01. PyTorch 工作流程基础¶
机器学习和深度学习的精髓在于利用历史数据,构建算法(如神经网络)来发现其中的模式,并利用这些发现的模式来预测未来。
实现这一点的方法有很多,而且不断有新的方法被发现。
但让我们从简单开始。
不如我们从一条直线开始?
看看我们是否能构建一个 PyTorch 模型,让它学习这条直线的模式并与之匹配。
我们将涵盖的内容¶
在本模块中,我们将介绍一个标准的 PyTorch 工作流程(可以根据需要进行调整,但它涵盖了主要步骤的概要)。
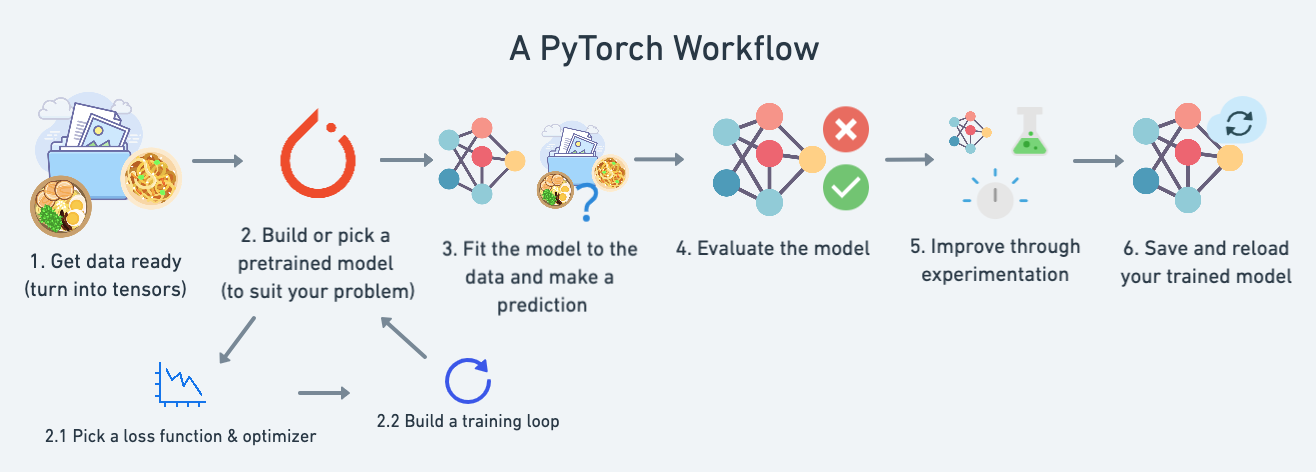
目前,我们将使用这个工作流程来预测一条简单的直线,但这个工作流程的步骤可以根据你正在解决的问题进行重复和更改。
具体来说,我们将涵盖以下内容:
| 主题 | 内容 |
|---|---|
| 1. 准备数据 | 数据可以是任何东西,但为了入门,我们将创建一条简单的直线 |
| 2. 构建模型 | 在这里,我们将创建一个模型来学习数据中的模式,我们还将选择一个损失函数、优化器并构建一个训练循环。 |
| 3. 将模型拟合到数据(训练) | 我们已经有了数据和一个模型,现在让我们让模型(尝试)在(训练)数据中找到模式。 |
| 4. 进行预测和评估模型(推理) | 我们的模型已经在数据中找到了模式,让我们将它的发现与实际的(测试)数据进行比较。 |
| 5. 保存和加载模型 | 你可能希望在其他地方使用你的模型,或者稍后再回来使用它,这里我们将介绍这一点。 |
| 6. 综合所有内容 | 让我们将上述所有内容结合起来。 |
如何获取帮助?¶
本课程的所有资料都可以在 GitHub 上找到。
如果你遇到问题,也可以在 讨论页面 上提问。
此外,还有 PyTorch 开发者论坛,这是一个非常有助于解决所有 PyTorch 相关问题的平台。
让我们先将要涵盖的内容放入一个字典中,以便日后参考。
what_were_covering = {1: "data (prepare and load)",
2: "build model",
3: "fitting the model to data (training)",
4: "making predictions and evaluating a model (inference)",
5: "saving and loading a model",
6: "putting it all together"
}
现在让我们导入这个模块所需的库。
我们将引入 torch、torch.nn(nn 代表神经网络,这个包包含了在 PyTorch 中创建神经网络的构建块)和 matplotlib。
import torch
from torch import nn # nn contains all of PyTorch's building blocks for neural networks
import matplotlib.pyplot as plt
# Check PyTorch version
torch.__version__
'1.12.1+cu113'
1. 数据(准备与加载)¶
我必须强调,机器学习中的“数据”可以是几乎你能想象到的任何东西。比如一个数字表格(就像一个巨大的Excel电子表格)、各种图像、视频(YouTube上有很多数据!)、音频文件如歌曲或播客、蛋白质结构、文本等等。
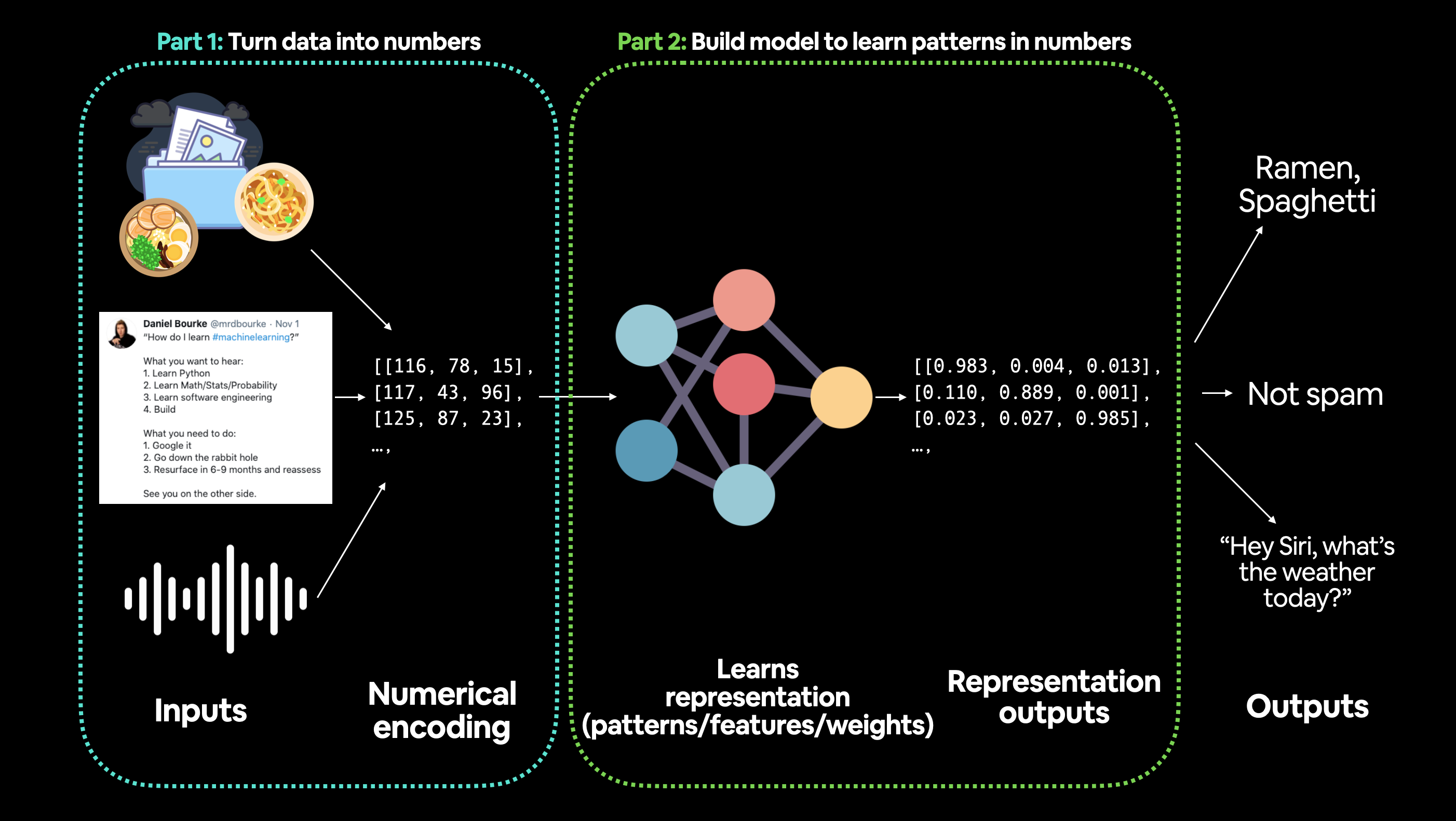
机器学习可以分为两个部分:
- 将你的数据,无论是什么,转化为数字(一种表示)。
- 选择或构建一个模型以尽可能好地学习这种表示。
有时候,这两个步骤可以同时进行。
但如果你没有数据怎么办?
