00. PyTorch 基础¶
什么是 PyTorch?¶
PyTorch 是一个开源的机器学习和深度学习框架。
PyTorch 可以用来做什么?¶
PyTorch 允许你使用 Python 代码操作和处理数据,并编写机器学习算法。
谁在使用 PyTorch?¶
许多世界最大的科技公司,如 Meta (Facebook)、特斯拉和微软,以及人工智能研究公司如 OpenAI,都使用 PyTorch 来支持研究和将机器学习引入他们的产品。
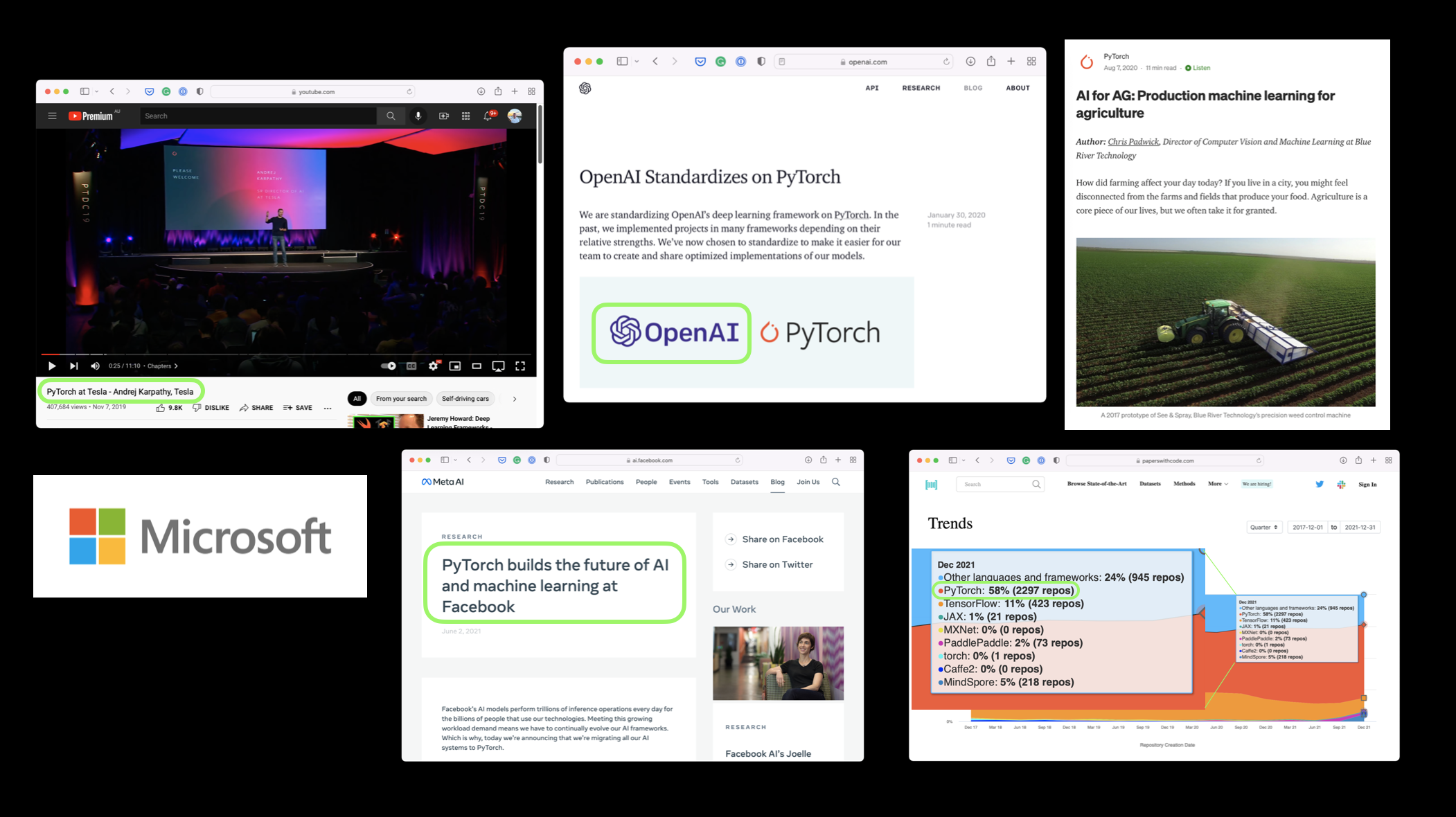
例如,Andrej Karpathy(特斯拉 AI 负责人)在多个演讲中(PyTorch DevCon 2019,Tesla AI Day 2021)讲述了特斯拉如何使用 PyTorch 来支持他们的自动驾驶计算机视觉模型。
PyTorch 还在其他行业中使用,如农业,用于为拖拉机提供计算机视觉。
为什么要使用 PyTorch?¶
机器学习研究人员非常喜欢使用 PyTorch。截至 2022 年 2 月,PyTorch 是 Papers With Code 上使用最多的深度学习框架,这是一个追踪机器学习研究论文及其相关代码库的网站。
PyTorch 还能在后台处理许多事情,如 GPU 加速(使你的代码运行更快)。
因此,你可以专注于操作数据和编写算法,而 PyTorch 会确保其运行速度。
如果像特斯拉和 Meta (Facebook) 这样的公司使用它来构建模型,并将其部署到数百个应用程序、数千辆汽车和数十亿用户的内容中,那么它在开发方面显然也是强大的。
本模块我们将涵盖的内容¶
本课程分为不同的部分(笔记本)。
每个笔记本涵盖了 PyTorch 中的重要概念和思想。
后续笔记本建立在前面笔记本的知识基础上(编号从 00、01、02 开始,一直延续到结束)。
本笔记本涉及机器学习和深度学习的基本构建块——张量。
具体来说,我们将涵盖:
| 主题 | 内容 |
|---|---|
| 张量介绍 | 张量是所有机器学习和深度学习的基本构建块。 |
| 创建张量 | 张量可以表示几乎任何类型的数据(图像、文字、数字表格)。 |
| 从张量获取信息 | 如果你能把信息放入张量,你也会想要取出它。 |
| 操作张量 | 机器学习算法(如神经网络)涉及以多种方式操作张量,如加法、乘法、组合。 |
| 处理张量形状 | 机器学习中最常见的问题之一是处理形状不匹配(尝试将错误形状的张量与其他张量混合)。 |
| 张量索引 | 如果你对 Python 列表或 NumPy 数组进行过索引,那么对张量进行索引非常相似,只是张量可以有更多的维度。 |
| 混合 PyTorch 张量和 NumPy | PyTorch 使用张量(torch.Tensor),NumPy 喜欢数组(np.ndarray),有时你会想要混合使用它们。 |
| 可重复性 | 机器学习非常实验性,因为它使用大量的随机性来工作,有时你会希望这种随机性不那么随机。 |
| 在 GPU 上运行张量 | GPU(图形处理单元)使你的代码运行更快,PyTorch 使在 GPU 上运行代码变得容易。 |
你可以在哪里获得帮助?¶
本课程的所有材料都可以在 GitHub 上找到。
如果你遇到问题,也可以在 Discussions 页面 上提问。
还有 PyTorch 开发者论坛,一个非常有用的 PyTorch 相关问题的交流平台。
导入 PyTorch¶
注意: 在运行本笔记本中的任何代码之前,您应该已经完成了 PyTorch 安装步骤。
然而,如果您在 Google Colab 上运行,一切应该都能正常工作(Google Colab 自带 PyTorch 和其他库的安装)。
让我们从导入 PyTorch 并检查我们正在使用的版本开始。
import torch
torch.__version__
'1.13.1+cu116'
太好了,看来我们已经安装了 PyTorch 1.10.0 或更高版本。
这意味着如果你正在学习这些资料,你会发现它们与 PyTorch 1.10.0 及以上版本的大部分内容是兼容的。不过,如果你的版本号远高于此,你可能会注意到一些不一致之处。
