
额外课程¶
- 写下3个你认为机器分类可能有用的场景(这些可以是任何东西,尽情发挥创意,例如,根据购买金额和购买地点特征将信用卡交易分类为欺诈或非欺诈)。
- 研究基于梯度的优化器(如SGD或Adam)中的“动量”概念,这意味着什么?
- 花10分钟阅读不同激活函数的Wikipedia页面,你能将其中多少与PyTorch的激活函数对应起来?
- 研究何时准确性可能是一个糟糕的指标(提示:阅读"Beyond Accuracy" by Will Koehrsen以获取想法)。
- 观看: 为了了解我们的神经网络内部发生了什么以及它们是如何学习的,观看MIT的深度学习介绍视频。