嗯,这就是我们现在面临的情况。
没有数据。
但我们可以创造一些。
让我们创建一条直线作为数据。
我们将使用线性回归来生成具有已知参数(模型可以学习的东西)的数据,然后我们将使用PyTorch来构建一个模型,通过梯度下降来估计这些参数。
如果上面的术语现在对你来说意义不大,不用担心,我们会在实践中看到它们,我也会在下面提供额外的资源,你可以进一步学习。
# Create *known* parameters
weight = 0.7
bias = 0.3
# Create data
start = 0
end = 1
step = 0.02
X = torch.arange(start, end, step).unsqueeze(dim=1)
y = weight * X + bias
X[:10], y[:10]
(tensor([[0.0000],
[0.0200],
[0.0400],
[0.0600],
[0.0800],
[0.1000],
[0.1200],
[0.1400],
[0.1600],
[0.1800]]),
tensor([[0.3000],
[0.3140],
[0.3280],
[0.3420],
[0.3560],
[0.3700],
[0.3840],
[0.3980],
[0.4120],
[0.4260]]))
太棒了!现在我们将朝着构建一个能够学习 X(特征)和 y(标签)之间关系的模型迈进。
将数据分为训练集和测试集¶
我们已经有了一些数据。
但在建立模型之前,我们需要将其拆分开来。
机器学习项目中最重要的步骤之一是创建训练集和测试集(以及在需要时创建验证集)。
数据集的每个拆分都服务于特定的目的:
| 拆分 | 目的 | 占总体数据的比例 | 使用频率 |
|---|---|---|---|
| 训练集 | 模型从这些数据中学习(就像你在学期中学习的课程材料)。 | 约60-80% | 总是 |
| 验证集 | 模型在这些数据上进行调优(就像你在期末考试前参加的模拟考试)。 | 约10-20% | 经常但不总是 |
| 测试集 | 模型在这些数据上进行评估,以测试其学习成果(就像你在学期末参加的期末考试)。 | 约10-20% | 总是 |
目前,我们将只使用训练集和测试集,这意味着我们将有一个数据集供模型学习,并对其进行评估。
我们可以通过拆分我们的 X 和 y 张量来创建它们。
注意: 在处理真实世界的数据时,这一步骤通常在项目开始时就完成(测试集应始终与其他数据分开)。我们希望模型在训练数据上学习,然后在测试数据上进行评估,以了解其对未见示例的泛化能力。
# Create train/test split
train_split = int(0.8 * len(X)) # 80% of data used for training set, 20% for testing
X_train, y_train = X[:train_split], y[:train_split]
X_test, y_test = X[train_split:], y[train_split:]
len(X_train), len(y_train), len(X_test), len(y_test)
(40, 40, 10, 10)
太好了,我们有40个样本用于训练(X_train 和 y_train),以及10个样本用于测试(X_test 和 y_test)。
我们创建的模型将尝试学习 X_train 和 y_train 之间的关系,然后我们将在 X_test 和 y_test 上评估它的学习成果。
但现在我们的数据还只是纸上的数字。
让我们创建一个函数来可视化这些数据。
def plot_predictions(train_data=X_train,
train_labels=y_train,
test_data=X_test,
test_labels=y_test,
predictions=None):
"""
Plots training data, test data and compares predictions.
"""
plt.figure(figsize=(10, 7))
# Plot training data in blue
plt.scatter(train_data, train_labels, c="b", s=4, label="Training data")
# Plot test data in green
plt.scatter(test_data, test_labels, c="g", s=4, label="Testing data")
if predictions is not None:
# Plot the predictions in red (predictions were made on the test data)
plt.scatter(test_data, predictions, c="r", s=4, label="Predictions")
# Show the legend
plt.legend(prop={"size": 14});
plot_predictions();

太棒了!
现在,我们的数据不再只是纸上的数字,而是一条直线。
注意: 现在是时候向你介绍数据探索者的座右铭了...“可视化,可视化,可视化!”
每当你在处理数据并将其转化为数字时,请记住这一点,如果你能将数据可视化,它将极大地帮助你理解数据。
机器喜欢数字,我们人类也喜欢数字,但我们还喜欢看东西。
# Create a Linear Regression model class
class LinearRegressionModel(nn.Module): # <- almost everything in PyTorch is a nn.Module (think of this as neural network lego blocks)
def __init__(self):
super().__init__()
self.weights = nn.Parameter(torch.randn(1, # <- start with random weights (this will get adjusted as the model learns)
dtype=torch.float), # <- PyTorch loves float32 by default
requires_grad=True) # <- can we update this value with gradient descent?)
self.bias = nn.Parameter(torch.randn(1, # <- start with random bias (this will get adjusted as the model learns)
dtype=torch.float), # <- PyTorch loves float32 by default
requires_grad=True) # <- can we update this value with gradient descent?))
# Forward defines the computation in the model
def forward(self, x: torch.Tensor) -> torch.Tensor: # <- "x" is the input data (e.g. training/testing features)
return self.weights * x + self.bias # <- this is the linear regression formula (y = m*x + b)
好的,上面的内容有点多,让我们一点一点地来解析。
资源: 我们将使用 Python 类来创建构建神经网络所需的各种组件。如果你不熟悉 Python 类的表示法,我建议你多次阅读 Real Python 的 Python 3 面向对象编程指南。
PyTorch 模型构建要点¶
PyTorch 有四个(或多或少)基本模块,你可以利用它们创建几乎任何你能想象的神经网络。
它们是 torch.nn、torch.optim、torch.utils.data.Dataset 和 torch.utils.data.DataLoader。目前,我们将重点放在前两个模块上,稍后再介绍另外两个(尽管你可能已经猜到它们的作用)。
| PyTorch 模块 | 功能描述 |
|---|---|
torch.nn |
包含所有计算图的构建块(本质上是一系列以特定方式执行的计算)。 |
torch.nn.Parameter |
存储可以与 nn.Module 一起使用的张量。如果 requires_grad=True,则会自动计算梯度(用于通过梯度下降更新模型参数),这通常被称为“自动梯度”。 |
torch.nn.Module |
所有神经网络模块的基类,神经网络的所有构建块都是其子类。如果你在 PyTorch 中构建神经网络,你的模型应该继承 nn.Module。需要实现 forward() 方法。 |
torch.optim |
包含各种优化算法(这些算法告诉存储在 nn.Parameter 中的模型参数如何最好地改变以改善梯度下降,进而减少损失)。 |
def forward() |
所有 nn.Module 子类都需要一个 forward() 方法,这定义了在传递给特定 nn.Module 的数据上将进行的计算(例如上面的线性回归公式)。 |
如果上面的内容听起来复杂,可以这样理解:PyTorch 神经网络中的几乎所有东西都来自 torch.nn,
nn.Module包含较大的构建块(层)nn.Parameter包含较小的参数,如权重和偏差(将这些组合在一起以构建nn.Module)forward()告诉较大的块如何在nn.Module中对输入(充满数据的张量)进行计算torch.optim包含优化方法,用于改善nn.Parameter中的参数,以更好地表示输入数据
 通过继承
通过继承 nn.Module 创建 PyTorch 模型的基本构建块。对于继承 nn.Module 的对象,必须定义 forward() 方法。
资源: 在 PyTorch 速查表 中查看这些基本模块及其用例的更多信息。
检查 PyTorch 模型的内容¶
现在我们已经解决了这些问题,让我们使用我们创建的类来实例化一个模型,并使用 .parameters() 方法来检查其参数。
# Set manual seed since nn.Parameter are randomly initialzied
torch.manual_seed(42)
# Create an instance of the model (this is a subclass of nn.Module that contains nn.Parameter(s))
model_0 = LinearRegressionModel()
# Check the nn.Parameter(s) within the nn.Module subclass we created
list(model_0.parameters())
[Parameter containing: tensor([0.3367], requires_grad=True), Parameter containing: tensor([0.1288], requires_grad=True)]
我们还可以使用 .state_dict() 获取模型的状态(即模型包含的内容)。
# List named parameters
model_0.state_dict()
OrderedDict([('weights', tensor([0.3367])), ('bias', tensor([0.1288]))])
注意到从 model_0.state_dict() 中得到的 weights 和 bias 值是随机的浮点数张量吗?
这是因为我们在上面使用 torch.randn() 初始化了它们。
本质上,我们希望从随机的参数开始,让模型将这些参数更新为最适合我们数据的参数(即我们在创建直线数据时硬编码的 weight 和 bias 值)。
练习: 尝试更改上面两个单元格中的
torch.manual_seed()值,看看weights和bias值会发生什么变化。
由于我们的模型从随机值开始,目前它的预测能力会很差。
使用 torch.inference_mode() 进行预测¶
为了验证这一点,我们可以将测试数据 X_test 传递给它,看看它对 y_test 的预测有多接近。
当我们向模型传递数据时,数据会通过模型的 forward() 方法,并根据我们定义的计算产生结果。
让我们进行一些预测。
# Make predictions with model
with torch.inference_mode():
y_preds = model_0(X_test)
# Note: in older PyTorch code you might also see torch.no_grad()
# with torch.no_grad():
# y_preds = model_0(X_test)
嗯?