如果你遇到任何问题,请在课程的 GitHub 讨论页面 上发帖。
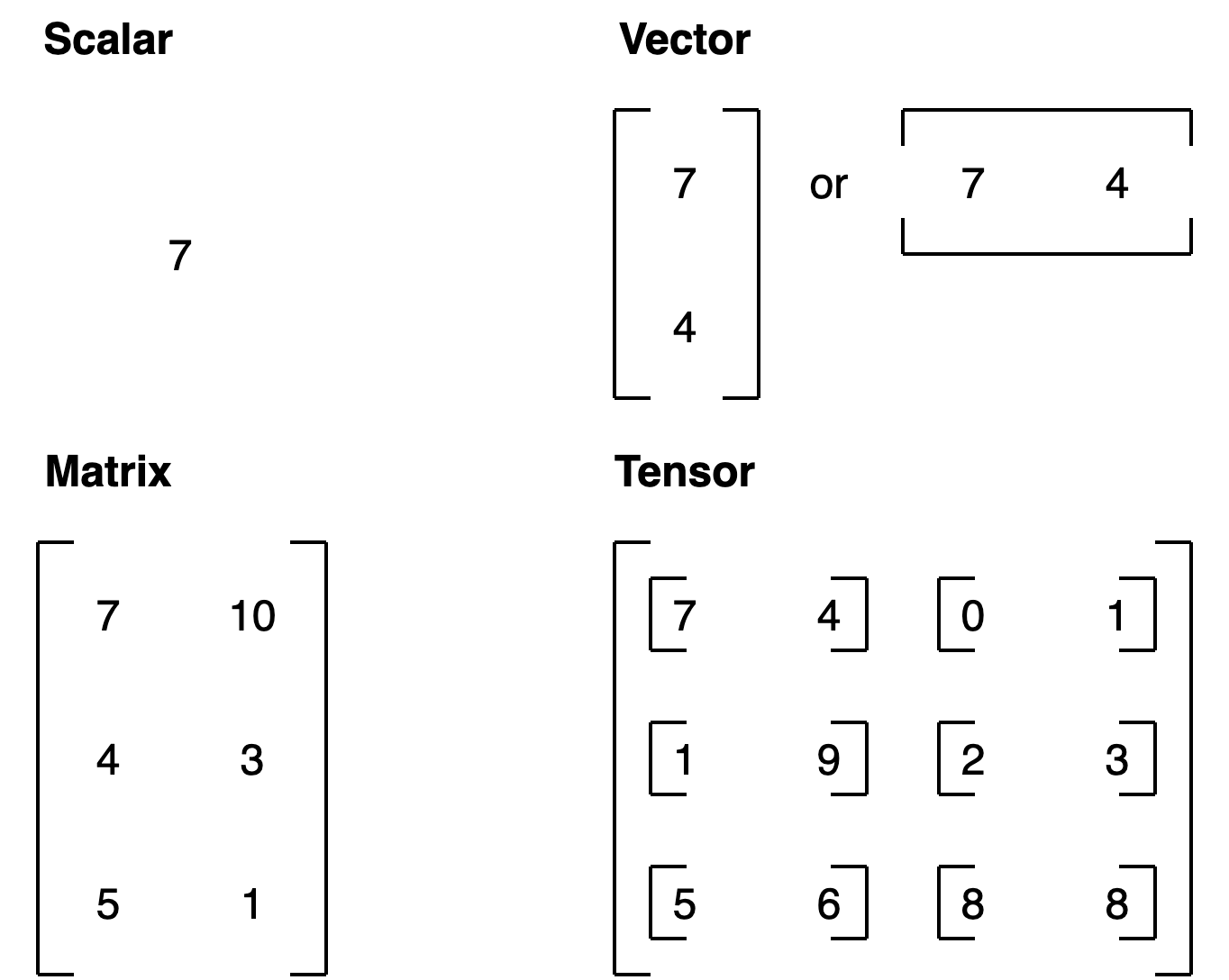
张量简介¶
现在我们已经导入了 PyTorch,是时候学习张量了。
张量是机器学习的基本构建块。
它们的作用是以数值方式表示数据。
例如,你可以将一张图像表示为一个形状为 [3, 224, 224] 的张量,这意味着 [颜色通道, 高度, 宽度],即图像有 3 个颜色通道(红、绿、蓝),高度为 224 像素,宽度为 224 像素。
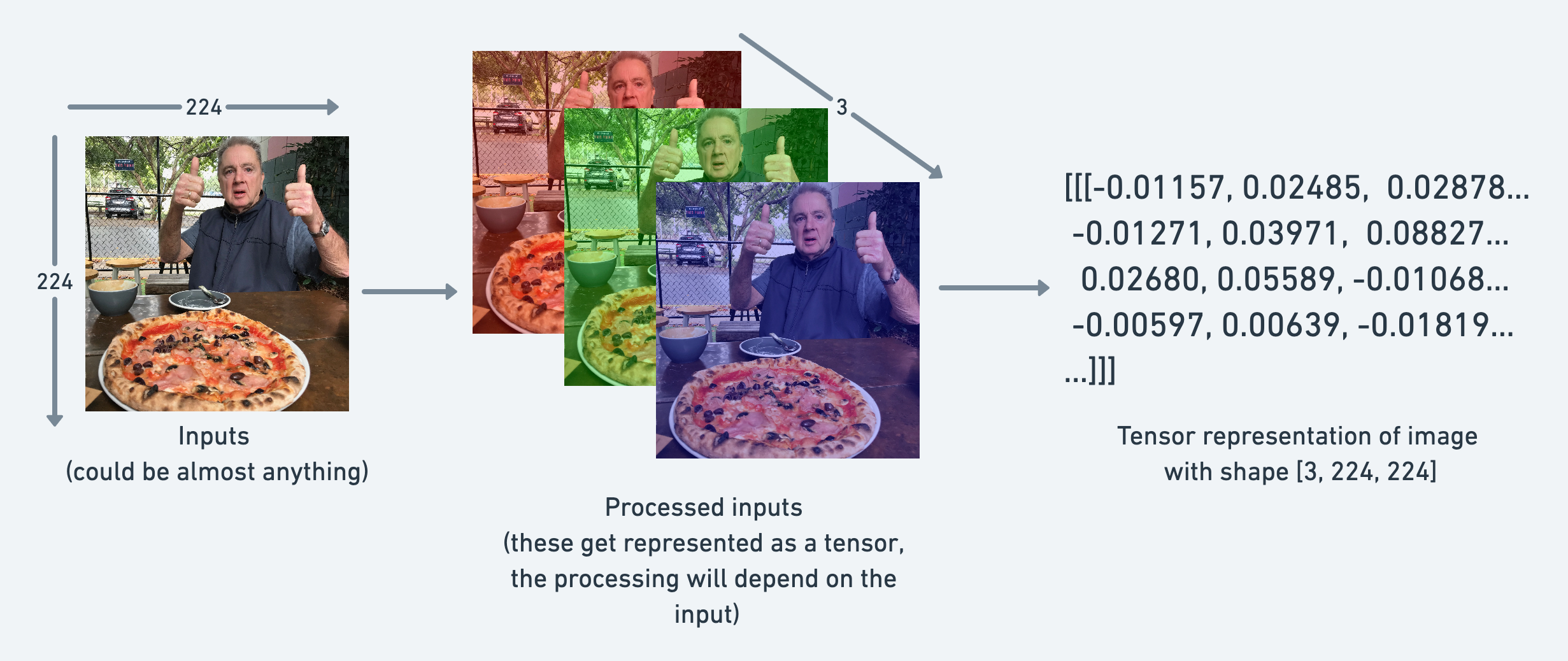
在张量术语(用于描述张量的语言)中,该张量具有三个维度,分别对应 颜色通道、高度 和 宽度。
但我们有点超前了。
让我们通过编码来进一步了解张量。
创建张量¶
PyTorch 热爱张量。以至于有一个完整的文档页面专门介绍 torch.Tensor 类。
你的第一项家庭作业是 阅读 torch.Tensor 的文档 10 分钟。但你可以稍后再做。
让我们开始编写代码。
我们要创建的第一个东西是 标量。
标量是一个单一的数字,在张量术语中,它是一个零维张量。
注意: 这是本课程的一个趋势。我们将专注于编写特定的代码。但通常我会设置一些练习,涉及阅读和熟悉 PyTorch 文档。毕竟,一旦你完成了这门课程,你无疑会想学习更多。而文档是你经常会去的地方。
# Scalar
scalar = torch.tensor(7)
scalar
tensor(7)
看看上面的输出结果是tensor(7)?
这意味着尽管scalar是一个单独的数值,但它的类型是torch.Tensor。
我们可以使用ndim属性来检查张量的维度。
scalar.ndim
0
如果我们想要从张量中提取数值呢?
也就是说,将 torch.Tensor 转换为 Python 整数。
为此,我们可以使用 item() 方法。
# Get the Python number within a tensor (only works with one-element tensors)
scalar.item()
7
好的,现在让我们来看一个向量。
向量是一个单维的张量,但它可以包含许多数字。
比如,你可以用向量 [3, 2] 来描述你家的 [卧室, 浴室]。或者你可以用 [3, 2, 2] 来描述你家的 [卧室, 浴室, 车位]。
这里重要的趋势是,向量在它能表示的内容上具有灵活性(张量也是如此)。
# Vector
vector = torch.tensor([7, 7])
vector
tensor([7, 7])
太好了,vector 现在包含了两个 7,这是我最喜欢的数字。
你觉得它会有多少维呢?
# Check the number of dimensions of vector
vector.ndim
1
嗯,这有点奇怪,vector 包含了两个数字,却只有一维。
我来告诉你一个小窍门。
你可以通过外侧方括号([)的数量来判断一个 PyTorch 张量有多少维,你只需要数一边的方括号即可。
vector 有多少个方括号呢?
另一个关于张量的重要概念是它们的 shape 属性。shape 告诉你这些元素是如何排列的。
让我们来看看 vector 的形状。
# Check shape of vector
vector.shape
torch.Size([2])
上述代码返回 torch.Size([2]),这意味着我们的向量形状为 [2]。这是因为我们在方括号内放置了两个元素([7, 7])。
现在让我们来看一个矩阵。
# Matrix
MATRIX = torch.tensor([[7, 8],
[9, 10]])
MATRIX
tensor([[ 7, 8],
[ 9, 10]])
哇!更多数字!矩阵和向量一样灵活,只不过它们多了一个维度。
# Check number of dimensions
MATRIX.ndim
2
MATRIX 有两个维度(你是否数过一侧外面的方括号数量?)。
你认为它会有什么样的 shape?