你可能注意到我们使用了 torch.inference_mode() 作为 上下文管理器(这就是 with torch.inference_mode(): 的作用)来进行预测。
顾名思义,torch.inference_mode() 用于模型推理(即进行预测)时。
torch.inference_mode() 关闭了一些功能(如梯度跟踪,这在训练中是必要的,但在推理中不需要),以使 前向传播(数据通过 forward() 方法)更快。
注意: 在较旧的 PyTorch 代码中,你可能会看到
torch.no_grad()用于推理。虽然torch.inference_mode()和torch.no_grad()作用类似,但torch.inference_mode()是较新的,可能更快,因此更受推荐。更多信息请参见 PyTorch 的这条推文。
我们已经进行了一些预测,让我们看看它们是什么样子的。
# Check the predictions
print(f"Number of testing samples: {len(X_test)}")
print(f"Number of predictions made: {len(y_preds)}")
print(f"Predicted values:\n{y_preds}")
Number of testing samples: 10
Number of predictions made: 10
Predicted values:
tensor([[0.3982],
[0.4049],
[0.4116],
[0.4184],
[0.4251],
[0.4318],
[0.4386],
[0.4453],
[0.4520],
[0.4588]])
注意到每个测试样本都有一个预测值。
这是因为我们使用的数据类型。对于我们的直线,一个 X 值对应一个 y 值。
然而,机器学习模型非常灵活。你可以有 100 个 X 值对应一个、两个、三个或十个 y 值。这一切都取决于你在做什么。
我们的预测仍然是纸上的数字,让我们用上面创建的 plot_predictions() 函数将它们可视化。
plot_predictions(predictions=y_preds)

y_test - y_preds
tensor([[0.4618],
[0.4691],
[0.4764],
[0.4836],
[0.4909],
[0.4982],
[0.5054],
[0.5127],
[0.5200],
[0.5272]])
哇哦!这些预测看起来相当糟糕...
不过,当你记得我们的模型只是使用随机参数值来进行预测时,这就不难理解了。
它甚至还没有看过蓝点来尝试预测绿点。
是时候改变这一点了。
3. 训练模型¶
目前,我们的模型在进行预测时使用随机参数进行计算,这基本上是在随机猜测。
为了解决这个问题,我们可以更新其内部参数(我也将这些参数称为模式),即我们使用 nn.Parameter() 和 torch.randn() 随机设置的 权重 和 偏差 值,使其更好地反映数据。
我们可以硬编码这些参数(因为我们知道默认值 weight=0.7 和 bias=0.3),但那样做有什么乐趣呢?
很多时候,你并不知道模型的理想参数是什么。
相反,编写代码让模型尝试自己找出这些参数会更有趣。
在 PyTorch 中创建损失函数和优化器¶
为了让我们的模型能够自行更新其参数,我们需要在我们的流程中添加一些内容。
这就是 损失函数 和 优化器。
它们的作用如下:
| 函数 | 作用 | 在 PyTorch 中的位置 | 常见值 |
|---|---|---|---|
| 损失函数 | 衡量模型的预测(例如 y_preds)与真实标签(例如 y_test)之间的差异。数值越低越好。 |
PyTorch 在 torch.nn 中提供了许多内置的损失函数。 |
回归问题的平均绝对误差(MAE,torch.nn.L1Loss())。二元分类问题的二元交叉熵(torch.nn.BCELoss())。 |
| 优化器 | 告诉模型如何更新其内部参数以最好地降低损失。 | 你可以在 torch.optim 中找到各种优化函数的实现。 |
随机梯度下降(torch.optim.SGD())。Adam 优化器(torch.optim.Adam())。 |
让我们创建一个损失函数和一个优化器,以便帮助改进我们的模型。
你正在解决的问题类型将决定你使用的损失函数和优化器。
然而,有一些常见的值被证明是有效的,例如 SGD(随机梯度下降)或 Adam 优化器。对于回归问题(预测一个数值),通常使用 MAE(平均绝对误差)损失函数;对于分类问题(预测是或否),通常使用二元交叉熵损失函数。
对于我们的问题,由于我们是在预测一个数值,让我们使用 PyTorch 中的 MAE(即 torch.nn.L1Loss())作为我们的损失函数。
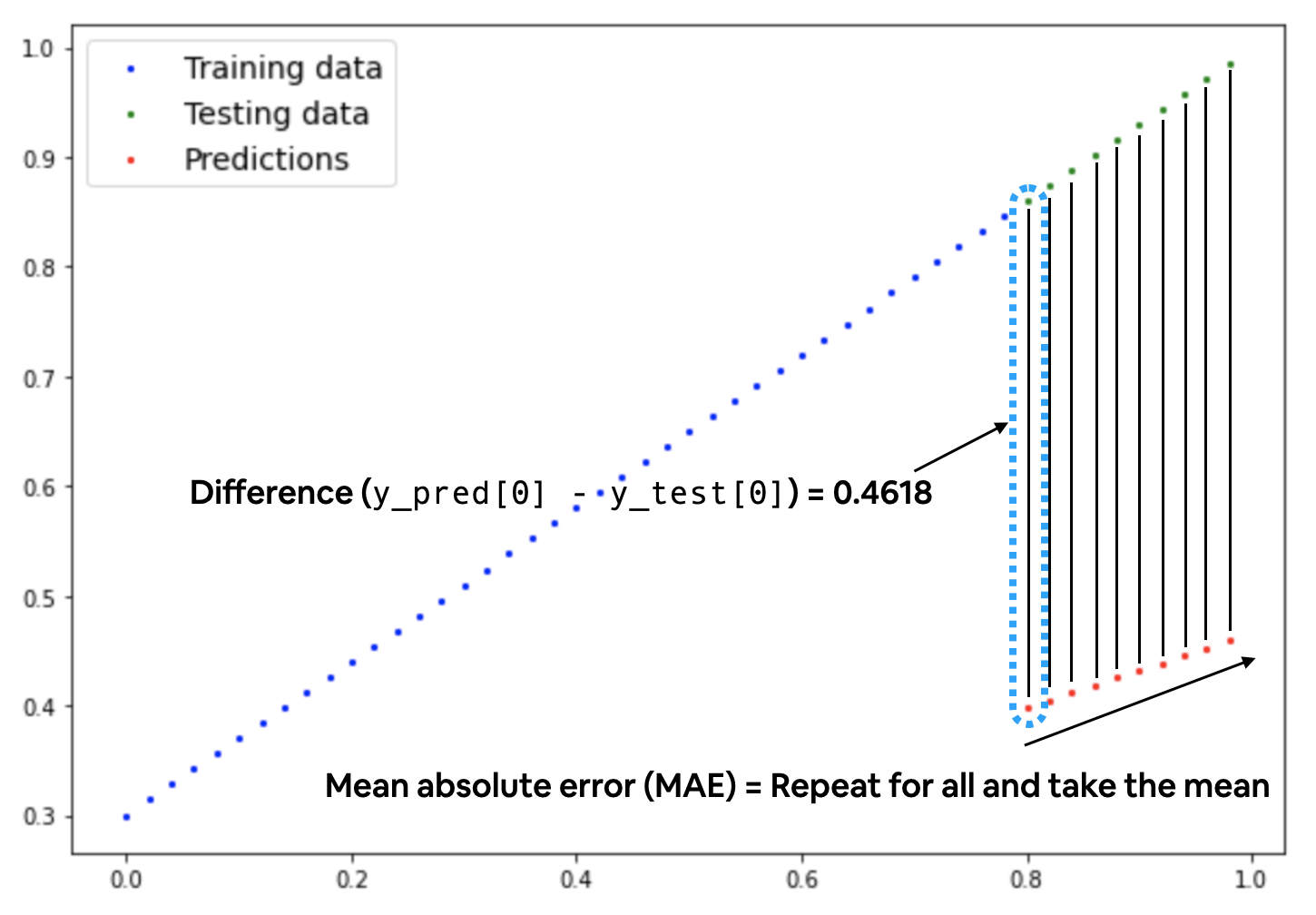 平均绝对误差(MAE,在 PyTorch 中为
平均绝对误差(MAE,在 PyTorch 中为 torch.nn.L1Loss)测量两个点(预测值和标签)之间的绝对差异,然后对所有样本取平均值。
我们将使用 SGD,即 torch.optim.SGD(params, lr),其中:
params是你希望优化的目标模型参数(例如之前随机设置的weights和bias值)。lr是你希望优化器更新参数的学习率,较高的学习率意味着优化器会尝试更大的更新(有时这些更新可能太大,导致优化器无法正常工作),较低的学习率意味着优化器会尝试更小的更新(有时这些更新可能太小,导致优化器花费太长时间找到理想值)。学习率被视为一个 超参数(因为它由机器学习工程师设置)。常见的学习率初始值为0.01、0.001、0.0001,然而,这些值也可以随着时间调整(这被称为学习率调度)。
哇,这内容真多,让我们看看代码实现。
# Create the loss function
loss_fn = nn.L1Loss() # MAE loss is same as L1Loss
# Create the optimizer
optimizer = torch.optim.SGD(params=model_0.parameters(), # parameters of target model to optimize
lr=0.01) # learning rate (how much the optimizer should change parameters at each step, higher=more (less stable), lower=less (might take a long time))
在 PyTorch 中创建优化循环¶
哇哦!现在我们有了损失函数和优化器,是时候创建一个训练循环(以及测试循环)了。
训练循环涉及模型遍历训练数据并学习 features 和 labels 之间的关系。
测试循环涉及遍历测试数据并评估模型在训练数据上学到的模式的优劣(模型在训练过程中从未见过测试数据)。
这些被称为“循环”,因为我们希望模型查看(遍历)每个数据集中的每个样本。
为了创建这些循环,我们将编写一个 Python 的 for 循环,主题来自非官方 PyTorch 优化循环歌曲(还有视频版本)。
 非官方 PyTorch 优化循环歌曲,一种有趣的方式来记住 PyTorch 训练(和测试)循环的步骤。
非官方 PyTorch 优化循环歌曲,一种有趣的方式来记住 PyTorch 训练(和测试)循环的步骤。
虽然会有相当多的代码,但我们完全可以应对。
PyTorch 训练循环¶
对于训练循环,我们将构建以下步骤:
| 编号 | 步骤名称 | 作用 | 代码示例 |
|---|---|---|---|
| 1 | 前向传播 | 模型遍历所有训练数据一次,执行其 forward() 函数计算。 |
model(x_train) |
| 2 | 计算损失 | 模型的输出(预测)与真实值进行比较,评估其错误程度。 | loss = loss_fn(y_pred, y_train) |
| 3 | 清零梯度 | 优化器的梯度被设置为零(默认情况下它们是累积的),以便为特定的训练步骤重新计算。 | optimizer.zero_grad() |
| 4 | 对损失进行反向传播 | 计算损失相对于每个待更新模型参数的梯度(每个 requires_grad=True 的参数)。这就是所谓的反向传播,因此称为“反向”。 |
loss.backward() |
| 5 | 更新优化器(梯度下降) | 根据损失梯度更新 requires_grad=True 的参数,以改进它们。 |
optimizer.step() |
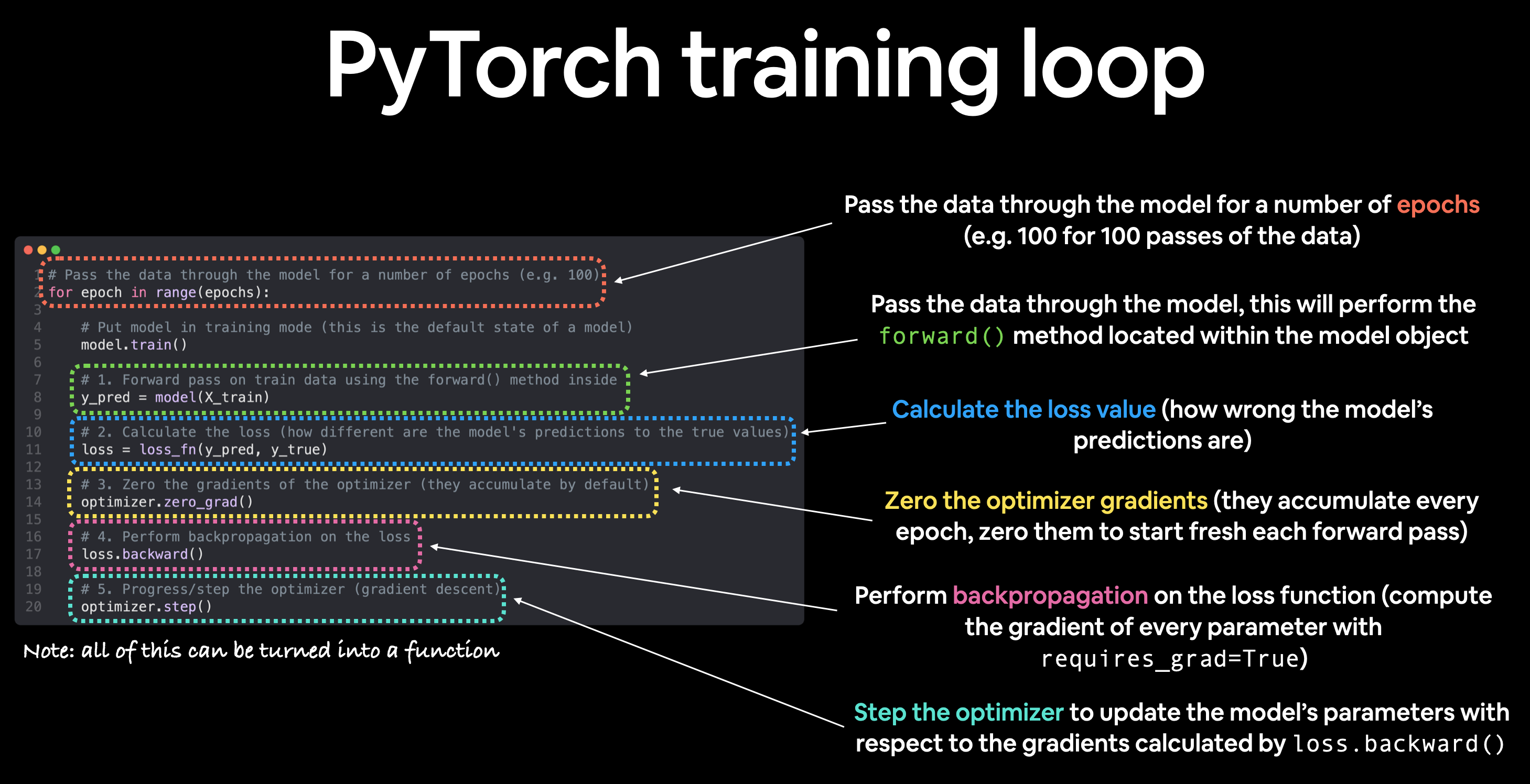
注意: 上述步骤的顺序或描述只是一个示例。随着经验的积累,你会发现构建 PyTorch 训练循环可以非常灵活。
至于步骤的顺序,上述是一个良好的默认顺序,但你可能会看到稍微不同的顺序。一些经验法则:
- 在执行反向传播(
loss.backward())之前计算损失(loss = ...)。- 在更新梯度(
optimizer.step())之前清零梯度(optimizer.zero_grad())。- 在执行反向传播(
loss.backward())之后更新优化器(optimizer.step())。
要了解反向传播和梯度下降背后的原理,请参阅额外课程部分。
PyTorch 测试循环¶
对于测试循环(评估我们的模型),典型的步骤包括:
| 编号 | 步骤名称 | 作用 | 代码示例 |
|---|---|---|---|
| 1 | 前向传播 | 模型遍历所有训练数据一次,执行其 forward() 函数计算。 |
model(x_test) |
| 2 | 计算损失 | 模型的输出(预测)与真实值进行比较,评估其错误程度。 | loss = loss_fn(y_pred, y_test) |
| 3 | 计算评估指标(可选) | 除了损失值外,你可能还想计算其他评估指标,如测试集上的准确率。 | 自定义函数 |
注意测试循环不包含反向传播(loss.backward())或优化器步进(optimizer.step()),因为在测试过程中模型的参数不会发生变化,它们已经计算好了。对于测试,我们只关心模型前向传播的输出。
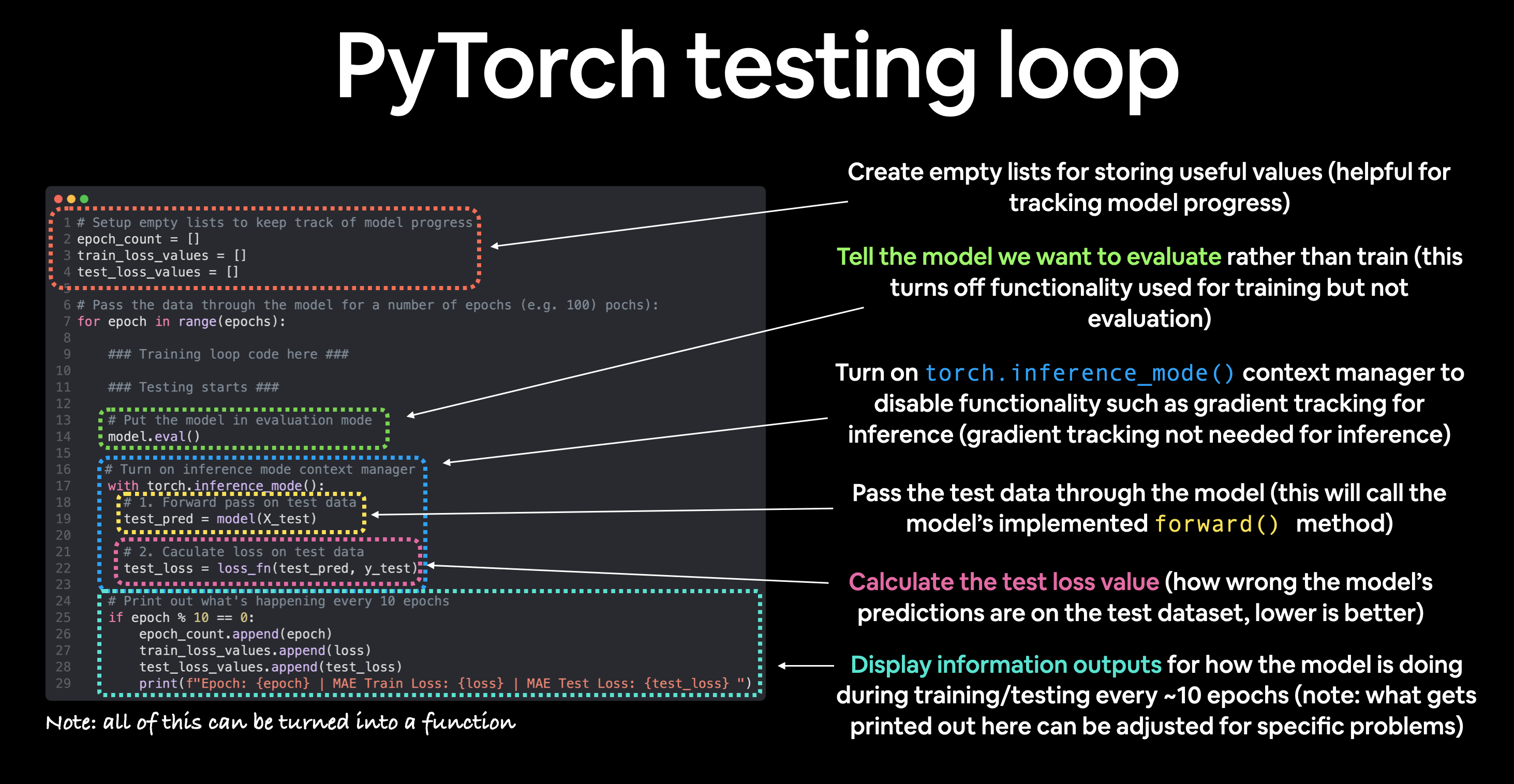
让我们把上述所有内容结合起来,训练我们的模型 100 个 epoch(数据前向传播),并且每 10 个 epoch 进行一次评估。
torch.manual_seed(42)
# Set the number of epochs (how many times the model will pass over the training data)
epochs = 100
# Create empty loss lists to track values
train_loss_values = []
test_loss_values = []
epoch_count = []
for epoch in range(epochs):
### Training
# Put model in training mode (this is the default state of a model)
model_0.train()
# 1. Forward pass on train data using the forward() method inside
y_pred = model_0(X_train)
# print(y_pred)
# 2. Calculate the loss (how different are our models predictions to the ground truth)
loss = loss_fn(y_pred, y_train)
# 3. Zero grad of the optimizer
optimizer.zero_grad()
# 4. Loss backwards
loss.backward()
# 5. Progress the optimizer
optimizer.step()
### Testing
# Put the model in evaluation mode
model_0.eval()
with torch.inference_mode():
# 1. Forward pass on test data
test_pred = model_0(X_test)
# 2. Caculate loss on test data
test_loss = loss_fn(test_pred, y_test.type(torch.float)) # predictions come in torch.float datatype, so comparisons need to be done with tensors of the same type
# Print out what's happening
if epoch % 10 == 0:
epoch_count.append(epoch)
train_loss_values.append(loss.detach().numpy())
test_loss_values.append(test_loss.detach().numpy())
print(f"Epoch: {epoch} | MAE Train Loss: {loss} | MAE Test Loss: {test_loss} ")