MATRIX.shape
torch.Size([2, 2])
我们得到输出 torch.Size([2, 2]),因为 MATRIX 有两层元素且每层有两行。
那我们如何创建一个张量呢?
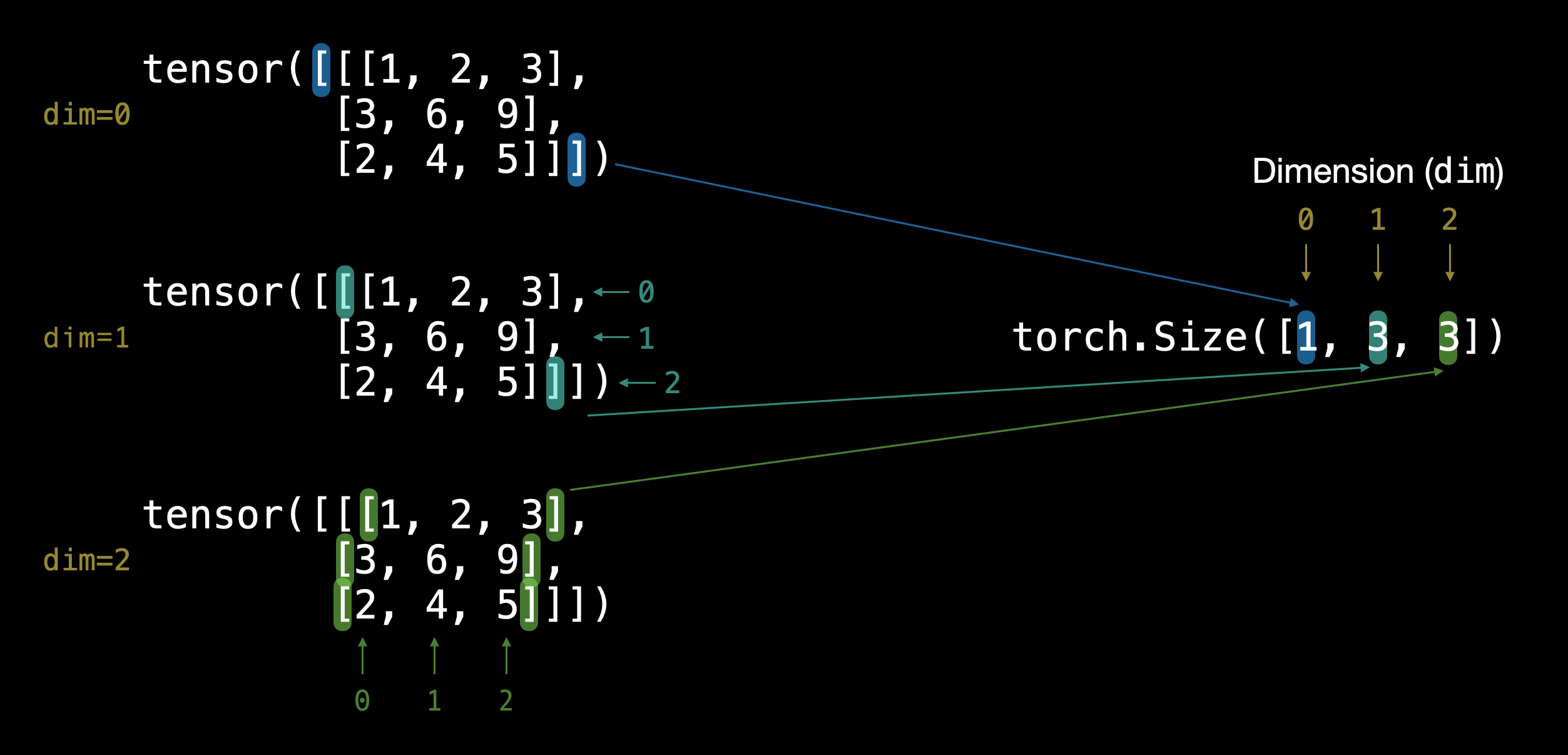
# Tensor
TENSOR = torch.tensor([[[1, 2, 3],
[3, 6, 9],
[2, 4, 5]]])
TENSOR
tensor([[[1, 2, 3],
[3, 6, 9],
[2, 4, 5]]])
哇!这个张量看起来真不错。
我要强调的是,张量几乎可以表示任何东西。
我们刚刚创建的这个张量,可以是牛排和杏仁黄油店的销售数据(这两样是我最喜欢的食物)。
你觉得它有多少个维度?(提示:使用方括号计数法)
# Check number of dimensions for TENSOR
TENSOR.ndim
3
至于它的形状呢?
# Check shape of TENSOR
TENSOR.shape
torch.Size([1, 3, 3])
好的,它输出了 torch.Size([1, 3, 3])。
维度是从外到内的。
这意味着有一个 3x3 的维度。
注意: 你可能注意到我用小写字母表示
scalar和vector,用大写字母表示MATRIX和TENSOR。这是有意为之的。在实践中,你通常会看到标量和向量用小写字母表示,如y或a。而矩阵和张量用大写字母表示,如X或W。你可能还会注意到矩阵和张量这两个词可以互换使用。这是常见的做法。因为在 PyTorch 中,你通常处理的是
torch.Tensor(因此得名张量),然而,其内部的形状和维度将决定它实际上是什么。
让我们总结一下。
| 名称 | 是什么? | 维度数量 | 通常/示例(小写或大写) |
|---|---|---|---|
| 标量 | 一个数字 | 0 | 小写 (a) |
| 向量 | 带有方向的数字(例如风速和方向),但也可以包含许多其他数字 | 1 | 小写 (y) |
| 矩阵 | 二维数字数组 | 2 | 大写 (Q) |
| 张量 | 多维数字数组 | 可以是任意数量,0 维张量是标量,1 维张量是向量 | 大写 (X) |
随机张量¶
我们已经确立了张量代表某种形式的数据。
而诸如神经网络之类的机器学习模型则会对张量进行操作并从中寻找模式。
但在使用 PyTorch 构建机器学习模型时,手动创建张量(就像我们一直在做的那样)的情况非常罕见。
相反,机器学习模型通常从包含大量随机数的大张量开始,并在处理数据的过程中调整这些随机数,使其更好地表示数据。
本质上:
从随机数开始 -> 观察数据 -> 更新随机数 -> 观察数据 -> 更新随机数...
作为数据科学家,你可以定义机器学习模型如何开始(初始化)、如何观察数据(表示)以及如何更新(优化)其随机数。
我们将在后续实践中亲自体验这些步骤。
现在,让我们看看如何创建一个包含随机数的张量。
我们可以使用 torch.rand() 并传入 size 参数来实现这一点。
# Create a random tensor of size (3, 4)
random_tensor = torch.rand(size=(3, 4))
random_tensor, random_tensor.dtype
(tensor([[0.6541, 0.4807, 0.2162, 0.6168],
[0.4428, 0.6608, 0.6194, 0.8620],
[0.2795, 0.6055, 0.4958, 0.5483]]),
torch.float32)
torch.rand() 的灵活性在于我们可以将 size 调整为任何我们想要的形状。
例如,假设你想要一个常见的图像形状的随机张量 [224, 224, 3](即 [高度, 宽度, 颜色通道])。
# Create a random tensor of size (224, 224, 3)
random_image_size_tensor = torch.rand(size=(224, 224, 3))
random_image_size_tensor.shape, random_image_size_tensor.ndim
(torch.Size([224, 224, 3]), 3)
零和一¶
有时,你只想用零或一填充张量。
这在掩码操作中很常见(例如,用零掩码张量中的某些值,让模型知道不要学习这些值)。
让我们使用 torch.zeros() 创建一个充满零的张量。
同样,size 参数在这里起作用。
# Create a tensor of all zeros
zeros = torch.zeros(size=(3, 4))
zeros, zeros.dtype
(tensor([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]]),
torch.float32)
我们可以采用类似的方法,使用torch.ones()来创建一个全为1的张量。
# Create a tensor of all ones
ones = torch.ones(size=(3, 4))
ones, ones.dtype
(tensor([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]]),
torch.float32)
创建一个范围和类似张量¶
有时候你可能需要一个数字范围,例如从1到10或从0到100。
你可以使用 torch.arange(start, end, step) 来实现这一点。
其中:
start= 范围的起始值(例如 0)end= 范围的结束值(例如 10)step= 每两个值之间的步长(例如 1)
注意: 在 Python 中,你可以使用
range()来创建一个范围。然而在 PyTorch 中,torch.range()已被弃用,未来可能会显示错误。
# Use torch.arange(), torch.range() is deprecated
zero_to_ten_deprecated = torch.range(0, 10) # Note: this may return an error in the future
# Create a range of values 0 to 10
zero_to_ten = torch.arange(start=0, end=10, step=1)
zero_to_ten
/tmp/ipykernel_3695928/193451495.py:2: UserWarning: torch.range is deprecated and will be removed in a future release because its behavior is inconsistent with Python's range builtin. Instead, use torch.arange, which produces values in [start, end). zero_to_ten_deprecated = torch.range(0, 10) # Note: this may return an error in the future
tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
有时你可能需要一个特定类型的张量,其形状与另一个张量相同。
例如,一个与先前张量形状相同的、所有元素均为零的张量。
为此,你可以使用 torch.zeros_like(input) 或 torch.ones_like(input),这两个函数分别返回一个形状与 input 相同、元素全为零或全为1的张量。
# Can also create a tensor of zeros similar to another tensor
ten_zeros = torch.zeros_like(input=zero_to_ten) # will have same shape
ten_zeros
tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
张量数据类型¶
在 PyTorch 中,有许多不同的 张量数据类型。
有些专用于 CPU,有些则更适合 GPU。
了解它们之间的区别需要一些时间。
通常,如果你看到 torch.cuda 字样,那么这个张量是用于 GPU 的(因为 Nvidia GPU 使用名为 CUDA 的计算工具包)。
最常见的类型(通常也是默认类型)是 torch.float32 或 torch.float。
这被称为“32 位浮点数”。
但也有 16 位浮点数(torch.float16 或 torch.half)和 64 位浮点数(torch.float64 或 torch.double)。
更复杂的是,还有 8 位、16 位、32 位和 64 位整数。
还有更多!
注意: 整数是像
7这样的平滑圆整数,而浮点数有小数点,如7.0。
所有这些数据类型的存在都与 计算精度 有关。
精度是指描述一个数字时使用的细节量。
精度值越高(8、16、32),表示一个数字所需的细节和数据就越多。
这在深度学习和数值计算中很重要,因为你需要进行如此多的运算,计算所需的细节越多,使用的计算资源就越多。
因此,较低精度的数据类型通常计算速度更快,但在评估指标(如准确性)上会牺牲一些性能(计算速度快但精度较低)。
资源:
让我们看看如何创建具有特定数据类型的张量。我们可以使用 dtype 参数来实现这一点。
# Default datatype for tensors is float32
float_32_tensor = torch.tensor([3.0, 6.0, 9.0],
dtype=None, # defaults to None, which is torch.float32 or whatever datatype is passed
device=None, # defaults to None, which uses the default tensor type
requires_grad=False) # if True, operations performed on the tensor are recorded
float_32_tensor.shape, float_32_tensor.dtype, float_32_tensor.device
(torch.Size([3]), torch.float32, device(type='cpu'))
除了形状问题(张量形状不匹配),在PyTorch中你还会经常遇到另外两种常见问题:数据类型和设备问题。
例如,一个张量是 torch.float32 而另一个是 torch.float16(PyTorch通常希望张量具有相同的格式)。
或者一个张量在CPU上,而另一个在GPU上(PyTorch希望张量之间的计算在同一设备上进行)。
我们稍后会更多地讨论设备问题。
现在,让我们创建一个 dtype=torch.float16 的张量。
float_16_tensor = torch.tensor([3.0, 6.0, 9.0],
dtype=torch.float16) # torch.half would also work
float_16_tensor.dtype
torch.float16
获取张量的信息¶
一旦你创建了张量(或者由他人或 PyTorch 模块为你创建),你可能希望从中获取一些信息。
我们之前已经见过这些属性,但最常见的三个张量属性是:
shape- 张量的形状是什么?(某些操作需要特定的形状规则)dtype- 张量中的元素存储为什么数据类型?device- 张量存储在哪个设备上?(通常是 GPU 或 CPU)
让我们创建一个随机张量,并找出它的详细信息。
# Create a tensor
some_tensor = torch.rand(3, 4)
# Find out details about it
print(some_tensor)
print(f"Shape of tensor: {some_tensor.shape}")
print(f"Datatype of tensor: {some_tensor.dtype}")
print(f"Device tensor is stored on: {some_tensor.device}") # will default to CPU
tensor([[0.4688, 0.0055, 0.8551, 0.0646],
[0.6538, 0.5157, 0.4071, 0.2109],
[0.9960, 0.3061, 0.9369, 0.7008]])
Shape of tensor: torch.Size([3, 4])
Datatype of tensor: torch.float32
Device tensor is stored on: cpu
注意: 在 PyTorch 中遇到问题时,很可能是与上述三个属性之一有关。因此,当错误信息出现时,给自己唱一首小歌,叫做“什么,什么,哪里”:
- “我的张量是什么形状?它们的类型是什么,存储在哪里?什么形状,什么类型,哪里哪里哪里”
操作张量(张量运算)¶
在深度学习中,数据(图像、文本、视频、音频、蛋白质结构等)被表示为张量。
模型通过研究这些张量并对其执行一系列操作(可能是数百万次)来学习,从而创建输入数据中模式的表示。
这些操作通常是以下几种基本运算的精彩组合:
- 加法
- 减法
- 乘法(逐元素)
- 除法
- 矩阵乘法
仅此而已。当然,还有一些其他的操作,但这些是神经网络的基本构建块。
通过以正确的方式堆叠这些构建块,你可以创建最复杂的神经网络(就像乐高积木一样!)。
# Create a tensor of values and add a number to it
tensor = torch.tensor([1, 2, 3])
tensor + 10
tensor([11, 12, 13])
# Multiply it by 10
tensor * 10
tensor([10, 20, 30])
注意上面张量的值并没有变成 tensor([110, 120, 130]),这是因为张量内部的值不会改变,除非它们被重新赋值。
# Tensors don't change unless reassigned
tensor
tensor([1, 2, 3])
我们来减去一个数,这次我们将重新赋值给 tensor 变量。
# Subtract and reassign
tensor = tensor - 10
tensor
tensor([-9, -8, -7])
# Add and reassign
tensor = tensor + 10
tensor
tensor([1, 2, 3])
PyTorch 也内置了许多函数,如 torch.mul()(乘法简写)和 torch.add(),用于执行基本运算。
# Can also use torch functions
torch.multiply(tensor, 10)
tensor([10, 20, 30])
# Original tensor is still unchanged
tensor
tensor([1, 2, 3])
然而,更常见的是使用运算符符号,如 * 而不是 torch.mul()。
# Element-wise multiplication (each element multiplies its equivalent, index 0->0, 1->1, 2->2)
print(tensor, "*", tensor)
print("Equals:", tensor * tensor)
tensor([1, 2, 3]) * tensor([1, 2, 3]) Equals: tensor([1, 4, 9])
矩阵乘法(一切尽在矩阵乘法中)¶
在机器学习和深度学习算法(如神经网络)中,最常见的操作之一就是矩阵乘法。
PyTorch 在 torch.matmul() 方法中实现了矩阵乘法功能。
矩阵乘法需要记住的两个主要规则是:
- 内维度必须匹配:
(3, 2) @ (3, 2)无法进行(2, 3) @ (3, 2)可以进行(3, 2) @ (2, 3)可以进行
- 结果矩阵的形状是外维度:
(2, 3) @ (3, 2)->(2, 2)(3, 2) @ (2, 3)->(3, 3)
注意: 在 Python 中,"
@" 符号表示矩阵乘法。
资源: 你可以在 PyTorch 文档中查看所有关于
torch.matmul()的矩阵乘法规则。
让我们创建一个张量,并对其实现逐元素乘法和矩阵乘法。
import torch
tensor = torch.tensor([1, 2, 3])
tensor.shape
torch.Size([3])
元素间乘法与矩阵乘法的区别在于值的相加。
对于值为 [1, 2, 3] 的 tensor 变量:
| 操作 | 计算 | 代码 |
|---|---|---|
| 元素间乘法 | [1*1, 2*2, 3*3] = [1, 4, 9] |
tensor * tensor |
| 矩阵乘法 | [1*1 + 2*2 + 3*3] = [14] |
tensor.matmul(tensor) |
# Element-wise matrix multiplication
tensor * tensor
tensor([1, 4, 9])
# Matrix multiplication
torch.matmul(tensor, tensor)
tensor(14)
# Can also use the "@" symbol for matrix multiplication, though not recommended
tensor @ tensor
tensor(14)
你可以手动进行矩阵乘法,但并不推荐这样做。
内置的 torch.matmul() 方法速度更快。
%%time
# Matrix multiplication by hand
# (avoid doing operations with for loops at all cost, they are computationally expensive)
value = 0
for i in range(len(tensor)):
value += tensor[i] * tensor[i]
value
CPU times: user 773 µs, sys: 0 ns, total: 773 µs Wall time: 499 µs
tensor(14)
%%time
torch.matmul(tensor, tensor)
CPU times: user 146 µs, sys: 83 µs, total: 229 µs Wall time: 171 µs
tensor(14)
深度学习中最常见的错误之一(形状错误)¶
由于深度学习很大一部分涉及矩阵的乘法和运算,而矩阵对于形状和大小的组合有严格的规则,因此你在深度学习中会遇到的最常见错误之一就是形状不匹配。
# Shapes need to be in the right way
tensor_A = torch.tensor([[1, 2],
[3, 4],
[5, 6]], dtype=torch.float32)
tensor_B = torch.tensor([[7, 10],
[8, 11],
[9, 12]], dtype=torch.float32)
torch.matmul(tensor_A, tensor_B) # (this will error)
--------------------------------------------------------------------------- RuntimeError Traceback (most recent call last) /home/daniel/code/pytorch/pytorch-course/pytorch-deep-learning/00_pytorch_fundamentals.ipynb Cell 75 in <cell line: 10>() <a href='vscode-notebook-cell://ssh-remote%2B7b22686f73744e616d65223a22544954414e2d525458227d/home/daniel/code/pytorch/pytorch-course/pytorch-deep-learning/00_pytorch_fundamentals.ipynb#Y134sdnNjb2RlLXJlbW90ZQ%3D%3D?line=1'>2</a> tensor_A = torch.tensor([[1, 2], <a href='vscode-notebook-cell://ssh-remote%2B7b22686f73744e616d65223a22544954414e2d525458227d/home/daniel/code/pytorch/pytorch-course/pytorch-deep-learning/00_pytorch_fundamentals.ipynb#Y134sdnNjb2RlLXJlbW90ZQ%3D%3D?line=2'>3</a> [3, 4], <a href='vscode-notebook-cell://ssh-remote%2B7b22686f73744e616d65223a22544954414e2d525458227d/home/daniel/code/pytorch/pytorch-course/pytorch-deep-learning/00_pytorch_fundamentals.ipynb#Y134sdnNjb2RlLXJlbW90ZQ%3D%3D?line=3'>4</a> [5, 6]], dtype=torch.float32) <a href='vscode-notebook-cell://ssh-remote%2B7b22686f73744e616d65223a22544954414e2d525458227d/home/daniel/code/pytorch/pytorch-course/pytorch-deep-learning/00_pytorch_fundamentals.ipynb#Y134sdnNjb2RlLXJlbW90ZQ%3D%3D?line=5'>6</a> tensor_B = torch.tensor([[7, 10], <a href='vscode-notebook-cell://ssh-remote%2B7b22686f73744e616d65223a22544954414e2d525458227d/home/daniel/code/pytorch/pytorch-course/pytorch-deep-learning/00_pytorch_fundamentals.ipynb#Y134sdnNjb2RlLXJlbW90ZQ%3D%3D?line=6'>7</a> [8, 11], <a href='vscode-notebook-cell://ssh-remote%2B7b22686f73744e616d65223a22544954414e2d525458227d/home/daniel/code/pytorch/pytorch-course/pytorch-deep-learning/00_pytorch_fundamentals.ipynb#Y134sdnNjb2RlLXJlbW90ZQ%3D%3D?line=7'>8</a> [9, 12]], dtype=torch.float32) ---> <a href='vscode-notebook-cell://ssh-remote%2B7b22686f73744e616d65223a22544954414e2d525458227d/home/daniel/code/pytorch/pytorch-course/pytorch-deep-learning/00_pytorch_fundamentals.ipynb#Y134sdnNjb2RlLXJlbW90ZQ%3D%3D?line=9'>10</a> torch.matmul(tensor_A, tensor_B) RuntimeError: mat1 and mat2 shapes cannot be multiplied (3x2 and 3x2)