Epoch: 0 | MAE Train Loss: 0.31288138031959534 | MAE Test Loss: 0.48106518387794495 Epoch: 10 | MAE Train Loss: 0.1976713240146637 | MAE Test Loss: 0.3463551998138428 Epoch: 20 | MAE Train Loss: 0.08908725529909134 | MAE Test Loss: 0.21729660034179688 Epoch: 30 | MAE Train Loss: 0.053148526698350906 | MAE Test Loss: 0.14464017748832703 Epoch: 40 | MAE Train Loss: 0.04543796554207802 | MAE Test Loss: 0.11360953003168106 Epoch: 50 | MAE Train Loss: 0.04167863354086876 | MAE Test Loss: 0.09919948130846024 Epoch: 60 | MAE Train Loss: 0.03818932920694351 | MAE Test Loss: 0.08886633068323135 Epoch: 70 | MAE Train Loss: 0.03476089984178543 | MAE Test Loss: 0.0805937647819519 Epoch: 80 | MAE Train Loss: 0.03132382780313492 | MAE Test Loss: 0.07232122868299484 Epoch: 90 | MAE Train Loss: 0.02788739837706089 | MAE Test Loss: 0.06473556160926819
哦,你瞧瞧那个!看来我们的损失值随着每个周期在下降,我们来绘制一下图表看看。
# Plot the loss curves
plt.plot(epoch_count, train_loss_values, label="Train loss")
plt.plot(epoch_count, test_loss_values, label="Test loss")
plt.title("Training and test loss curves")
plt.ylabel("Loss")
plt.xlabel("Epochs")
plt.legend();

不错!损失曲线显示损失随着时间下降。记住,损失是衡量模型错误程度的指标,所以越低越好。
但为什么损失会下降呢?
嗯,多亏了我们的损失函数和优化器,模型的内部参数(权重和偏差)被更新,以更好地反映数据中的潜在模式。
让我们检查模型的.state_dict(),看看模型对我们在权重和偏差上设置的原始值的接近程度。
# Find our model's learned parameters
print("The model learned the following values for weights and bias:")
print(model_0.state_dict())
print("\nAnd the original values for weights and bias are:")
print(f"weights: {weight}, bias: {bias}")
The model learned the following values for weights and bias:
OrderedDict([('weights', tensor([0.5784])), ('bias', tensor([0.3513]))])
And the original values for weights and bias are:
weights: 0.7, bias: 0.3
哇!这有多酷啊?
我们的模型非常接近于计算出weight和bias的精确原始值(如果我们训练得更久,它可能会更接近)。
练习: 尝试将上面的
epochs值改为200,损失曲线以及模型的权重和偏置参数值会发生什么变化?
它很可能永远无法完美猜出这些值(尤其是在使用更复杂的数据集时),但这没关系,通常你可以用一个接近的近似值做很多很酷的事情。
这就是机器学习和深度学习的全部理念,有一些理想值可以描述我们的数据,而我们不是手动去计算这些值,而是可以训练一个模型以编程方式找出它们。
4. 使用训练好的PyTorch模型进行预测(推理)¶
一旦你训练了一个模型,你很可能会想要用它来进行预测。
我们已经在上述的训练和测试代码中看到了这一点,在训练/测试循环之外进行预测的步骤与之类似。
在使用PyTorch模型进行预测(也称为执行推理)时,有三点需要记住:
- 将模型设置为评估模式(
model.eval())。 - 使用推理模式上下文管理器进行预测(
with torch.inference_mode(): ...)。 - 所有预测应使用位于同一设备上的对象(例如,数据和模型仅在GPU上或数据和模型仅在CPU上)。
前两点确保了PyTorch在训练过程中使用的所有有助于计算和设置但在推理时不需要的功能都被关闭(这会加快计算速度)。第三点则确保你不会遇到跨设备错误。
# 1. Set the model in evaluation mode
model_0.eval()
# 2. Setup the inference mode context manager
with torch.inference_mode():
# 3. Make sure the calculations are done with the model and data on the same device
# in our case, we haven't setup device-agnostic code yet so our data and model are
# on the CPU by default.
# model_0.to(device)
# X_test = X_test.to(device)
y_preds = model_0(X_test)
y_preds
tensor([[0.8141],
[0.8256],
[0.8372],
[0.8488],
[0.8603],
[0.8719],
[0.8835],
[0.8950],
[0.9066],
[0.9182]])
不错!我们已经用训练好的模型进行了一些预测,那么结果看起来如何呢?
plot_predictions(predictions=y_preds)

哇哦!那些红点看起来比之前近多了!