我们可以通过使 tensor_A 和 tensor_B 的内维匹配来实现它们之间的矩阵乘法。
实现这一点的方法之一是使用转置(交换给定张量的维度)。
在 PyTorch 中,你可以使用以下任一方法进行转置:
torch.transpose(input, dim0, dim1)- 其中input是需要转置的张量,dim0和dim1是要交换的维度。tensor.T- 其中tensor是需要转置的张量。
我们尝试后者。
# View tensor_A and tensor_B
print(tensor_A)
print(tensor_B)
tensor([[1., 2.],
[3., 4.],
[5., 6.]])
tensor([[ 7., 10.],
[ 8., 11.],
[ 9., 12.]])
# View tensor_A and tensor_B.T
print(tensor_A)
print(tensor_B.T)
tensor([[1., 2.],
[3., 4.],
[5., 6.]])
tensor([[ 7., 8., 9.],
[10., 11., 12.]])
# The operation works when tensor_B is transposed
print(f"Original shapes: tensor_A = {tensor_A.shape}, tensor_B = {tensor_B.shape}\n")
print(f"New shapes: tensor_A = {tensor_A.shape} (same as above), tensor_B.T = {tensor_B.T.shape}\n")
print(f"Multiplying: {tensor_A.shape} * {tensor_B.T.shape} <- inner dimensions match\n")
print("Output:\n")
output = torch.matmul(tensor_A, tensor_B.T)
print(output)
print(f"\nOutput shape: {output.shape}")
Original shapes: tensor_A = torch.Size([3, 2]), tensor_B = torch.Size([3, 2])
New shapes: tensor_A = torch.Size([3, 2]) (same as above), tensor_B.T = torch.Size([2, 3])
Multiplying: torch.Size([3, 2]) * torch.Size([2, 3]) <- inner dimensions match
Output:
tensor([[ 27., 30., 33.],
[ 61., 68., 75.],
[ 95., 106., 117.]])
Output shape: torch.Size([3, 3])
你也可以使用 torch.mm(),它是 torch.matmul() 的简写形式。
# torch.mm is a shortcut for matmul
torch.mm(tensor_A, tensor_B.T)
tensor([[ 27., 30., 33.],
[ 61., 68., 75.],
[ 95., 106., 117.]])

神经网络中充满了矩阵乘法和点积运算。
torch.nn.Linear() 模块(我们稍后会看到它的实际应用),也称为前馈层或全连接层,实现了输入 x 与权重矩阵 A 之间的矩阵乘法。
$$ y = x \cdot A^T + b $$
其中:
x是层的输入(深度学习是由多个层(如torch.nn.Linear()和其他层)堆叠而成的)。A是由层创建的权重矩阵,初始时为随机数,随着神经网络学习更好地表示数据中的模式而调整(注意“T”,这是因为权重矩阵被转置了)。- 注意: 你可能经常看到用
W或其他字母如X来表示权重矩阵。
- 注意: 你可能经常看到用
b是用于稍微偏移权重和输入的偏置项。y是输出(通过对输入进行操作以期发现其中的模式)。
这是一个线性函数(你可能在高中或其他地方见过类似 $y = mx + b$ 的形式),可以用来绘制一条直线!
让我们来玩一玩线性层。
尝试更改下面 in_features 和 out_features 的值,看看会发生什么。
你注意到形状方面有什么变化吗?
# Since the linear layer starts with a random weights matrix, let's make it reproducible (more on this later)
torch.manual_seed(42)
# This uses matrix multiplication
linear = torch.nn.Linear(in_features=2, # in_features = matches inner dimension of input
out_features=6) # out_features = describes outer value
x = tensor_A
output = linear(x)
print(f"Input shape: {x.shape}\n")
print(f"Output:\n{output}\n\nOutput shape: {output.shape}")
Input shape: torch.Size([3, 2])
Output:
tensor([[2.2368, 1.2292, 0.4714, 0.3864, 0.1309, 0.9838],
[4.4919, 2.1970, 0.4469, 0.5285, 0.3401, 2.4777],
[6.7469, 3.1648, 0.4224, 0.6705, 0.5493, 3.9716]],
grad_fn=<AddmmBackward0>)
Output shape: torch.Size([3, 6])
问题: 如果在上述代码中将
in_features从 2 改为 3,会发生什么情况?是否会出现错误?如何更改输入 (x) 的形状以适应这种错误?提示:我们在上面的tensor_B上做了什么?
如果在上述代码中将 in_features 从 2 改为 3,通常会导致错误,因为输入张量 x 的形状与新的 in_features 不匹配。具体来说,如果 x 的形状是 (batch_size, 2),而 in_features 改为 3,那么 x 的列数(即特征数)与 in_features 不一致,从而引发错误。
为了解决这个问题,你需要调整输入张量 x 的形状,使其与新的 in_features 匹配。具体来说,你需要将 x 的形状从 (batch_size, 2) 改为 (batch_size, 3)。这可以通过对 x 进行适当的变换来实现,类似于我们在上面的 tensor_B 上所做的操作。
例如,如果你有一个形状为 (batch_size, 2) 的输入张量 x,你可以通过添加一个额外的列来将其形状改为 (batch_size, 3)。这可以通过以下方式实现:
import torch
# 假设 x 是一个形状为 (batch_size, 2) 的张量
x = torch.randn(3, 2) # 示例输入
# 添加一个额外的列,使其形状变为 (batch_size, 3)
x_expanded = torch.cat((x, torch.zeros(3, 1)), dim=1)
# 现在 x_expanded 的形状为 (3, 3),可以与 in_features=3 的线性层匹配
通过这种方式,你可以调整输入张量的形状以适应新的 in_features 值,从而避免错误。
如果你以前从未接触过矩阵乘法,一开始可能会觉得这个话题有些令人困惑。
但当你多次尝试并深入研究一些神经网络后,你会发现它无处不在。
记住,矩阵乘法就是你所需要的一切。
当你开始深入研究神经网络层并构建自己的模型时,你会发现矩阵乘法无处不在。来源: https://marksaroufim.substack.com/p/working-class-deep-learner
查找最小值、最大值、均值、总和等(聚合操作)¶
我们已经了解了几种操作张量的方法,接下来让我们探讨几种聚合张量的方式(从多个值变为较少值)。
首先,我们将创建一个张量,然后找出它的最大值、最小值、均值和总和。
# Create a tensor
x = torch.arange(0, 100, 10)
x
tensor([ 0, 10, 20, 30, 40, 50, 60, 70, 80, 90])
现在让我们进行一些聚合操作。
print(f"Minimum: {x.min()}")
print(f"Maximum: {x.max()}")
# print(f"Mean: {x.mean()}") # this will error
print(f"Mean: {x.type(torch.float32).mean()}") # won't work without float datatype
print(f"Sum: {x.sum()}")
Minimum: 0 Maximum: 90 Mean: 45.0 Sum: 450
注意: 你可能会发现一些方法,如
torch.mean(),需要张量处于torch.float32(最常见)或其他特定数据类型,否则操作将失败。
你也可以使用 torch 方法来实现上述操作。
torch.max(x), torch.min(x), torch.mean(x.type(torch.float32)), torch.sum(x)
(tensor(90), tensor(0), tensor(45.), tensor(450))
位置最小值/最大值¶
你还可以分别使用 torch.argmax() 和 torch.argmin() 找到张量中最大值或最小值出现的位置索引。
这在只需要知道最高(或最低)值所在位置而不需要实际值本身时非常有用(我们将在后面的部分看到这一点,例如在使用 softmax 激活函数时)。
# Create a tensor
tensor = torch.arange(10, 100, 10)
print(f"Tensor: {tensor}")
# Returns index of max and min values
print(f"Index where max value occurs: {tensor.argmax()}")
print(f"Index where min value occurs: {tensor.argmin()}")
Tensor: tensor([10, 20, 30, 40, 50, 60, 70, 80, 90]) Index where max value occurs: 8 Index where min value occurs: 0
改变张量数据类型¶
如前所述,深度学习操作中常见的问题之一是张量具有不同的数据类型。
如果一个张量是 torch.float64 类型,而另一个是 torch.float32 类型,你可能会遇到一些错误。
但有一个解决方法。
你可以使用 torch.Tensor.type(dtype=None) 方法来改变张量的数据类型,其中 dtype 参数是你希望使用的数据类型。
首先,我们将创建一个张量并检查其数据类型(默认是 torch.float32)。
# Create a tensor and check its datatype
tensor = torch.arange(10., 100., 10.)
tensor.dtype
torch.float32
现在,我们将创建另一个张量,与之前一样,但将其数据类型更改为 torch.float16。
# Create a float16 tensor
tensor_float16 = tensor.type(torch.float16)
tensor_float16
tensor([10., 20., 30., 40., 50., 60., 70., 80., 90.], dtype=torch.float16)
我们可以采用类似的方法来创建一个 torch.int8 张量。
# Create a int8 tensor
tensor_int8 = tensor.type(torch.int8)
tensor_int8
tensor([10, 20, 30, 40, 50, 60, 70, 80, 90], dtype=torch.int8)
注意: 不同的数据类型一开始可能会让人感到困惑。但可以这样想,数字越小(例如 32、16、8),计算机存储的值就越不精确。而存储量越少,通常会导致计算速度更快,模型整体更小。基于移动设备的神经网络通常使用 8 位整数进行运算,这些网络更小、运行更快,但精确度不如使用 float32 的网络。更多关于这方面的内容,建议阅读关于计算精度)的资料。
练习: 到目前为止,我们已经介绍了不少张量方法,但在
torch.Tensor文档中还有更多内容。我建议花 10 分钟时间浏览一下,看看有没有什么吸引你的方法。点击它们,然后自己动手写代码看看会发生什么。
重塑、堆叠、压缩和解压缩¶
很多时候,你会希望在不改变张量内部值的情况下,重塑或改变张量的维度。
为此,一些常用的方法包括:
| 方法 | 一行描述 |
|---|---|
torch.reshape(input, shape) |
将 input 重塑为 shape(如果兼容),也可以使用 torch.Tensor.reshape()。 |
Tensor.view(shape) |
返回一个不同 shape 的原始张量视图,但与原始张量共享相同的数据。 |
torch.stack(tensors, dim=0) |
沿新维度 (dim) 连接一系列 tensors,所有 tensors 必须具有相同的大小。 |
torch.squeeze(input) |
压缩 input 以移除所有值为 1 的维度。 |
torch.unsqueeze(input, dim) |
在 dim 处添加一个值为 1 的维度返回 input。 |
torch.permute(input, dims) |
返回原始 input 的一个视图,其维度按 dims 重新排列。 |
为什么要使用这些方法?
因为深度学习模型(神经网络)都是以某种方式操纵张量的。由于矩阵乘法的规则,如果形状不匹配,你会遇到错误。这些方法帮助你确保你的张量的正确元素与其他张量的正确元素混合。
让我们尝试一下这些方法。
首先,我们将创建一个张量。
# Create a tensor
import torch
x = torch.arange(1., 8.)
x, x.shape
(tensor([1., 2., 3., 4., 5., 6., 7.]), torch.Size([7]))
现在让我们通过 torch.reshape() 增加一个额外的维度。
# Add an extra dimension
x_reshaped = x.reshape(1, 7)
x_reshaped, x_reshaped.shape
(tensor([[1., 2., 3., 4., 5., 6., 7.]]), torch.Size([1, 7]))
我们还可以使用 torch.view() 来改变视图。
# Change view (keeps same data as original but changes view)
# See more: https://stackoverflow.com/a/54507446/7900723
z = x.view(1, 7)
z, z.shape
(tensor([[1., 2., 3., 4., 5., 6., 7.]]), torch.Size([1, 7]))
请记住,使用 torch.view() 改变张量的视图实际上只是创建了同一张量的一个新的视图。
因此,改变视图也会改变原始张量。
# Changing z changes x
z[:, 0] = 5
z, x
(tensor([[5., 2., 3., 4., 5., 6., 7.]]), tensor([5., 2., 3., 4., 5., 6., 7.]))
如果我们想将新创建的张量在自身上堆叠五次,可以使用 torch.stack() 来实现。
# Stack tensors on top of each other
x_stacked = torch.stack([x, x, x, x], dim=0) # try changing dim to dim=1 and see what happens
x_stacked
tensor([[5., 2., 3., 4., 5., 6., 7.],
[5., 2., 3., 4., 5., 6., 7.],
[5., 2., 3., 4., 5., 6., 7.],
[5., 2., 3., 4., 5., 6., 7.]])
如何从张量中移除所有单一维度?
你可以使用 torch.squeeze() 来实现这一点(我记得这就像是“挤压”张量,使其只保留大于1的维度)。
print(f"Previous tensor: {x_reshaped}")
print(f"Previous shape: {x_reshaped.shape}")
# Remove extra dimension from x_reshaped
x_squeezed = x_reshaped.squeeze()
print(f"\nNew tensor: {x_squeezed}")
print(f"New shape: {x_squeezed.shape}")
Previous tensor: tensor([[5., 2., 3., 4., 5., 6., 7.]]) Previous shape: torch.Size([1, 7]) New tensor: tensor([5., 2., 3., 4., 5., 6., 7.]) New shape: torch.Size([7])
要实现与 torch.squeeze() 相反的操作,可以使用 torch.unsqueeze() 在特定索引处添加一个维度值为 1 的维度。
print(f"Previous tensor: {x_squeezed}")
print(f"Previous shape: {x_squeezed.shape}")
## Add an extra dimension with unsqueeze
x_unsqueezed = x_squeezed.unsqueeze(dim=0)
print(f"\nNew tensor: {x_unsqueezed}")
print(f"New shape: {x_unsqueezed.shape}")
Previous tensor: tensor([5., 2., 3., 4., 5., 6., 7.]) Previous shape: torch.Size([7]) New tensor: tensor([[5., 2., 3., 4., 5., 6., 7.]]) New shape: torch.Size([1, 7])
你还可以使用 torch.permute(input, dims) 来重新排列轴的顺序,其中 input 会被转换成一个具有新 dims 的视图。
# Create tensor with specific shape
x_original = torch.rand(size=(224, 224, 3))
# Permute the original tensor to rearrange the axis order
x_permuted = x_original.permute(2, 0, 1) # shifts axis 0->1, 1->2, 2->0
print(f"Previous shape: {x_original.shape}")
print(f"New shape: {x_permuted.shape}")
Previous shape: torch.Size([224, 224, 3]) New shape: torch.Size([3, 224, 224])
注意:由于置换返回的是一个视图(与原始数据共享相同的数据),因此置换后的张量中的值将与原始张量中的值相同,如果你更改了视图中的值,它也会改变原始张量中的值。
索引(从张量中选择数据)¶
有时,您可能希望从张量中选择特定数据(例如,仅选择第一列或第二行)。
为此,您可以使用索引。
如果您曾经在 Python 列表或 NumPy 数组上进行过索引操作,那么在 PyTorch 中对张量进行索引操作与此非常相似。
# Create a tensor
import torch
x = torch.arange(1, 10).reshape(1, 3, 3)
x, x.shape
(tensor([[[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]]),
torch.Size([1, 3, 3]))
索引值的顺序是从外维度到内维度(请参考方括号的使用)。
# Let's index bracket by bracket
print(f"First square bracket:\n{x[0]}")
print(f"Second square bracket: {x[0][0]}")
print(f"Third square bracket: {x[0][0][0]}")
First square bracket:
tensor([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
Second square bracket: tensor([1, 2, 3])
Third square bracket: 1
你也可以使用 : 来指定“该维度中的所有值”,然后使用逗号(,)来添加另一个维度。
# Get all values of 0th dimension and the 0 index of 1st dimension
x[:, 0]
tensor([[1, 2, 3]])
# Get all values of 0th & 1st dimensions but only index 1 of 2nd dimension
x[:, :, 1]
tensor([[2, 5, 8]])
# Get all values of the 0 dimension but only the 1 index value of the 1st and 2nd dimension
x[:, 1, 1]
tensor([5])
# Get index 0 of 0th and 1st dimension and all values of 2nd dimension
x[0, 0, :] # same as x[0][0]
tensor([1, 2, 3])
索引一开始可能会让人感到相当困惑,特别是对于较大的张量(我仍然需要尝试多次索引才能正确操作)。但只要稍加练习,并遵循数据探索者的座右铭(可视化,可视化,再可视化),你就会开始掌握其中的窍门。
PyTorch 张量与 NumPy¶
由于 NumPy 是 Python 中流行的数值计算库,PyTorch 提供了与 NumPy 良好交互的功能。
从 NumPy 到 PyTorch(以及反过来)的两个主要方法如下:
torch.from_numpy(ndarray)- NumPy 数组 -> PyTorch 张量。torch.Tensor.numpy()- PyTorch 张量 -> NumPy 数组。
让我们尝试一下这些方法。
# NumPy array to tensor
import torch