接下来,让我们学习如何在 PyTorch 中保存和加载模型。
# 保存模型
torch.save(model.state_dict(), 'model.pth')
# 加载模型
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load('model.pth'))
model.eval()
5. 保存和加载 PyTorch 模型¶
如果你已经训练了一个 PyTorch 模型,很可能你会想要保存它并将其导出到某个地方。
比如,你可能会在 Google Colab 或带有 GPU 的本地机器上训练模型,但现在你希望将其导出到某种应用程序中,让其他人可以使用它。
或者,你可能希望保存模型的进度,并在以后回过来重新加载它。
在 PyTorch 中,保存和加载模型有三种主要方法你应该了解(以下内容均来自 PyTorch 保存和加载模型指南):
| PyTorch 方法 | 作用 |
|---|---|
torch.save |
使用 Python 的 pickle 工具将序列化对象保存到磁盘。可以使用 torch.save 保存模型、张量和各种其他 Python 对象,如字典。 |
torch.load |
使用 pickle 的解序列化功能将序列化的 Python 对象文件(如模型、张量或字典)反序列化并加载到内存中。你还可以设置加载对象的设备(CPU、GPU 等)。 |
torch.nn.Module.load_state_dict |
使用保存的 state_dict() 对象加载模型的参数字典(model.state_dict())。 |
注意: 如 Python 的
pickle文档 所述,pickle模块不安全。这意味着你只能解序列化(加载)你信任的数据。这也适用于加载 PyTorch 模型。只应使用来自可信来源的保存的 PyTorch 模型。
from pathlib import Path
# 1. Create models directory
MODEL_PATH = Path("models")
MODEL_PATH.mkdir(parents=True, exist_ok=True)
# 2. Create model save path
MODEL_NAME = "01_pytorch_workflow_model_0.pth"
MODEL_SAVE_PATH = MODEL_PATH / MODEL_NAME
# 3. Save the model state dict
print(f"Saving model to: {MODEL_SAVE_PATH}")
torch.save(obj=model_0.state_dict(), # only saving the state_dict() only saves the models learned parameters
f=MODEL_SAVE_PATH)
Saving model to: models/01_pytorch_workflow_model_0.pth
# Check the saved file path
!ls -l models/01_pytorch_workflow_model_0.pth
-rw-rw-r-- 1 daniel daniel 1063 Nov 10 16:07 models/01_pytorch_workflow_model_0.pth
加载保存的 PyTorch 模型的 state_dict()¶
由于我们现在已经在 models/01_pytorch_workflow_model_0.pth 路径下保存了模型的 state_dict(),我们可以使用 torch.nn.Module.load_state_dict(torch.load(f)) 来加载它,其中 f 是我们保存的模型 state_dict() 的文件路径。
为什么在 torch.nn.Module.load_state_dict() 内部调用 torch.load()?
因为我们只保存了模型的 state_dict(),这是一个包含学习参数的字典,而不是整个模型。首先,我们必须使用 torch.load() 加载 state_dict(),然后将这个 state_dict() 传递给我们的模型的新实例(它是 nn.Module 的子类)。
为什么不保存整个模型?
保存整个模型 而不是仅仅保存 state_dict() 可能更直观,但是,引用 PyTorch 文档(斜体部分是我加的):
这种方法(保存整个模型)的缺点是序列化数据绑定到保存模型时使用的特定类和确切目录结构...
因此,当在其他项目中使用或在重构后,您的代码可能会以各种方式崩溃。
因此,我们选择使用保存和加载 state_dict() 的灵活方法,这基本上是一个包含模型参数的字典。
让我们通过创建 LinearRegressionModel() 的另一个实例来测试一下,它是 torch.nn.Module 的子类,因此将具有内置方法 load_state_dict()。
# Instantiate a new instance of our model (this will be instantiated with random weights)
loaded_model_0 = LinearRegressionModel()
# Load the state_dict of our saved model (this will update the new instance of our model with trained weights)
loaded_model_0.load_state_dict(torch.load(f=MODEL_SAVE_PATH))
<All keys matched successfully>
太好了!看起来一切都很吻合。
现在,为了测试我们加载的模型,让我们在测试数据上用它进行推理(即进行预测)。
还记得使用 PyTorch 模型进行推理的规则吗?
如果没有,这里是一个复习:
PyTorch 推理规则
- 将模型设置为评估模式(
model.eval())。 - 使用推理模式上下文管理器进行预测(
with torch.inference_mode(): ...)。 - 所有预测都应该在同一设备上进行(例如,数据和模型都在 GPU 上,或者数据和模型都在 CPU 上)。
# 1. Put the loaded model into evaluation mode
loaded_model_0.eval()
# 2. Use the inference mode context manager to make predictions
with torch.inference_mode():
loaded_model_preds = loaded_model_0(X_test) # perform a forward pass on the test data with the loaded model
现在我们已经用加载的模型进行了一些预测,让我们看看它们是否与之前的预测相同。
# Compare previous model predictions with loaded model predictions (these should be the same)
y_preds == loaded_model_preds
tensor([[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True]])
太棒了!
看起来加载的模型预测结果与之前模型的预测结果(保存前的预测)一致。这表明我们的模型保存和加载功能正常。
注意: 还有更多保存和加载 PyTorch 模型的方法,但这些内容我将留给额外的课程和深入阅读。更多信息请参阅 PyTorch 保存和加载模型的指南。
6. 综合运用¶
到目前为止,我们已经涵盖了很多内容。
但一旦你进行了一些练习,你就会像在街上跳舞一样轻松执行上述步骤。
说到练习,让我们把之前所做的一切结合起来。
这一次,我们将使代码与设备无关(如果有GPU可用,它将使用GPU;如果没有,它将默认使用CPU)。
与前面的部分相比,这一节的注释会少得多,因为我们即将介绍的内容之前已经讲解过。
我们将首先导入所需的标准库。
注意: 如果你使用的是Google Colab,要设置GPU,请转到“运行时” -> “更改运行时类型” -> “硬件加速” -> “GPU”。如果你这样做,它会重置Colab运行时,并且你会丢失保存的变量。
# Import PyTorch and matplotlib
import torch
from torch import nn # nn contains all of PyTorch's building blocks for neural networks
import matplotlib.pyplot as plt
# Check PyTorch version
torch.__version__
'1.12.1+cu113'
现在让我们开始让代码设备无关,通过设置 device="cuda" 如果它可用,否则它将默认到 device="cpu"。
# Setup device agnostic code
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using device: {device}")
Using device: cuda
如果你能够访问GPU,上面的代码应该会输出:
Using device: cuda
否则,你将使用CPU进行后续的计算。这对于我们的小数据集来说是可以接受的,但对于更大的数据集,计算时间会更长。
6.1 数据¶
让我们像之前一样创建一些数据。
首先,我们将硬编码一些 weight 和 bias 值。
然后,我们将生成一个介于 0 和 1 之间的数字范围,这些将是我们的 X 值。
最后,我们将使用 X 值以及 weight 和 bias 值,通过线性回归公式(y = weight * X + bias)来创建 y。
# Create weight and bias
weight = 0.7
bias = 0.3
# Create range values
start = 0
end = 1
step = 0.02
# Create X and y (features and labels)
X = torch.arange(start, end, step).unsqueeze(dim=1) # without unsqueeze, errors will happen later on (shapes within linear layers)
y = weight * X + bias
X[:10], y[:10]
(tensor([[0.0000],
[0.0200],
[0.0400],
[0.0600],
[0.0800],
[0.1000],
[0.1200],
[0.1400],
[0.1600],
[0.1800]]),
tensor([[0.3000],
[0.3140],
[0.3280],
[0.3420],
[0.3560],
[0.3700],
[0.3840],
[0.3980],
[0.4120],
[0.4260]]))
太好了!