import numpy as np
array = np.arange(1.0, 8.0)
tensor = torch.from_numpy(array)
array, tensor
(array([1., 2., 3., 4., 5., 6., 7.]), tensor([1., 2., 3., 4., 5., 6., 7.], dtype=torch.float64))
注意: 默认情况下,NumPy 数组会以
float64数据类型创建,如果你将其转换为 PyTorch 张量,它会保持相同的数据类型(如上所述)。然而,许多 PyTorch 计算默认使用
float32。因此,如果你想将你的 NumPy 数组(float64)转换为 PyTorch 张量(float64),然后再转换为 PyTorch 张量(float32),可以使用
tensor = torch.from_numpy(array).type(torch.float32)。
由于我们在上面重新赋值了 tensor,如果你改变张量,数组将保持不变。
# Change the array, keep the tensor
array = array + 1
array, tensor
(array([2., 3., 4., 5., 6., 7., 8.]), tensor([1., 2., 3., 4., 5., 6., 7.], dtype=torch.float64))
如果你想从 PyTorch 张量转换为 NumPy 数组,可以调用 tensor.numpy()。
# Tensor to NumPy array
tensor = torch.ones(7) # create a tensor of ones with dtype=float32
numpy_tensor = tensor.numpy() # will be dtype=float32 unless changed
tensor, numpy_tensor
(tensor([1., 1., 1., 1., 1., 1., 1.]), array([1., 1., 1., 1., 1., 1., 1.], dtype=float32))
同样地,遵循上述规则,如果你修改了原始的 tensor,新的 numpy_tensor 将保持不变。
# Change the tensor, keep the array the same
tensor = tensor + 1
tensor, numpy_tensor
(tensor([2., 2., 2., 2., 2., 2., 2.]), array([1., 1., 1., 1., 1., 1., 1.], dtype=float32))
可重复性(试图从随机中去除随机性)¶
随着你对神经网络和机器学习的了解加深,你会发现随机性在其中扮演了多么重要的角色。
嗯,确切地说是伪随机性。毕竟,从设计角度来看,计算机本质上是非随机的(每一步都是可预测的),所以它们产生的随机性是模拟出来的(尽管对此也有争议,但既然我不是计算机科学家,就让你自己去探索更多吧)。
那么,这与神经网络和深度学习有什么关系呢?
我们讨论过,神经网络从随机数开始来描述数据中的模式(这些随机数是糟糕的描述),并尝试使用张量操作(以及我们尚未讨论的其他一些方法)来改进这些随机数,以更好地描述数据中的模式。
简而言之:
从随机数开始 -> 张量操作 -> 尝试变得更好(一次又一次)
虽然随机性既美好又强大,但有时你希望随机性少一些。
为什么?
这样你就可以进行可重复的实验。
例如,你创建了一个能够达到X性能的算法。
然后你的朋友尝试验证你并没有发疯。
他们如何做到这一点?
这就是可重复性的作用。
换句话说,你能在你的计算机上运行相同的代码,得到与我一样的(或非常相似的)结果吗?
让我们看一个PyTorch中可重复性的简短示例。
我们将从创建两个随机张量开始,既然它们是随机的,你可能会期望它们是不同的,对吧?
import torch
# Create two random tensors
random_tensor_A = torch.rand(3, 4)
random_tensor_B = torch.rand(3, 4)
print(f"Tensor A:\n{random_tensor_A}\n")
print(f"Tensor B:\n{random_tensor_B}\n")
print(f"Does Tensor A equal Tensor B? (anywhere)")
random_tensor_A == random_tensor_B
Tensor A:
tensor([[0.8016, 0.3649, 0.6286, 0.9663],
[0.7687, 0.4566, 0.5745, 0.9200],
[0.3230, 0.8613, 0.0919, 0.3102]])
Tensor B:
tensor([[0.9536, 0.6002, 0.0351, 0.6826],
[0.3743, 0.5220, 0.1336, 0.9666],
[0.9754, 0.8474, 0.8988, 0.1105]])
Does Tensor A equal Tensor B? (anywhere)
tensor([[False, False, False, False],
[False, False, False, False],
[False, False, False, False]])
正如你可能预料的那样,这些张量的值各不相同。
但如果你想创建两个具有相同值的随机张量呢?
也就是说,张量仍然包含随机值,但它们的“风味”相同。
这时,torch.manual_seed(seed) 就派上用场了,其中 seed 是一个整数(比如 42,但可以是任何值),用于给随机性“调味”。
让我们尝试创建一些更具“风味”的随机张量。
import torch
import random
# # Set the random seed
RANDOM_SEED=42 # try changing this to different values and see what happens to the numbers below
torch.manual_seed(seed=RANDOM_SEED)
random_tensor_C = torch.rand(3, 4)
# Have to reset the seed every time a new rand() is called
# Without this, tensor_D would be different to tensor_C
torch.random.manual_seed(seed=RANDOM_SEED) # try commenting this line out and seeing what happens
random_tensor_D = torch.rand(3, 4)
print(f"Tensor C:\n{random_tensor_C}\n")
print(f"Tensor D:\n{random_tensor_D}\n")
print(f"Does Tensor C equal Tensor D? (anywhere)")
random_tensor_C == random_tensor_D
Tensor C:
tensor([[0.8823, 0.9150, 0.3829, 0.9593],
[0.3904, 0.6009, 0.2566, 0.7936],
[0.9408, 0.1332, 0.9346, 0.5936]])
Tensor D:
tensor([[0.8823, 0.9150, 0.3829, 0.9593],
[0.3904, 0.6009, 0.2566, 0.7936],
[0.9408, 0.1332, 0.9346, 0.5936]])
Does Tensor C equal Tensor D? (anywhere)
tensor([[True, True, True, True],
[True, True, True, True],
[True, True, True, True]])
太好了!
看起来设置种子起作用了。
资源: 我们刚刚涉及的内容只是 PyTorch 中可重复性的冰山一角。如果你想了解更多关于可重复性以及随机种子的知识,我建议查看以下资料:
- PyTorch 可重复性文档(一个好的练习是花 10 分钟阅读这个文档,即使你现在不理解它,但意识到它的存在是很重要的)。
- 维基百科随机种子页面(这将为你提供随机种子和伪随机性的一般概述)。
在GPU上运行张量(并加快计算速度)¶
深度学习算法需要大量的数值运算。
默认情况下,这些运算通常在CPU(中央处理单元)上进行。
然而,还有另一种常见的硬件——GPU(图形处理单元),它通常在执行神经网络所需特定类型的运算(矩阵乘法)方面比CPU快得多。
你的电脑可能就有一块GPU。
如果是这样,你应该尽可能地利用它来训练神经网络,因为它很可能会大幅缩短训练时间。
有几种方法可以首先获取GPU的访问权限,然后让PyTorch使用GPU。
注意: 在本课程中,当我提到“GPU”时,除非另有说明,我指的是启用了Nvidia GPU with CUDA(CUDA是一种计算平台和API,有助于使GPU能够用于通用计算,而不仅仅是图形处理)。
1. 获取GPU¶
当你听到GPU这个词时,你可能已经知道是怎么回事了。但如果你还不清楚,有几种方法可以获取GPU的使用权限。
| 方法 | 设置难度 | 优点 | 缺点 | 设置方法 |
|---|---|---|---|---|
| Google Colab | 简单 | 免费使用,几乎无需设置,可以轻松通过链接分享工作 | 不保存数据输出,计算资源有限,可能会超时 | 遵循Google Colab指南 |
| 使用自己的 | 中等 | 在本地机器上运行所有内容 | GPU不是免费的,需要前期成本 | 遵循PyTorch安装指南 |
| 云计算(AWS、GCP、Azure) | 中等至困难 | 前期成本小,几乎可以无限使用计算资源 | 如果持续运行可能会很昂贵,需要一些时间来正确设置 | 遵循PyTorch安装指南 |
还有更多使用GPU的选项,但上述三种方法目前足够使用。
就我个人而言,我结合使用Google Colab和自己的个人电脑进行小规模实验(以及创建这个课程),并在需要更多计算能力时转向云资源。
资源: 如果你想购买自己的GPU但不确定选择哪种,Tim Dettmers有一个很棒的指南。
要检查你是否可以访问Nvidia GPU,可以运行!nvidia-smi,其中!(也称为bang)表示“在命令行上运行此命令”。
!nvidia-smi
Sat Jan 21 08:34:23 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 515.48.07 Driver Version: 515.48.07 CUDA Version: 11.7 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA TITAN RTX On | 00000000:01:00.0 Off | N/A |
| 40% 30C P8 7W / 280W | 177MiB / 24576MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 1061 G /usr/lib/xorg/Xorg 53MiB |
| 0 N/A N/A 2671131 G /usr/lib/xorg/Xorg 97MiB |
| 0 N/A N/A 2671256 G /usr/bin/gnome-shell 9MiB |
+-----------------------------------------------------------------------------+
如果你没有可用的 Nvidia GPU,上述命令将输出类似以下内容:
NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running.
在这种情况下,请返回并按照安装步骤操作。
如果你确实有 GPU,上述命令将输出类似以下内容:
Wed Jan 19 22:09:08 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 495.46 Driver Version: 460.32.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla P100-PCIE... Off | 00000000:00:04.0 Off | 0 |
| N/A 35C P0 27W / 250W | 0MiB / 16280MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
2. 让 PyTorch 在 GPU 上运行¶
一旦你准备好了一个可访问的 GPU,下一步就是让 PyTorch 使用它来存储数据(张量)和处理数据(对张量执行操作)。
为此,你可以使用 torch.cuda 包。
与其谈论它,不如让我们尝试一下。
你可以使用 torch.cuda.is_available() 来测试 PyTorch 是否可以访问 GPU。
# Check for GPU
import torch
torch.cuda.is_available()
True
如果上述输出为 True,则表示 PyTorch 可以识别并使用 GPU;如果输出为 False,则表示 PyTorch 无法识别 GPU,此时你需要重新检查安装步骤。
现在,假设你希望设置代码,使其能够在 CPU 或可用 GPU 上运行。
这样一来,无论你或其他人使用何种计算设备运行你的代码,它都能正常工作。
让我们创建一个 device 变量来存储可用设备的类型。
# Set device type
device = "cuda" if torch.cuda.is_available() else "cpu"
device
'cuda'
如果上述输出为 "cuda",这意味着我们可以将所有 PyTorch 代码设置为使用可用的 CUDA 设备(即 GPU),而如果输出为 "cpu",则我们的 PyTorch 代码将继续使用 CPU。
注意: 在 PyTorch 中,编写设备无关的代码是最佳实践。这意味着代码将在 CPU(始终可用)或 GPU(如果可用)上运行。
如果你想进行更快的计算,可以使用 GPU,但如果你想进行更快的计算,可以使用多个 GPU。
你可以使用 torch.cuda.device_count() 来计算 PyTorch 可以访问的 GPU 数量。
# Count number of devices
torch.cuda.device_count()
1
了解PyTorch可以访问的GPU数量是有帮助的,以防你希望在一个GPU上运行某个进程,而在另一个GPU上运行另一个进程(PyTorch还具备让你在所有GPU上运行进程的功能)。
2.1 在苹果 M系芯片上运行 PyTorch¶
为了在苹果的 M1/M2/M3 GPU 上运行 PyTorch,可以使用 torch.backends.mps 模块。
请确保 macOS 和 PyTorch 的版本已更新。
你可以使用 torch.backends.mps.is_available() 来测试 PyTorch 是否可以访问 GPU。
# Check for Apple Silicon GPU
import torch
torch.backends.mps.is_available() # Note this will print false if you're not running on a Mac
True
# Set device type
device = "mps" if torch.backends.mps.is_available() else "cpu"
device
'mps'
如前所述,如果上述输出为 "mps",这意味着我们可以将所有 PyTorch 代码设置为使用可用的 Apple Silicon GPU。
if torch.cuda.is_available():
device = "cuda" # Use NVIDIA GPU (if available)
elif torch.backends.mps.is_available():
device = "mps" # Use Apple Silicon GPU (if available)
else:
device = "cpu" # Default to CPU if no GPU is available
3. 将张量(和模型)置于GPU上¶
你可以通过调用 to(device) 方法将张量(以及模型,我们稍后会看到这一点)置于特定的设备上。其中,device 是你希望张量(或模型)所要放置的目标设备。
为什么要这样做?
GPU 提供的数值计算速度远快于 CPU,并且如果 GPU 不可用,由于我们的 设备无关代码(见上文),它将运行在 CPU 上。
注意: 使用
to(device)方法将张量置于 GPU 上(例如some_tensor.to(device))会返回该张量的副本,即相同的张量将同时存在于 CPU 和 GPU 上。要覆盖张量,需要重新赋值:
some_tensor = some_tensor.to(device)
让我们尝试创建一个张量并将其置于 GPU 上(如果 GPU 可用)。
# Create tensor (default on CPU)
tensor = torch.tensor([1, 2, 3])
# Tensor not on GPU
print(tensor, tensor.device)
# Move tensor to GPU (if available)
tensor_on_gpu = tensor.to(device)
tensor_on_gpu
tensor([1, 2, 3]) cpu
tensor([1, 2, 3], device='mps:0')
如果你有可用的GPU,上述代码将输出类似以下内容:
tensor([1, 2, 3]) cpu
tensor([1, 2, 3], device='cuda:0')
注意第二个张量带有 device='cuda:0',这意味着它存储在可用的第0号GPU上(GPU的索引从0开始,如果有两个GPU可用,它们将分别是 'cuda:0' 和 'cuda:1',以此类推,最多到 'cuda:n')。
4. 将张量移回CPU¶
如果我们想将张量移回CPU,应该怎么做呢?
例如,如果你想使用NumPy与张量进行交互(NumPy不利用GPU),你可能需要这样做。
让我们尝试对我们的tensor_on_gpu使用torch.Tensor.numpy()方法。
# If tensor is on GPU, can't transform it to NumPy (this will error)
tensor_on_gpu.numpy()
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) /home/daniel/code/pytorch/pytorch-course/pytorch-deep-learning/00_pytorch_fundamentals.ipynb Cell 157 in <cell line: 2>() <a href='vscode-notebook-cell://ssh-remote%2B7b22686f73744e616d65223a22544954414e2d525458227d/home/daniel/code/pytorch/pytorch-course/pytorch-deep-learning/00_pytorch_fundamentals.ipynb#Y312sdnNjb2RlLXJlbW90ZQ%3D%3D?line=0'>1</a> # If tensor is on GPU, can't transform it to NumPy (this will error) ----> <a href='vscode-notebook-cell://ssh-remote%2B7b22686f73744e616d65223a22544954414e2d525458227d/home/daniel/code/pytorch/pytorch-course/pytorch-deep-learning/00_pytorch_fundamentals.ipynb#Y312sdnNjb2RlLXJlbW90ZQ%3D%3D?line=1'>2</a> tensor_on_gpu.numpy() TypeError: can't convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first.
相反,为了将张量返回到 CPU 并使其可与 NumPy 一起使用,我们可以使用 Tensor.cpu()。
这会将张量复制到 CPU 内存中,以便 CPU 可以使用它。
# Instead, copy the tensor back to cpu
tensor_back_on_cpu = tensor_on_gpu.cpu().numpy()
tensor_back_on_cpu
array([1, 2, 3])
上述操作返回的是位于CPU内存中的GPU张量副本,因此原始张量仍然保留在GPU上。
tensor_on_gpu
tensor([1, 2, 3], device='cuda:0')
练习¶
所有练习都旨在练习上述代码。
你应该能够通过参考每个部分或遵循所链接的资源来完成这些练习。
资源:
- 00练习模板笔记本。
- 00练习示例解决方案笔记本(在查看此内容之前尝试练习)。
- 文档阅读 - 深度学习(以及一般编程学习)的一个很大部分是熟悉你正在使用的某个框架的文档。在本课程的其余部分中,我们将大量使用PyTorch文档。因此,我建议你花10分钟阅读以下内容(如果你现在不明白某些内容也没关系,重点还不是完全理解,而是意识)。请参阅
torch.Tensor和torch.cuda的文档。 - 创建一个形状为
(7, 7)的随机张量。 - 对第2题中的张量与另一个形状为
(1, 7)的随机张量进行矩阵乘法(提示:你可能需要转置第二个张量)。 - 将随机种子设置为
0,然后重新做第2题和第3题。 - 说到随机种子,我们看到了如何用
torch.manual_seed()设置它,但有没有GPU的等效方法?(提示:你需要查阅torch.cuda的文档)。如果有,将GPU随机种子设置为1234。 - 创建两个形状为
(2, 3)的随机张量,并将它们都发送到GPU(你需要有GPU访问权限)。在创建张量时设置torch.manual_seed(1234)(这不一定是GPU随机种子)。 - 对第6题中创建的张量进行矩阵乘法(再次提醒,你可能需要调整其中一个张量的形状)。
- 找出第7题输出中的最大值和最小值。
- 找出第7题输出中的最大值和最小值的索引。
- 创建一个形状为
(1, 1, 1, 10)的随机张量,然后创建一个新的张量,移除所有1维度,留下形状为(10)的张量。设置种子为7,并打印出第一个张量及其形状以及第二个张量及其形状。
课外学习¶
- 花1小时浏览PyTorch基础教程(推荐阅读快速入门和张量部分)。
- 想了解更多关于张量如何表示数据的信息,请观看此视频:什么是张量?