现在我们有了一些数据,让我们将其拆分为训练集和测试集。
我们将采用 80/20 的拆分比例,其中 80% 用于训练数据,20% 用于测试数据。
# Split data
train_split = int(0.8 * len(X))
X_train, y_train = X[:train_split], y[:train_split]
X_test, y_test = X[train_split:], y[train_split:]
len(X_train), len(y_train), len(X_test), len(y_test)
(40, 40, 10, 10)
很好,让我们将它们可视化,确保它们看起来没问题。
# Note: If you've reset your runtime, this function won't work,
# you'll have to rerun the cell above where it's instantiated.
plot_predictions(X_train, y_train, X_test, y_test)
6.2 构建一个 PyTorch 线性模型¶
我们已经有了一些数据,现在是时候构建一个模型了。
我们将创建与之前相同风格的模型,但这次,我们不再使用 nn.Parameter() 手动定义模型的权重和偏置参数,而是使用 nn.Linear(in_features, out_features) 来为我们完成这项工作。
其中 in_features 是输入数据的维度数量,out_features 是你希望输出数据的维度数量。
在我们的例子中,这两个值都是 1,因为我们的数据每个标签(y)有 1 个输入特征(X)。
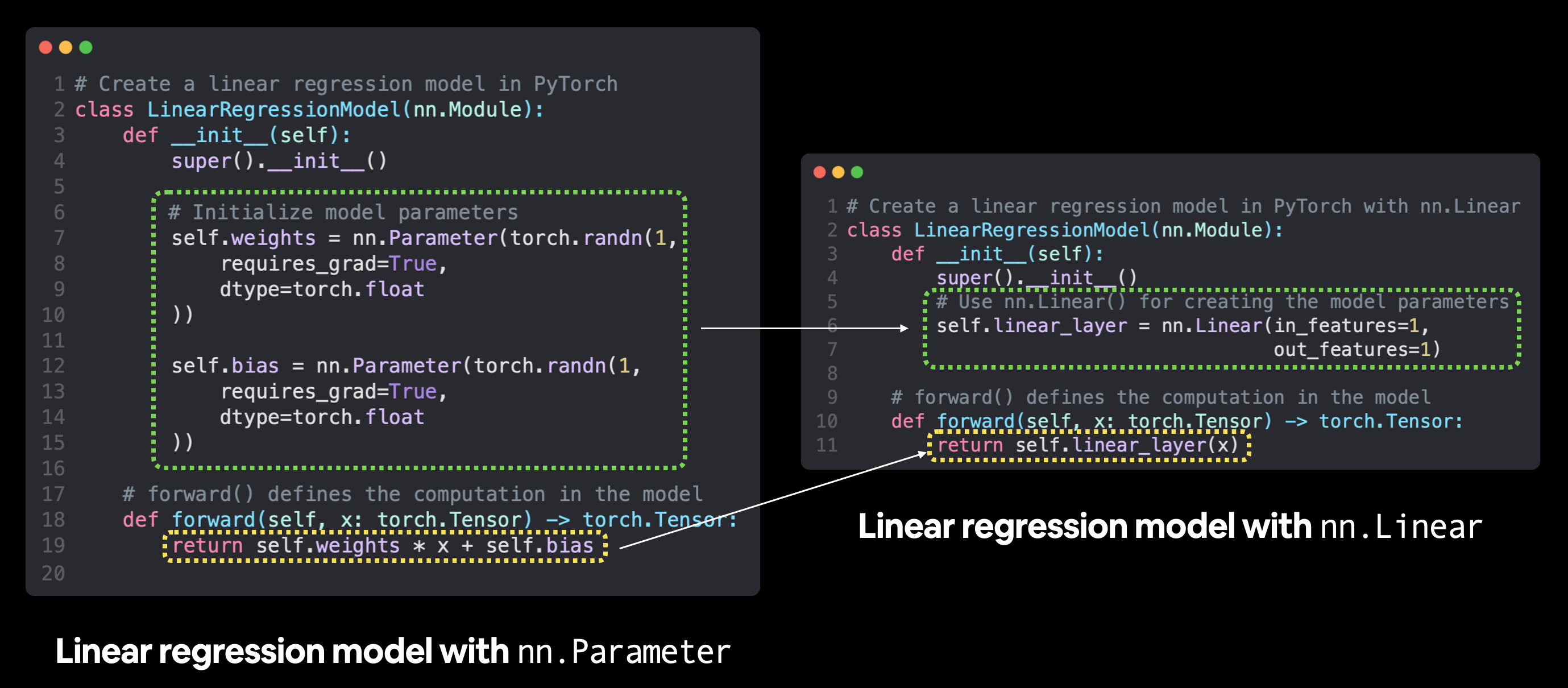 使用
使用 nn.Parameter 与 nn.Linear 创建线性回归模型的比较。torch.nn 模块中还有许多其他预构建的计算,包括许多流行且有用的神经网络层。
# Subclass nn.Module to make our model
class LinearRegressionModelV2(nn.Module):
def __init__(self):
super().__init__()
# Use nn.Linear() for creating the model parameters
self.linear_layer = nn.Linear(in_features=1,
out_features=1)
# Define the forward computation (input data x flows through nn.Linear())
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.linear_layer(x)
# Set the manual seed when creating the model (this isn't always need but is used for demonstrative purposes, try commenting it out and seeing what happens)
torch.manual_seed(42)
model_1 = LinearRegressionModelV2()
model_1, model_1.state_dict()
(LinearRegressionModelV2(
(linear_layer): Linear(in_features=1, out_features=1, bias=True)
),
OrderedDict([('linear_layer.weight', tensor([[0.7645]])),
('linear_layer.bias', tensor([0.8300]))]))
注意观察 model_1.state_dict() 的输出,nn.Linear() 层为我们创建了随机的 weight 和 bias 参数。
现在,让我们将模型放到 GPU 上(如果可用的话)。
我们可以使用 .to(device) 来改变 PyTorch 对象所在的设备。
首先,让我们检查模型当前所在的设备。
# Check model device
next(model_1.parameters()).device
device(type='cpu')
好的,看起来模型默认是在 CPU 上运行的。
我们将其改为在 GPU 上运行(如果 GPU 可用的话)。
# Set model to GPU if it's availalble, otherwise it'll default to CPU
model_1.to(device) # the device variable was set above to be "cuda" if available or "cpu" if not
next(model_1.parameters()).device
device(type='cuda', index=0)
太好了!由于我们的代码与设备无关,无论是否具备GPU,上述单元格都能正常运行。
如果你确实能够访问支持CUDA的GPU,你应该会看到类似如下的输出:
device(type='cuda', index=0)
6.3 训练¶
是时候构建一个训练和测试循环了。
首先,我们需要一个损失函数和一个优化器。
我们将使用之前用过的函数,nn.L1Loss() 和 torch.optim.SGD()。
我们需要将新模型的参数(model.parameters())传递给优化器,以便在训练过程中调整它们。
之前学习率 0.01 效果不错,所以我们再次使用这个值。
# Create loss function
loss_fn = nn.L1Loss()
# Create optimizer
optimizer = torch.optim.SGD(params=model_1.parameters(), # optimize newly created model's parameters
lr=0.01)
损失函数和优化器已经准备就绪,现在让我们使用训练和测试循环来训练和评估我们的模型。
与之前的训练循环相比,这一步我们唯一不同的操作是将数据放到目标 device 上。
我们已经通过 model_1.to(device) 将模型放到了目标 device 上。
我们也可以对数据进行同样的操作。
这样,如果模型在 GPU 上,数据也在 GPU 上(反之亦然)。
这次我们进一步提升难度,设置 epochs=1000。
如果你需要回顾 PyTorch 训练循环的步骤,请看下面的详细内容。
PyTorch 训练循环步骤
- 前向传播 - 模型遍历所有训练数据一次,执行其
forward()函数 计算(model(x_train))。 - 计算损失 - 模型的输出(预测值)与真实值进行比较,评估它们的误差
(
loss = loss_fn(y_pred, y_train))。 - 清零梯度 - 优化器的梯度被设置为零(默认情况下它们会被累积),以便为当前训练步骤重新计算
(
optimizer.zero_grad())。 - 对损失进行反向传播 - 计算损失相对于每个需要更新的模型参数的梯度
(每个参数
带有
requires_grad=True)。这就是所谓的 反向传播,因此称为“反向” (loss.backward())。 - 更新优化器(梯度下降) - 根据损失梯度更新带有
requires_grad=True的参数,以改进它们 (optimizer.step())。
torch.manual_seed(42)
# Set the number of epochs
epochs = 1000
# Put data on the available device
# Without this, error will happen (not all model/data on device)
X_train = X_train.to(device)
X_test = X_test.to(device)
y_train = y_train.to(device)
y_test = y_test.to(device)
for epoch in range(epochs):
### Training
model_1.train() # train mode is on by default after construction
# 1. Forward pass
y_pred = model_1(X_train)
# 2. Calculate loss
loss = loss_fn(y_pred, y_train)
# 3. Zero grad optimizer
optimizer.zero_grad()
# 4. Loss backward
loss.backward()
# 5. Step the optimizer
optimizer.step()
### Testing
model_1.eval() # put the model in evaluation mode for testing (inference)
# 1. Forward pass
with torch.inference_mode():
test_pred = model_1(X_test)
# 2. Calculate the loss
test_loss = loss_fn(test_pred, y_test)
if epoch % 100 == 0:
print(f"Epoch: {epoch} | Train loss: {loss} | Test loss: {test_loss}")
Epoch: 0 | Train loss: 0.5551779866218567 | Test loss: 0.5739762187004089 Epoch: 100 | Train loss: 0.006215683650225401 | Test loss: 0.014086711220443249 Epoch: 200 | Train loss: 0.0012645035749301314 | Test loss: 0.013801801018416882 Epoch: 300 | Train loss: 0.0012645035749301314 | Test loss: 0.013801801018416882 Epoch: 400 | Train loss: 0.0012645035749301314 | Test loss: 0.013801801018416882 Epoch: 500 | Train loss: 0.0012645035749301314 | Test loss: 0.013801801018416882 Epoch: 600 | Train loss: 0.0012645035749301314 | Test loss: 0.013801801018416882 Epoch: 700 | Train loss: 0.0012645035749301314 | Test loss: 0.013801801018416882 Epoch: 800 | Train loss: 0.0012645035749301314 | Test loss: 0.013801801018416882 Epoch: 900 | Train loss: 0.0012645035749301314 | Test loss: 0.013801801018416882
注意: 由于机器学习的随机性,根据模型是在 CPU 还是 GPU 上训练的,你可能会得到略有不同的结果(不同的损失值和预测值)。即使在任一设备上使用相同的随机种子,这种情况也存在。如果差异较大,你可能需要检查错误,但如果差异很小(理想情况下应该是这样),你可以忽略它。
很好!那个损失值看起来相当低。
让我们检查一下模型学到的参数,并与我们硬编码的原始参数进行比较。
# Find our model's learned parameters
from pprint import pprint # pprint = pretty print, see: https://docs.python.org/3/library/pprint.html
print("The model learned the following values for weights and bias:")
pprint(model_1.state_dict())
print("\nAnd the original values for weights and bias are:")
print(f"weights: {weight}, bias: {bias}")
The model learned the following values for weights and bias:
OrderedDict([('linear_layer.weight', tensor([[0.6968]], device='cuda:0')),
('linear_layer.bias', tensor([0.3025], device='cuda:0'))])
And the original values for weights and bias are:
weights: 0.7, bias: 0.3
呵呵!现在这个模型已经非常接近完美了。
不过要记住,在实际应用中,我们很少能事先知道完美的参数。
如果事先就知道模型需要学习的参数,那机器学习的乐趣又在哪里呢?
而且,在许多现实世界的机器学习问题中,参数的数量可能远远超过数千万。
我不知道你怎么想,但我宁愿编写代码让计算机来解决这些问题,而不是手动去做。
6.4 进行预测¶
现在我们已经有了一个训练好的模型,让我们将其切换到评估模式并进行一些预测。
# Turn model into evaluation mode
model_1.eval()
# Make predictions on the test data
with torch.inference_mode():
y_preds = model_1(X_test)
y_preds
tensor([[0.8600],
[0.8739],
[0.8878],
[0.9018],
[0.9157],
[0.9296],
[0.9436],
[0.9575],
[0.9714],
[0.9854]], device='cuda:0')
如果你正在使用GPU上的数据进行预测,你可能会注意到上述输出的末尾有device='cuda:0'。这意味着数据位于CUDA设备0(由于零索引,这是你的系统可以访问的第一块GPU),如果你将来使用多块GPU,这个数字可能会更高。
现在让我们绘制模型的预测结果。
注意: 许多数据科学库,如pandas、matplotlib和NumPy,无法使用存储在GPU上的数据。因此,当你尝试使用这些库中的函数处理未存储在CPU上的张量数据时,可能会遇到一些问题。为了解决这个问题,你可以调用
.cpu()方法,将目标张量复制到CPU上。
# plot_predictions(predictions=y_preds) # -> won't work... data not on CPU
# Put data on the CPU and plot it
plot_predictions(predictions=y_preds.cpu())

哇!看那些红点,它们几乎完美地与绿点对齐了。看来增加的训练周期确实有帮助。
6.5 保存和加载模型¶
我们对模型的预测结果感到满意,因此将其保存到文件中,以便日后使用。
from pathlib import Path
# 1. Create models directory
MODEL_PATH = Path("models")
MODEL_PATH.mkdir(parents=True, exist_ok=True)
# 2. Create model save path
MODEL_NAME = "01_pytorch_workflow_model_1.pth"
MODEL_SAVE_PATH = MODEL_PATH / MODEL_NAME
# 3. Save the model state dict
print(f"Saving model to: {MODEL_SAVE_PATH}")
torch.save(obj=model_1.state_dict(), # only saving the state_dict() only saves the models learned parameters
f=MODEL_SAVE_PATH)
Saving model to: models/01_pytorch_workflow_model_1.pth
为了确保一切运行正常,我们将其重新加载进来。
我们将:
- 创建一个新的
LinearRegressionModelV2()类实例 - 使用
torch.nn.Module.load_state_dict()加载模型状态字典 - 将新实例的模型发送到目标设备(以确保我们的代码是设备无关的)
# Instantiate a fresh instance of LinearRegressionModelV2
loaded_model_1 = LinearRegressionModelV2()
# Load model state dict
loaded_model_1.load_state_dict(torch.load(MODEL_SAVE_PATH))
# Put model to target device (if your data is on GPU, model will have to be on GPU to make predictions)
loaded_model_1.to(device)
print(f"Loaded model:\n{loaded_model_1}")
print(f"Model on device:\n{next(loaded_model_1.parameters()).device}")
Loaded model: LinearRegressionModelV2( (linear_layer): Linear(in_features=1, out_features=1, bias=True) ) Model on device: cuda:0
现在我们可以评估加载的模型,看看它的预测是否与保存之前的预测一致。
# Evaluate loaded model
loaded_model_1.eval()
with torch.inference_mode():
loaded_model_1_preds = loaded_model_1(X_test)
y_preds == loaded_model_1_preds
tensor([[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True]], device='cuda:0')
一切都有意义!太棒了!
好了,我们已经走了很长的路。你现在已经在PyTorch中构建并训练了你的前两个神经网络模型!
是时候练习你的技能了。
练习¶
所有练习均受到本笔记本中代码的启发。
每个主要部分对应一个练习。
您应该能够通过参考其特定部分来完成它们。
注意: 对于所有练习,您的代码应该是设备无关的(这意味着它可以在 CPU 或 GPU 上运行,如果可用的话)。
- 使用线性回归公式(
weight * X + bias)创建一条直线数据集。- 设置
weight=0.3和bias=0.9,总数据点至少为 100 个。 - 将数据分为 80% 训练集和 20% 测试集。
- 绘制训练和测试数据,使其可视化。
- 设置
- 通过子类化
nn.Module构建一个 PyTorch 模型。- 内部应包含一个随机初始化的
nn.Parameter(),设置requires_grad=True,分别用于weights和bias。 - 实现
forward()方法来计算您在第 1 部分中用于创建数据集的线性回归函数。 - 构建模型后,创建其实例并检查其
state_dict()。 - 注意: 如果您愿意,可以使用
nn.Linear()代替nn.Parameter()。
- 内部应包含一个随机初始化的
- 使用
nn.L1Loss()和torch.optim.SGD(params, lr)分别创建损失函数和优化器。- 将优化器的学习率设置为 0.01,要优化的参数应为您在第 2 部分中创建的模型参数。
- 编写一个训练循环,执行 300 个 epoch 的适当训练步骤。
- 训练循环应每 20 个 epoch 在测试数据集上测试模型。
- 使用训练好的模型对测试数据进行预测。
- 将这些预测与原始训练和测试数据进行可视化(注意: 如果您想使用非 CUDA 支持的库(如 matplotlib)进行绘图,可能需要确保预测不在 GPU 上)。
- 将您训练好的模型的
state_dict()保存到文件中。- 创建您在第 2 部分中制作的模型类的新实例,并加载刚刚保存的
state_dict()。 - 使用加载的模型对测试数据进行预测,并确认它们与第 4 部分中原始模型的预测匹配。
- 创建您在第 2 部分中制作的模型类的新实例,并加载刚刚保存的
额外学习¶
- 听听 The Unofficial PyTorch Optimization Loop Song(帮助记忆 PyTorch 训练/测试循环的步骤)。
- 阅读 Jeremy Howard 的 What is
torch.nn, really?,深入了解 PyTorch 中最重要的模块之一的工作原理。 - 花 10 分钟浏览并查看 PyTorch 文档速查表,了解您可能会遇到的各种 PyTorch 模块。
- 花 10 分钟阅读 PyTorch 网站上的加载和保存文档,熟悉 PyTorch 中不同的保存和加载选项。
- 花 1-2 小时阅读/观看以下内容,概述梯度下降和反向传播的内部工作原理,这是帮助我们的模型学习的主要算法。
- Wikipedia 上的梯度下降页面
- Robert Kwiatkowski 的 Gradient Descent Algorithm — a deep dive
- 3Blue1Brown 的 Gradient descent, how neural networks learn 视频
- 3Blue1Brown 的 What is backpropagation really doing? 视频
- Wikipedia 上的反向传播页面